[TOC]
RDB快照持久化
1
2
3
4
// RDB默认策略
save 900 1 # 900秒(15分钟)内至少有1个键被修改
save 300 10 # 300秒(5分钟)内至少有10个键被修改
save 60 10000 # 60秒(1分钟)内至少有10000个键被修改
RDB文件内容:
[魔数] → [版本号] → [可选元数据] → [数据库数据区] → [EOF 标记] → [校验和]
魔数(Magic Number): 文件类型标识
- 位置:文件最开头,占 5 字节
- 内容:固定为字符串 REDIS 的 ASCII 编码(对应字节:0x52 0x45 0x44 0x49 0x53)
- 作用:Redis 加载文件时,首先校验魔数,确认该文件是合法的 RDB 文件(避免加载非 RDB 格式的文件导致解析错误)
版本号(RDB Version): 文件格式版本标识
- 位置:魔数之后,占 4 字节
- 内容:无符号大端整数(Big-Endian),表示 RDB 文件的格式版本(例如版本 9 对应字节 0x00 0x00 0x00 0x09)
- 作用:不同版本的 RDB 文件可能在数据存储格式、元数据类型上有差异,Redis 依据版本号选择对应的解析逻辑(低版本 Redis 可能无法加载高版本 RDB 文件)
可选元数据(Optional Metadata): 文件辅助信息
- 位置:版本号之后,数据库数据区之前
- 内容:非必需部分,不同版本可能包含不同的元数据,常见内容包括
- Redis 服务器版本(如 6.2.6)
- RDB 文件创建时间戳(Unix 时间戳,记录快照生成时间)
- 快照生成时的 Redis 内存使用量
- 保留字段(用于后续扩展)
- 作用:主要用于调试和监控,帮助用户了解 RDB 文件的生成背景,不影响核心数据解析
数据库数据区(Database Data): 核心数据存储
这是 RDB 文件中体积最大的部分,存储 Redis 所有数据库(默认 16 个,编号 0-15)的键值对数据,以及数据库的相关配置(如过期键、数据库为空标记等)
EOF 标记: 数据区结束标识
- 位置:所有数据库数据存储完成后,占 1 字节
- 内容:固定为 0xFF
- 作用:明确告知解析器 “核心数据区已结束”,后续仅剩余校验和部分,避免解析时读取越界
校验和(Checksum): 文件完整性校验
- 位置:文件最后,占 8 字节
- 内容:无符号大端整数,是对 RDB 文件中 “魔数 → EOF 标记” 前所有字节数据的校验值(默认使用 CRC64 算法,部分版本可能调整)
- 作用:Redis 加载 RDB 文件时,会重新计算前面所有数据的校验值,与文件末尾的校验和对比: 若一致:文件未损坏,正常加载 若不一致:文件可能被篡改或传输过程中损坏,拒绝加载并抛出错误
save 命令:同步阻塞,拒绝所有请求
执行逻辑: save 由 Redis 主进程直接遍历内存中的所有键值对,序列化后写入 RDB 文件。整个过程中,主进程无法处理任何客户端的读写请求(包括 GET、SET 等),客户端会收到 “服务暂时不可用” 的响应(或超时)
阻塞时长: 取决于数据集大小,数据量越大(如 10GB 内存),阻塞时间越长(可能几秒到几分钟)
典型场景: 仅建议在 Redis 关闭前执行(SHUTDOWN 命令会自动触发 SAVE,确保数据落盘),生产环境中禁止在服务运行时使用(会导致业务中断)
bgsave 命令:异步非阻塞,主进程正常服务
执行逻辑: bgsave 由主进程调用 fork() 系统调用创建一个子进程,子进程负责生成 RDB 文件,主进程立即返回 “Background saving started” 并继续处理客户端命令
潜在阻塞点: 仅在 fork() 子进程的瞬间可能短暂阻塞主进程(时间取决于内存大小,大内存实例可能阻塞毫秒到秒级),之后主进程完全不受影响
COW 机制影响: 子进程生成快照期间,主进程修改的数据会触发 “写时复制”(COW)—— 被修改的内存页会被复制一份,子进程写入的是原内存数据,主进程修改的是新复制的内存页,两者互不干扰。但大量修改可能导致内存占用临时翻倍(需预留内存避免 OOM)
Redis 内部通过一个 “持久化状态标记”(server.bgsaveinprogress)确保 同一时间只有一个 RDB 快照操作(SAVE 或 BGSAVE)在执行
-
禁止同时执行两个 SAVE: 若已有一个 SAVE 在执行(主进程阻塞中),此时发送第二个 SAVE 命令,Redis 会直接拒绝,返回错误:”ERR Background save already in progress”
-
禁止同时执行两个 BGSAVE: 若已通过 BGSAVE 启动子进程生成快照,此时再发送 BGSAVE 命令,Redis 会拒绝,返回同上错误(避免多个子进程同时占用 CPU/IO 资源)
-
SAVE 与 BGSAVE 互斥: 互相拒绝
RDB文件生成过程
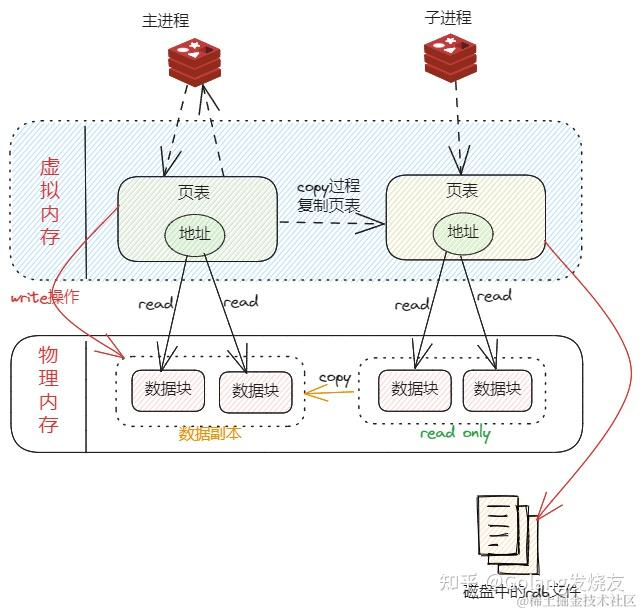
save是主进程操作,所以会阻塞新进来的读写操作,下面是bgsave的过程
1、主进程准备:fork 子进程
2、子进程生成 RDB 数据:遍历与序列化
3、主进程的并发处理:写时复制(COW)保障数据一致性
- 极端情况下,假如所有的内存都被修改,那么此时的内存占用是原先的 2 倍
4、子进程完成写入,原子替换目标文件
-
写临时文件,完成后,通过重命名覆盖旧的RDB文件
-
重命名完成后,子进程退出。操作系统会自动向其父进程(Redis 主进程)发送 SIGCHLD 信号(子进程状态改变的通知信号)。这一步是系统内核的默认行为,无需子进程主动调用发送信号的接口
5、主进程清理资源与更新状态
AOF持久化
1
2
3
always # 每次写命令后立即刷盘(调用 fsync)
everysec # 每秒刷盘一次(默认配置)
no # 由操作系统决定何时刷盘(通常依赖 OS 缓存,默认 30 秒左右)
- 命令追加(Append):记录写命令到缓冲区(AOF_BUF)
- 文件同步(Sync):缓冲区数据刷入磁盘
问题一:redis执行命令成功,但是在写AOF缓冲区的时候宕机
数据丢失
问题二:RDB文件bgsave,是fork子线程,AOF刷盘是由谁操作
AOF_BUF缓冲区的数据写入到 AOF 文件的操作,由主进程负责
- appendfsync always:强阻塞,完全阻塞读写请求
- 执行逻辑:主进程执行完写命令后,必须立即调用 fsync() 系统调用,将 AOF 缓冲区中该命令的数据强制刷入磁盘,且需等待磁盘 IO 完成(得到磁盘确认)后,才会返回客户端结果并处理下一个请求。
- 阻塞表现:fsync() 是同步磁盘 IO 操作(速度为毫秒级,远慢于内存操作),期间主进程会被完全阻塞 —— 不仅无法处理新的写请求,也无法处理读请求,客户端会面临响应延迟甚至超时。
- 核心原因:该策略追求 “理论零数据丢失”,通过强阻塞保证命令与磁盘写入的原子性,代价是牺牲主进程的并发处理能力
- appendfsync everysec(默认策略):弱阻塞,几乎不影响读写
- 执行逻辑:主进程仅负责将写命令追加到 AOF 缓冲区(内存操作,微秒级,无阻塞);同时启动一个独立的 后台线程(aof_fsync_thread),由线程每秒调用一次 fsync(),将缓冲区中积累的所有命令批量刷入磁盘。
- 阻塞表现:正常情况:主进程处理读写请求与后台线程执行 fsync() 并行,主进程无阻塞,服务响应不受影响;极端情况:若上一次 fsync() 未完成(如磁盘 IO 繁忙),下一次 fsync() 触发时,主进程可能会短暂阻塞(等待上一次 IO 完成),但阻塞时间通常极短(毫秒级),对业务影响可忽略。
- 核心原因:通过 “主进程处理命令 + 后台线程刷盘” 的分离设计,将磁盘 IO 开销转移到后台线程,最大化减少对主进程的阻塞
- appendfsync no:无阻塞,完全不影响读写
- 执行逻辑:主进程仅将 AOF 缓冲区的数据写入 操作系统内核缓冲区(内存操作,无阻塞),不主动调用 fsync();后续何时将内核缓冲区的数据刷入磁盘,完全由操作系统决定(通常依赖 OS 自身的缓存策略,如 30 秒一次)。
- 阻塞表现:主进程的操作仅限于 “内存到内核缓冲区”,全程无磁盘 IO 阻塞,可正常处理所有读写请求。
- 核心原因:放弃主动刷盘控制,将 IO 决策交给操作系统,以牺牲数据安全性为代价,换取主进程的极致性能
AOF重写
AOF量太大,数据的中间态是无用的。比如插入、删除 同一条数据1w次,最终库中没有这个数据,但是AOF记录了1w次命令,这些命令是无效的。
重写策略就是生成一个新的 AOF 文件来代替旧的 AOF 文件,这个操作在满足一定条件 Redis 会自动触发
1
2
3
4
5
# 当前 AOF 文件体积 比上次重写后的体积增长了 100%(即翻倍)时,满足增长条件
auto-aof-rewrite-percentage 100
# 当当前 AOF 文件体积 至少达到 64MB 时,满足最小体积条件(避免小文件频繁重写)
auto-aof-rewrite-min-size 64mb
Redis 内部会定期(每 100 毫秒)检查以下两个条件:
- 当前 AOF 文件体积 > 上次重写后的体积 × (1 + 百分比 / 100)(例如,上次重写后体积为 64MB,当前体积需 > 128MB 才满足 100% 增长);
- 当前 AOF 文件体积 ≥ auto-aof-rewrite-min-size(如 64MB)。
若同时满足,自动触发 BGREWRITEAOF 执行重写
特殊情况:若从未执行过重写(首次触发),“上次重写后的体积” 按 0 计算,此时只要当前体积 ≥ 最小体积,且增长百分比条件默认满足(0 的 100% 还是 0),即会触发首次重写
AOF 重写不依赖原 AOF 文件的内容,而是直接遍历 Redis 内存中的所有键值对,为每个键生成 “构建当前状态” 的最少命令。这避免了分析原 AOF 文件的复杂逻辑(原文件可能包含海量历史命令),且能保证生成的命令集绝对精简
AOF重写过程
1、主进程 fork 子进程
- 子进程继承主进程在 fork 时刻的 内存数据快照(通过写时复制 COW 机制共享内存,初始不复制实际数据)
2、子进程生成新 AOF 文件
-
创建临时文件:在 dir 配置的路径下创建临时文件(如 temp-rewriteaof-xxx.aof),避免直接覆盖原文件(防止重写失败导致文件损坏)
-
遍历内存数据:按数据库(0-15 号库)顺序遍历所有键值对,为每个键生成精简命令(如合并后的 SET、HSET 等)
-
写入临时文件:将生成的命令按 Redis 协议格式写入临时文件(与原 AOF 格式一致,保证兼容性)
3、主进程处理新命令(双缓冲区机制)
重写期间(子进程生成新文件的同时),主进程仍需处理客户端的新写命令,为避免这些命令丢失,主进程会将新命令 同时追加到两个缓冲区:
- AOF 缓冲区(AOF_BUF): 继续按 appendfsync 策略同步到 旧 AOF 文件(确保旧文件的连续性,若重写失败,旧文件仍可用于恢复);
- AOF 重写缓冲区(Rewrite Buffer): 专门暂存重写期间的新命令(子进程不知道这些命令,因为它基于 fork 时的快照工作)
4、主进程合并新命令 + 原子替换(重命名覆盖)
当子进程完成新 AOF 文件的生成后(所有内存快照的命令已写入临时文件)
- 子进程退出并发送信号:子进程执行 exit() 退出,操作系统向主进程发送 SIGCHLD 信号
- 主进程合并新命令:主进程收到信号后,将 AOF 重写缓冲区 中所有暂存的新命令(重写期间的命令)追加到临时新文件(确保新文件包含 “快照 + 重写期间的新命令”,数据完整)
- 原子替换旧文件:主进程调用 rename() 系统调用,将临时文件原子性重命名为原 AOF 文件名(如 appendonly.aof),覆盖旧文件
- 清理资源:主进程更新重写状态(如记录 aof_last_rewrite_time),释放重写缓冲区,重写完成
问题一:AOF重写的时候,怎么保证新来的指令最终一致
重写缓冲区(Rewrite Buffer),这就是为什么最后是由主进程收尾
问题二:AOF重写失败
重写过程中,旧 AOF 文件仍在被 AOF_BUF 同步(正常写入新命令),即使重写出错,旧文件也能保证数据不丢失。这也是为什么最后的收尾工作,是由主进程操作,并完成最后的文件重命名覆盖
主从同步
redis2.8版本变动较大,主要体现在 psync 命令
重要概念:复制偏移量、复制积压缓冲区、全量复制、增量复制
主从关系建立
1
2
3
1. 从节点发起连接:从节点启动后(或执行 SLAVEOF 命令后),会创建一个 复制客户端,向主节点发起 TCP 连接,主节点接受连接后,双方建立持久的 Socket 连接
2. 身份验证与权限确认:若主节点配置了密码(requirepass),从节点需通过 config set masterauth <password> 提供密码,验证通过后才能进入同步流程
首次同步(全量复制)
当从节点首次连接主节点,或从节点的数据与主节点差异过大(如断连后数据落后过多)时,会触发全量复制,将主节点的完整数据集同步到从节点。(这里断链后数据落后过多,和复制积压缓冲区有关)
1、从节点发送同步请求
- 从节点向主节点发送 PSYNC 命令(Redis 2.8+ 版本,替代旧版 SYNC 命令),请求同步。由于是首次同步,从节点的复制偏移量为 -1,主节点识别为 “全量复制请求”
2、主节点准备全量数据
-
主节点执行 BGSAVE 命令,fork 子进程生成 RDB 快照文件(核心数据快照)
-
生成 RDB 期间,主节点会将所有新收到的写命令(如 SET、HSET)存入 复制积压缓冲区(一个环形缓冲区,默认大小 1MB,可通过 repl-backlog-size 配置),避免这部分增量数据丢失
3、主节点发送 RDB 文件
-
子进程完成 RDB 生成后,主节点将 RDB 文件通过 Socket 发送给从节点
-
发送过程中,主节点继续接收新的写命令,仍存入复制积压缓冲区,确保数据不遗漏
4、从节点加载 RDB 文件
- 从节点接收 RDB 文件时,会先清空自身内存数据(避免旧数据干扰);
- 接收完成后,从节点将 RDB 文件反序列化,加载到内存中,重建主节点的数据集快照。
- 注意:加载期间从节点会阻塞,无法处理客户端读写请求(数据量越大,阻塞时间越长)
5、主节点同步积压的增量命令
- 从节点加载完 RDB 后,主节点会将复制积压缓冲区中存储的 “RDB 生成期间的写命令” 发送给从节点;从节点执行这些命令,使自身数据与主节点完全一致
6.同步完成:从节点进入只读状态
- 此时从节点数据与主节点同步,默认进入 只读模式(通过 replica-read-only yes 配置),仅响应读请求,不接受写请求(避免数据不一致)。
增量复制
全量复制完成后,主从节点进入增量复制阶段,主节点实时将写命令同步给从节点,维持数据一致性
1、主节点实时推送写命令
主节点执行任何写命令后,除了修改自身内存数据,还会立即将该命令发送给所有已连接的从节点(通过之前建立的复制连接)
2、从节点执行命令并更新偏移量
- 从节点接收主节点推送的写命令后,立即执行该命令,确保内存数据与主节点同步
- 主从节点各自维护一个 复制偏移量(64 位整数):
- 主节点发送一个命令后,偏移量 + 命令字节长度
- 从节点执行一个命令后,偏移量也同步增加
- 偏移量用于判断主从数据是否一致,是后续重连同步的关键依据
3、心跳机制维持连接
- 主从节点会通过心跳包确认对方状态
- 从节点每 1 秒向主节点发送 REPLCONF ACK
命令,包含自身当前的复制偏移量 主节点收到后,可通过偏移量判断从节点是否落后:若落后则推送缺失的命令;若超过复制积压缓冲区的范围,则触发全量复制 - 主节点若长时间未收到从节点的心跳(默认 60 秒),会断开复制连接
断连后同步
若从节点因网络故障等原因与主节点断连,重连后会根据数据落后情况选择同步方式
1、从节点发起重连请求
从节点重连主节点后,再次发送 PSYNC 命令,同时携带自身的复制偏移量(断连前的最后偏移量)
2、主节点判断同步方式
-
增量复制条件:主节点查看复制积压缓冲区,若从节点的偏移量对应的缺失命令仍在缓冲区中(未被覆盖),则主节点仅发送缺失的命令,从节点执行后同步,效率高
-
全量复制条件:若从节点的偏移量对应的命令已被缓冲区覆盖(如断连时间过长、写命令过多),主节点无法通过增量补充数据,会触发全量复制(重复首次同步流程)
核心注意事项
全量复制的开销:生成 RDB、传输文件、从节点加载均会消耗 CPU、内存和带宽,大内存实例全量复制可能导致服务延迟,建议避开业务高峰,且合理配置复制积压缓冲区大小;
从节点只读限制:默认从节点为只读模式,若需修改(如测试),需关闭 replica-read-only,但生产环境不建议,避免数据不一致;
主节点写命令传播:主节点采用 “推送模式” 传播写命令,确保实时性,但网络延迟可能导致短暂的主从数据不一致(最终一致性);
COW 机制的应用:主节点执行 BGSAVE 生成 RDB 时,依赖 COW 机制避免阻塞主进程,与 RDB 快照、AOF 重写的 COW 逻辑一致
问题:增量同步RDB,从节点怎么加载,会不会阻塞读操作
增量同步的核心是 “主节点发送缺失的写命令,从节点执行命令”,不涉及 RDB 文件,因此没有 “加载 RDB” 的步骤,但执行命令时可能短暂阻塞读操作
执行写命令,可能短暂阻塞读操作(通常无感知)