这篇笔记的目标,是把零散的 MySQL 知识点收束成一条主线:先理解 InnoDB 如何组织数据和索引,再理解查询为什么快或慢,最后把事务、锁、日志和主从复制串起来。
它偏向底层原理和工程判断,不展开执行计划字段逐项说明,也不覆盖具体业务 SQL 的专项调优案例。阅读时重点抓住四件事:数据怎么存、索引怎么查、并发怎么控、数据怎么保住。
参考资料:
InnoDB Locking and Transaction Model
[TOC]
1. 从 InnoDB 页开始理解 MySQL
MySQL 默认存储引擎是 InnoDB。很多查询、锁和事务现象,最终都要回到 InnoDB 的页结构来理解。
1.1 页是什么
InnoDB 以页(page)作为磁盘和缓存管理的基本单位,默认页大小是 16KB,也可以通过 innodb_page_size 调整为 4KB、8KB、32KB 或 64KB。
可以把页理解为 B+ 树节点在物理层面的主要载体。一个索引树的每个节点,通常就对应一个或多个页;Buffer Pool 里缓存的也是这些页。
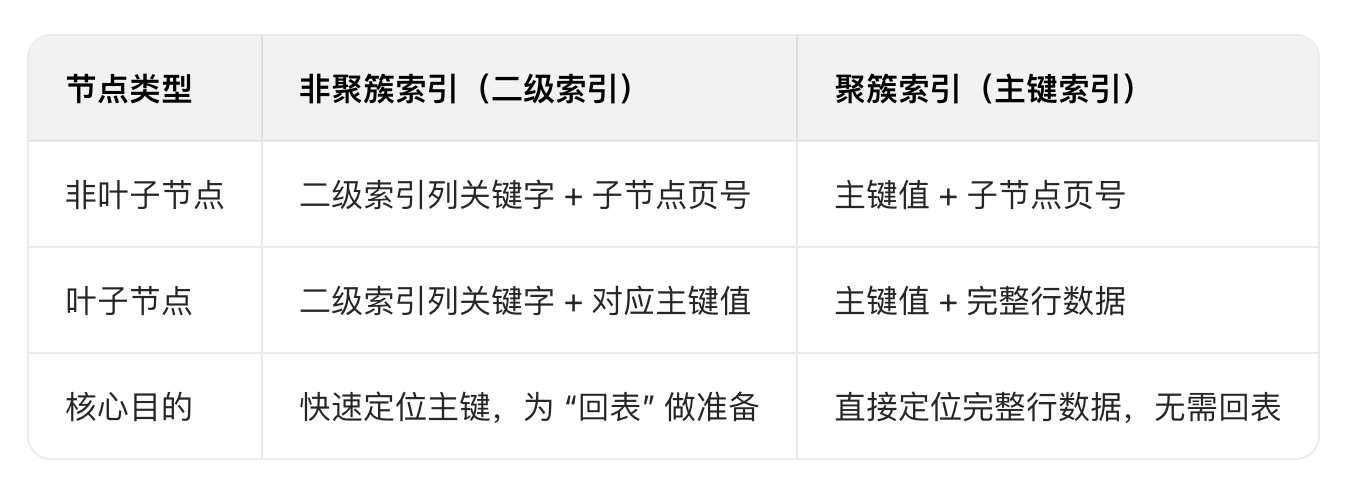
1.2 聚簇索引和二级索引分别存什么
在 InnoDB 中,表数据本身按主键组织,主键索引就是聚簇索引。
- 聚簇索引叶子节点存放完整行记录,核心是“索引即数据”。
- 二级索引叶子节点存放的是“二级索引列值 + 主键值”,不是直接保存行地址指针。
- 二级索引查到主键后,再回聚簇索引取完整行,这一步就是常说的回表。
这个细节很重要,因为它直接决定了为什么“二级索引查得快,但不一定一次查完”。
1.3 行很大时会发生什么
单行记录并不是要求必须完整塞进一个页里。对于很长的 BLOB、TEXT、较大的 VARCHAR 等列,InnoDB 会使用行溢出机制,把部分数据放到溢出页中,记录里保留指针信息。
需要注意两点:
- 常见资料会说“超过 8KB 就溢出”,这个说法只能当经验记忆,不能当绝对规则。
- 是否外部存储,受行格式、字段类型、页大小等因素共同影响;在
DYNAMIC、COMPRESSED行格式下,大字段更容易走外部存储。
2. 为什么索引底层更偏向 B+ 树
2.1 B 树和 B+ 树的关键差异
B 树和 B+ 树都属于多路平衡查找树,但 MySQL 的 InnoDB 选择 B+ 树作为主流索引结构,核心原因有两个:
- 非叶子节点只存键值和页指针,单页能容纳更多分支,树高更低。
- 真实数据集中在叶子节点,叶子节点之间还能串成有序链表,范围查询更友好。
B+ 树并不是“层级更高”,恰恰相反,在同样数据量下,它通常更容易降低树高。
2.2 为什么不用二叉树
二叉树每个节点最多两个分支,树高上升太快。数据库更在意随机 I/O 次数,而不是某一次比较多执行了几个 CPU 指令。
2.3 为什么不用 Hash
Hash 结构适合等值查找,但不适合下面这些数据库高频场景:
- 范围查询,如
>,<,BETWEEN - 前缀匹配,如
LIKE 'abc%' - 有序遍历,如
ORDER BY
所以数据库通用索引结构更倾向 B+ 树,而不是 Hash。
3. 索引设计要在建表阶段考虑
表结构一旦跑到线上,很多代价会被放大。字段类型、主键设计、索引顺序,都会持续影响 I/O 和锁范围。
3.1 字段长度尽量克制
字段越长,单页能容纳的记录越少,索引也会更胖,进而导致:
- B+ 树层级更容易增加
- Buffer Pool 命中率更差
- 范围扫描时 I/O 次数更多
因此,字段定义要按业务上限设计,而不是习惯性给很大长度。
3.2 主键要稳定、短小、尽量单调
InnoDB 的聚簇索引按主键组织数据,主键会被每个二级索引叶子节点一并保存。主键过长,所有二级索引都会跟着变大。
工程上通常会优先考虑:
- 短主键
- 不频繁更新的主键
- 尽量单调递增的主键
这也是很多业务表偏爱自增主键或趋势递增主键的原因之一。
3.3 怎么看索引区分度
可以用下面这条语句查看索引统计信息:
1
SHOW INDEX FROM table_name;
其中 Cardinality 表示索引基数,是优化器使用的估算值,可以近似理解为“索引列中不同值的数量”。
- 基数越高,通常区分度越好。
- 如果基数接近总行数,说明列值比较分散,更适合作为筛选条件。
- 如果大量记录都重复同一个值,这个索引即便存在,也未必值得优化器使用。
4. 深分页为什么慢
LIMIT offset, size 在偏移量很小时问题不大,但偏移量非常大时,成本会明显上升。
真正的问题不是“先把完整结果集全部查出来”,而是 MySQL 往往需要先扫描并跳过前面很多行,才能返回目标页的数据。如果排序列不能很好利用索引,还可能伴随 filesort、临时表或大量回表。
4.1 典型慢点在哪里
深分页常见慢点有三个:
- 扫描很多无用记录,只是为了跳过它们
- 排序无法利用索引,需要额外排序
- 先通过二级索引定位,再频繁回表取列
4.2 更稳妥的优化思路
第一类优化,是尽量让排序和过滤走到索引上。
第二类优化,是减少回表次数,例如只查需要的列,尽量利用覆盖索引。
第三类优化,是把“按页码翻页”改成“基于上次最后一个键继续查”的 seek 方法,也叫 keyset pagination。
1
2
3
4
5
SELECT id, title
FROM article
WHERE id > 1000000
ORDER BY id
LIMIT 20;
如果业务一定要保留页码语义,常见折中方案是:先用覆盖索引拿到目标页的主键,再回表补齐需要的列。
5. 联合索引、回表、ICP、MRR 要放在一起理解
5.1 联合索引的本质是先按前缀排序
联合索引 (A, B) 的逻辑顺序是:先按 A 排,再在 A 相同的记录里按 B 排。
因此,下面这条语句:
1
WHERE A > 2 AND B = 3
如果索引是 (A, B):
A > 2属于范围条件,优化器可以利用A定位到一段索引范围。- 但
B = 3往往不能继续用于“缩小定位范围”。 - 不过如果
B也在二级索引里,存储引擎仍可能借助 ICP 在索引层提前过滤掉不满足B = 3的记录。
如果索引是 (B, A):
B = 3先做等值定位。- 在
B = 3这一小段范围内,A仍然有序。 - 这时
A > 2可以继续利用索引范围过滤,通常更高效。
这就是“最左前缀原则”在工程上的真实含义:不是背口诀,而是看索引内部是否还能保持有序。
5.2 什么是回表
当查询使用二级索引,但目标列没有被这个索引完全覆盖时,MySQL 会先从二级索引叶子节点拿到主键,再回到聚簇索引读取整行。
这个过程就是回表。
常见优化方式:
- 只查需要的列,避免
SELECT * - 让常用查询尽量命中覆盖索引
- 高选择性条件优先走索引,减少无效回表
5.3 什么是索引下推
索引下推(ICP, Index Condition Pushdown)的核心思想是:把本来可以在存储引擎层判断的索引列条件,尽量提前到索引扫描阶段执行,而不是先回表、再到 Server 层过滤。
它不能改变联合索引的排序规则,但可以减少不必要的回表。
一个容易记住的判断是:
- “能不能继续缩小定位范围”看索引有序性。
- “能不能在回表前先过滤一部分”看 ICP 是否可用。
5.4 什么是 MRR
MRR(Multi-Range Read)主要用于改善二级索引范围扫描后的回表方式。
如果二级索引先拿到一批主键值,直接按拿到的顺序回聚簇索引,I/O 可能很随机。MRR 会把这些主键整理后,再按更接近顺序的方式回表,从而降低随机 I/O 开销。
它常和下面这类场景一起出现:
- 范围查询
- 二级索引扫描后大量回表
- 磁盘型负载或缓存命中不足的场景
6. 索引失效不要背死规则,要看“还能不能用索引做有序定位”
很多资料喜欢把“索引失效”整理成口诀,但更稳妥的理解方式是:优化器是否还愿意使用索引,以及索引还能利用到什么程度。
6.1 常见会削弱索引能力的写法
- 对索引列做函数或运算,如
WHERE a + 1 = 10 - 发生隐式类型转换,如字符串列拿数字去比较
LIKE '%abc'这种前导通配符- 联合索引没有满足最左前缀
- 选择性太差,优化器认为全表扫描更便宜
6.2 几个容易被说绝对化的点
1. OR 不等于一定失效
OR 条件两侧如果都能利用索引,优化器可能仍然会选索引合并或其他访问路径。只有当某一侧代价太高、无索引或整体成本不划算时,才更容易退化。
2. !=、<>、IS NOT NULL 也不是一定失效
这类条件常常选择性不高,所以优化器未必走索引,但并不代表语义上完全不能用索引。
3. UNION ALL 不保证原始顺序
UNION 会去重,UNION ALL 不去重,但二者默认都不保证最终输出顺序。只要业务依赖顺序,就应该在最外层显式写 ORDER BY。
6.3 做查询优化时,先看 EXPLAIN 的什么
很多优化并不是靠感觉判断,而是先看优化器准备怎么执行。EXPLAIN 不是答案本身,但它能帮助快速定位大方向。
最常看的几个字段可以这样理解:
type:访问方式,通常希望至少达到range、ref、eq_ref一类,而不是大范围ALLkey:最终实际使用了哪个索引,和possible_keys一起看更有意义rows:优化器估计要扫描多少行,数值越大,越值得警惕filtered:扫描后预计还能剩下多少比例的数据Extra:是否出现Using filesort、Using temporary、Using index、Using index condition等关键信号
工程上经常先问三件事:
- 有没有走到预期索引。
- 扫描行数是不是明显过大。
- 有没有排序、临时表、回表等额外成本。
6.4 覆盖索引、排序、分组为什么经常一起看
很多慢 SQL 不只是“过滤慢”,而是过滤之后的排序和分组没有借上索引。
覆盖索引
如果查询所需列全部包含在索引里,MySQL 就可以直接从索引返回结果,不必回表。
这类查询通常会更稳定,因为它同时减少了:
- 回表次数
- 随机 I/O
- Buffer Pool 压力
ORDER BY
ORDER BY 想走索引,通常要求过滤条件和排序列能匹配到同一条索引访问路径。如果过滤用了一套索引、排序又依赖另一套顺序,就很容易落到 filesort。
一个朴素判断是:如果查询本来就沿着某棵 B+ 树按需要的顺序往下扫,排序成本就低;如果先找到结果,再额外重排,成本就会上来。
GROUP BY
GROUP BY 和 ORDER BY 类似,也很依赖索引顺序。尤其是高基数字段做分组时,如果前置过滤不够好,临时表和额外排序都可能出现。
因此,很多“查询优化”本质上不是单纯补一个索引,而是同时考虑:
- 过滤列
- 排序列
- 分组列
- 返回列
6.5 JOIN 优化要先控制驱动表和扫描量
JOIN 慢,很多时候不是连接本身复杂,而是前面某一张表已经扫太多行了。
做 JOIN 优化时,通常优先关注:
- 让过滤后结果更小的表尽早参与连接
- 给
JOIN条件列建立合适索引 - 避免在连接列上做函数、计算或隐式类型转换
- 减少大结果集之后再排序、分组、分页
如果一条 SQL 最终要关联多张表,一个非常实用的思路是:先想办法把“参与连接的数据量”降下来,再谈后面的连接算法和排序成本。
7. 当前读、快照读、Undo Log、MVCC
这一部分是把旧笔记里的内容合并并校正后的版本。
7.1 什么是快照读
在 InnoDB 中,普通 SELECT 在大多数隔离级别下属于一致性非锁定读,也叫快照读。
它的特点是:
- 读取的是某个一致性视图下可见的数据版本
- 不会像锁定读那样默认给记录加锁
- 读写可以并发进行
需要特别纠正一个常见误区:普通 SELECT 不是默认加共享锁。只有 SERIALIZABLE 隔离级别,或者显式使用锁定读语法时,才会引入相应锁行为。
7.2 什么是当前读
当前读可以理解为“读取记录的当前最新版本,并且需要考虑锁冲突”。典型语句包括:
SELECT ... FOR UPDATESELECT ... FOR SHAREUPDATEDELETE
这类语句不仅要读数据,还要参与并发控制,因此通常会加记录锁、间隙锁或临键锁,具体取决于索引条件和隔离级别。
7.3 Undo Log 在这里扮演什么角色
Undo Log 有两个核心作用:
- 事务回滚
- 给 MVCC 提供旧版本数据
当记录被修改时,InnoDB 会保留旧版本信息。快照读如果发现当前版本对自己不可见,就会沿着版本链去找一个自己可见的旧版本。
所以更准确的说法不是“快照读每次都在读 undo log”,而是:
- 能直接读到可见版本时,就直接读当前记录版本。
- 当前版本不可见时,才会顺着 undo 版本链回溯。
7.4 Read View 是什么
Read View 可以理解为“当前事务看世界的可见性规则”。
它不保存整张表的拷贝,而是保存事务可见性判断所需的信息。借助它,InnoDB 才能判断某个版本对当前事务是否可见。
7.5 RC 和 RR 下 Read View 的差异
Read Committed
每条快照读语句通常都会生成新的 Read View,所以同一个事务里两次普通查询,可能看到不同的提交结果。
Repeatable Read
同一事务中的第一次快照读会建立 Read View,后续快照读通常复用它,因此普通查询结果可重复。
这也是 MySQL 默认隔离级别选择 Repeatable Read 后,很多业务读起来“更稳定”的原因。
8. 四种隔离级别要和读写方式一起看
8.1 Read Uncommitted
- 可能读到其他事务尚未提交的数据
- 会出现脏读
- 在工程实践中几乎很少作为默认选择
8.2 Read Committed
- 只能看到已提交数据
- 可以避免脏读
- 同一事务内重复执行普通查询,可能出现不可重复读
- 范围读也可能出现幻读
8.3 Repeatable Read
这是 InnoDB 默认隔离级别。
- 普通快照读在同一事务内通常可重复
- 锁定读、更新、删除等当前读场景,会配合记录锁、间隙锁、临键锁控制并发
- 讨论“幻读”时一定要区分快照读和当前读,不要把所有现象混成一句口号
更贴近实现的说法是:
- 对普通快照读,RR 主要依赖 MVCC 保证可重复读。
- 对锁定读和范围修改,RR 主要依赖 Next-Key Lock 来降低幻读风险。
8.4 Serializable
最严格的隔离级别,读写冲突最多,并发性最低。只有在业务确实需要强串行语义时才值得考虑。
9. MySQL 锁的重点不是名字,而是“锁住了哪一段索引”
InnoDB 的行锁本质上锁的是索引记录,而不是抽象意义上的“这一行”。
9.1 常见三类锁
Record Lock
锁住具体索引记录。
Gap Lock
锁住索引记录之间的间隙,不包含记录本身,主要用于阻止新的插入。
Next-Key Lock
Record Lock + Gap Lock 的组合,是 InnoDB 在 Repeatable Read 下处理范围并发的重要手段。
9.2 为什么说“没索引会锁很多”
如果语句没有合适索引,MySQL 可能只能扫描大量记录,扫描到哪里就锁到哪里。结果是:
- 锁范围变大
- 并发下降
- 死锁概率上升
所以“建好索引”不仅是为了查询性能,也是为了缩小锁范围。
9.3 唯一索引上的精确命中更容易退化成记录锁
如果使用唯一索引做等值定位,并且精确命中唯一记录,InnoDB 往往只需要加记录锁,不需要把前后间隙一起锁住。
这也是唯一索引在并发控制上经常更干净的原因。
9.4 死锁并不罕见,关键是缩短锁持有时间
只要有并发更新、交叉访问和多条语句组成的事务,死锁就可能出现。死锁不是“数据库坏了”,而是数据库在帮忙做冲突裁决。
更值得关注的是如何降低死锁概率:
- 事务尽量短,避免长事务占着锁不提交
- 多个事务按一致顺序访问对象,例如都先改表 A 再改表 B
- 尽量让条件命中索引,减少“扫描到哪里锁到哪里”
- 把用户交互、远程调用放在事务外,避免锁跨网络等待
排查时通常先看最近一次死锁信息,再回到 SQL 和索引层面找“锁范围为什么会重叠得这么大”。
10. 插入为什么会碰到自增锁问题
自增主键看起来只是“生成一个新 ID”,但在高并发插入时,背后其实同时有两类问题:
- 自增值怎么分配,才能保证并发下不重复
- 事务提交后,变更怎么可靠持久化
这两类问题经常一起出现,但不要混成一件事。
10.1 自增 ID 不重复,不等于“数据安全”
AUTO_INCREMENT 主要解决的是“并发插入时,谁拿到哪个新 ID”。
它能说明 MySQL 在分配自增值时做了并发控制,但不能直接说明数据已经安全落盘。真正和“数据是否保住”相关的,是事务提交时:
redo log是否按配置写入或刷盘binlog是否按配置写入并与事务提交保持一致- 崩溃发生时,事务到底处于已提交还是未提交状态
所以要区分两件事:
- 自增 ID 不重复,说明分配过程受控
- 事务提交成功并完成相应持久化,才说明这次写入真正“保住了”
一个非常容易混淆的现象是:ID 已经分配出去,但最终那行数据并没有留下来。例如插入失败、事务回滚、批量插入预留后未全部使用,这些都会造成自增值出现间洞,而且这些值通常不会被重用。
10.2 锁住的更准确说法,是“保护自增计数器的分配过程”
讨论自增锁时,更准确的说法不是“锁住了这几行数据”,而是 InnoDB 需要保护 AUTO_INCREMENT 计数器的分配过程。
在不同模式下,这种保护可能体现为:
- 特殊的表级
AUTO-INC锁 - 更轻量的互斥量(mutex)
这里还有一个很重要的细节:AUTO-INC 锁通常是持有到语句结束,不是持有到事务结束。也就是说,它和普通行锁的观察方式不完全一样,但在并发插入同一张表时,仍然会直接影响吞吐量。
10.3 为什么它会变成性能问题
如果每次插入都要严格串行地分配自增值,那么并发线程越多,等待就越明显。
因此,高并发插入的成本,往往来自两个方向:
- 前半段是“分配自增值时的竞争”,表现为
AUTO-INC锁等待或互斥量竞争 - 后半段是“事务提交时的持久化成本”,表现为
redo log刷盘、binlog同步等开销
这也是为什么同样是“插入很慢”,有时瓶颈在锁竞争,有时瓶颈在提交刷盘,二者不能混为一谈。
10.4 innodb_autoinc_lock_mode 决定了并发插入的取舍
MySQL/InnoDB 通过 innodb_autoinc_lock_mode 控制自增值的分配方式。它不是单纯的“开锁或不开锁”,而是要在连续性、并发度、复制安全性之间做权衡。
0:traditional
这是最传统的方式,所有 INSERT-like 语句都会拿表级 AUTO-INC 锁,并通常持有到语句结束。
- 优点是行为最接近早期版本,结果更可预测
- 缺点是并发插入更容易串行化,吞吐量最差
- 它适合强调可重复执行语义、兼容旧行为的场景
1:consecutive
这是一个折中模式,可以把你说的“已知插入量就预分配,不知道就沿用旧策略”更准确地表述出来。
- 对于
INSERT ... VALUES (...)这类事先能知道要插多少行的 simple insert,InnoDB 会在互斥量保护下,一次申请所需数量的自增值,申请完成后很快释放,不必整条语句都持有表级AUTO-INC锁 - 对于
INSERT ... SELECT、LOAD DATA这类事先不知道会插多少行的 bulk insert,仍然会使用表级AUTO-INC锁,并在语句执行过程中逐步分配自增值
因此,这一模式兼顾了两件事:
- simple insert 的并发性能明显更好
- 语句级别的自增值仍然更容易保持连续,适合 statement-based replication
2:interleaved
这是更激进的并发模式,也是 MySQL 8.x 默认更偏好的方向。它不再对 INSERT-like 语句使用表级 AUTO-INC 锁,而是统一走更轻量的分配控制。
- 优点是并发度最高,多个插入语句可以同时推进
- 代价是不同语句之间拿号会交错,同一条语句拿到的自增值也可能出现间洞
- 它保证的是“唯一且总体递增”,不是“绝对连续”
这里要特别纠正一句容易说过头的话:它影响的不是所有主从同步,而是 statement-based replication 下的确定性。
- 如果使用 statement-based replication,
innodb_autoinc_lock_mode=2可能让主库和从库在重放 SQL 时分配出不同的自增值 - 如果使用 row-based replication 或 mixed format,这个问题通常就是可控的,这也是为什么新版本默认更敢采用更高并发的模式
10.5 工程上真正该记住什么
这部分最后可以压缩成几条判断:
- 自增锁的核心不是“锁行”,而是“保护自增计数器分配”。
- 自增 ID 不重复,不等于事务已经安全持久化到磁盘。
- 所谓“新版本用互斥量、老策略用表级锁”的说法,核心要落实到
innodb_autoinc_lock_mode以及语句类型上。 - 已知插入量的 simple insert 更容易做批量申请;未知插入量的 bulk insert 更容易退回到保守策略。
- 自增值不连续并不一定是异常,回滚、失败、批量预留未用完,都可能造成间洞。
- 真要排查“大并发插入为什么慢”,通常要同时看自增锁模式、语句形态、
innodb_flush_log_at_trx_commit、sync_binlog和复制格式。
11. 日志系统要分清 binlog、redo log、undo log
11.1 binlog
如果先用一句最通俗的话来记:
binlog更像 MySQL Server 记下的“对外变更流水”
它是 Server 层的二进制日志,记录的是数据变更事件,主要用于:
- 主从复制
- 按时间点恢复(PITR)
- 审计和回放分析
它不是“只记录 SQL 原文”。在不同 binlog_format 下,binlog 可能记录:
- SQL 语句本身
- 行级变更结果
- 或二者混合
所以理解 binlog 的重点不是“它长什么样”,而是:
- 它站在 MySQL Server 的视角记录“这次事务对外做了什么变更”
- 后续主从复制、时间点恢复,主要都依赖它
11.2 redo log
如果也用一句最通俗的话来记:
redo log更像 InnoDB 记下的“内部施工日志”
redo log 是 InnoDB 层的预写日志(WAL),核心作用是保证崩溃恢复能力。
为什么需要它?
因为数据库真正的数据页,不会在每次事务提交时都立刻刷回磁盘。否则每次修改一行都要直接改磁盘上的页,随机 I/O 太重,性能会很差。
所以 InnoDB 的思路是:
- 先在内存里的 Buffer Pool 修改数据页
- 同时把这次修改对应的 redo 信息记下来
- 事务提交时,优先保证 redo log 按策略落到安全位置
- 真实数据页之后再慢慢刷盘
这就是 WAL 的核心思想:先记日志,再慢慢写数据页。
理解 redo log 时要抓住两件事:
- 事务提交时,首先要保证对应 redo 已经按策略写入或刷新到安全位置
- 真正的数据页可以稍后再刷回表空间文件
因此,更准确的说法是:
- redo log 负责“先把这次物理修改保住”
- 不是“等数据页真的刷盘后事务才算提交”
如果数据库突然宕机,重启后 InnoDB 就可以根据 redo log,把那些“已经提交但数据页还没来得及刷盘”的修改重新补上。
关于 innodb_flush_log_at_trx_commit,常见记忆如下:
1:每次提交都把 redo 刷到磁盘,持久性最强,也是默认配置2:每次提交写到操作系统缓存,通常每秒再刷盘一次0:提交时不主动刷,通常每秒统一处理一次,性能更高但风险也更大
11.3 undo log
undo log 一方面为事务回滚服务,另一方面为 MVCC 提供历史版本链。
可以把它理解成“并发可见性”和“失败可撤销”共用的一套基础设施。
11.4 binlog 和 redo log 为什么要一起看
很多人第一次学到这里时会困惑:
- 既然有 redo log,为什么还需要 binlog?
- 既然有 binlog,为什么还需要 redo log?
最根本的原因是:它们解决的不是同一个问题。
可以先用一个非常粗糙但好记的类比:
redo log像饭店后厨自己的“备餐记录”,重点是后厨断电后还能接着做binlog像饭店给总店留的“出单流水”,重点是别的门店和审计系统也能知道今天卖了什么
也可以直接记成下面这张对比表:
| 维度 | redo log | binlog |
|---|---|---|
| 所属层次 | InnoDB 存储引擎层 | MySQL Server 层 |
| 记录内容 | 更偏底层的页修改信息 | 更偏逻辑层的变更事件 |
| 主要作用 | 崩溃恢复、保证持久性 | 主从复制、时间点恢复 |
| 写入时机 | 事务执行过程中持续产生,提交时按策略刷出 | 事务提交时写入 |
| 是否循环覆盖 | 通常循环写 | 通常顺序追加写 |
| 能否替代对方 | 不能 | 不能 |
把这张表翻成白话,就是:
redo log主要回答“这次提交,机器突然掉电后,InnoDB 能不能把数据补回来”binlog主要回答“这次提交,别的副本能不能知道、以后能不能按时间点把它重放出来”
再举一个更直观的例子。
假设你执行了:
1
UPDATE account SET balance = balance - 100 WHERE id = 1;
这次事务提交时,大致可以这样理解:
- InnoDB 会生成 redo log,表示某些数据页被怎样修改过
- MySQL Server 会生成 binlog,表示这次事务产生了什么变更事件
二者看的是同一件事,但视角不同:
- redo log 更像“页 1234 的某个位置从什么变成什么”
- binlog 更像“
account表里哪一行发生了怎样的业务变更”
所以:
- 只靠 redo log,主从复制很难直接做,因为它太偏 InnoDB 内部实现
- 只靠 binlog,崩溃恢复又不够高效,因为它不是给 InnoDB 做页级恢复设计的
业务提交事务时,MySQL 既要保证 InnoDB 自己能在崩溃后恢复,也要保证复制和时间点恢复所依赖的 binlog 不丢语义。
这就是为什么工程上经常把 redo log 和 binlog 放在一起讲:两者分别属于不同层,但提交时必须保持一致。
可以先抓住高层逻辑:
redo log负责把存储引擎内的数据变更“保住”binlog负责把 Server 层的变更事件“记下来”- 两阶段提交机制负责尽量避免“只有一边成功、另一边缺失”的不一致
如果你只想记一句话,可以记成:
redo log是给 自己崩溃恢复 用的binlog是给 复制和恢复链路 用的
如果只理解单个日志,很容易解释不清主从复制、崩溃恢复和事务提交之间为什么能衔接起来。
12. 主从复制先看链路,再看一致性等级
12.1 主从同步的数据流向
经典异步复制链路可以概括为:
主库提交事务 -> 写入 binlog -> 复制线程把 binlog 发送给从库 -> 从库写入 relay log -> 从库回放事件 -> 数据追平
12.2 三种常见 binlog 格式
statement
记录 SQL 语句本身。
优点是日志更小;缺点是某些非确定性函数、依赖上下文的语句,更容易带来主从不一致风险。
row
记录行级变更。
优点是一致性最好;缺点是日志体积通常更大。
mixed
在 statement 和 row 之间折中,由 MySQL 视情况切换。
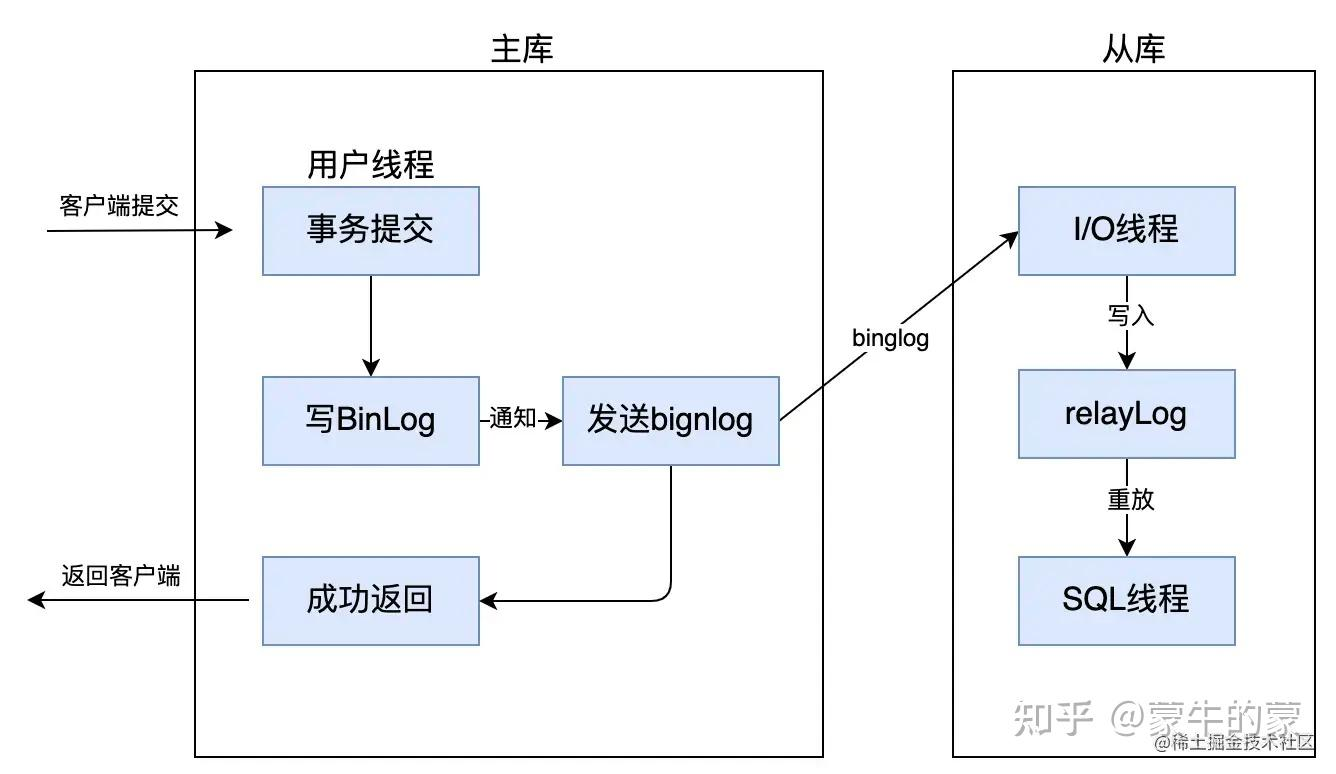
12.3 异步复制和半同步复制差在哪
异步复制
主库提交后即可向客户端返回成功,不等从库确认。
优点是延迟低;缺点是主库故障时,最近已提交事务可能还没传到任何从库。
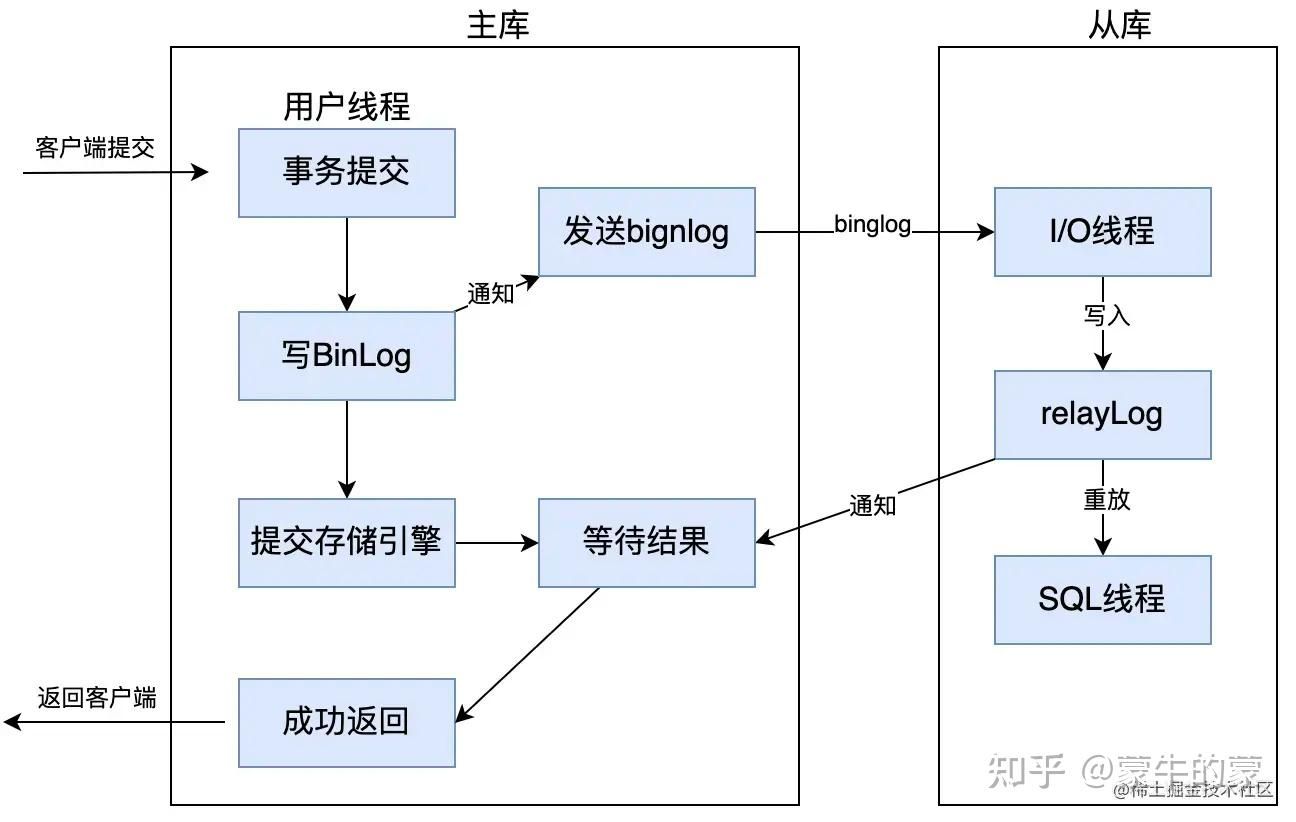
半同步复制
主库会等待至少一个从库确认“已经收到并记录了事务事件”,再返回成功。
这里最容易写错的一点是:半同步复制等待的是从库收到并写入日志的确认,不是等待从库已经执行完事务。
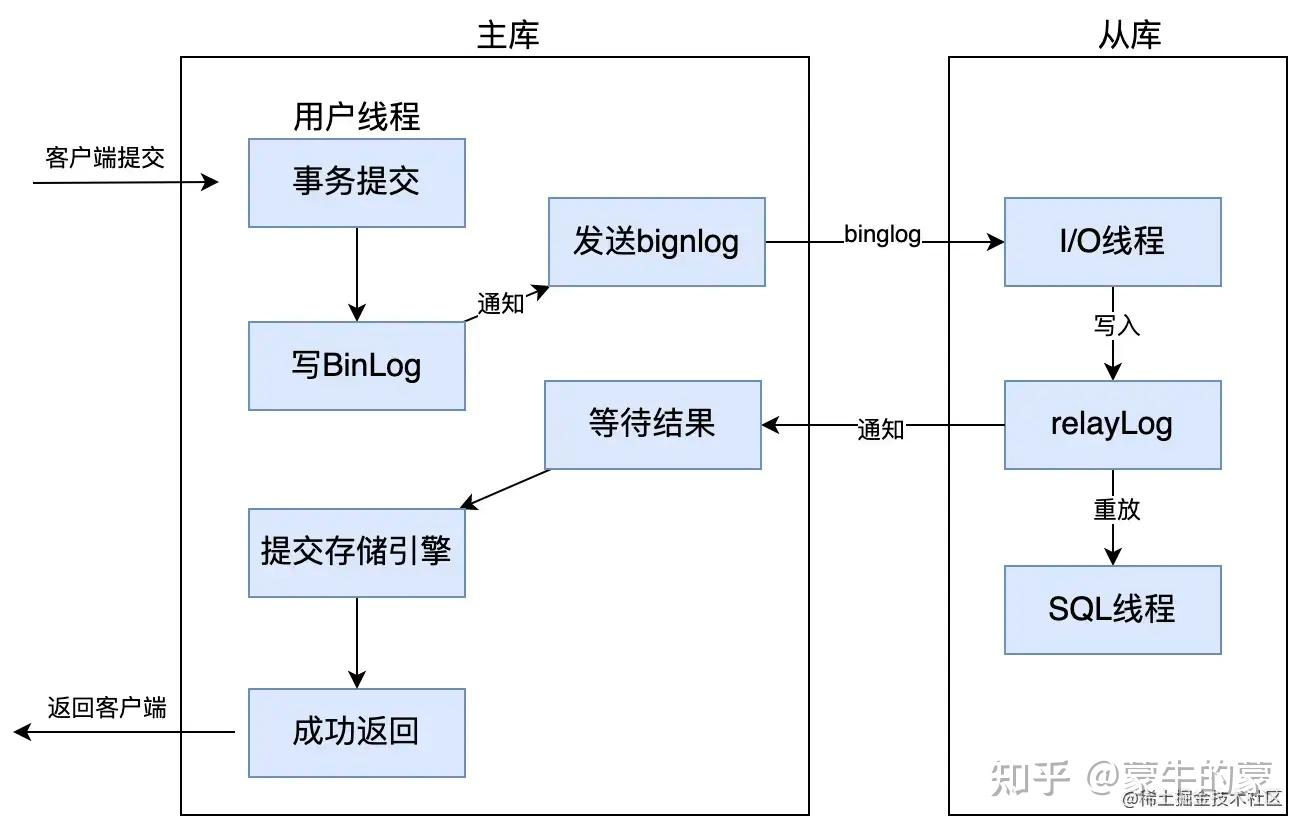
12.4 AFTER_SYNC 和 AFTER_COMMIT 的区别
MySQL 半同步复制还可以配置等待点:
AFTER_COMMIT:主库先提交到存储引擎,再等从库确认AFTER_SYNC:主库先写并同步 binlog,等从库确认后,再提交到存储引擎
工程上更常提到的是 AFTER_SYNC,因为它能进一步缩小故障切换时的事务丢失窗口。它解决的是复制确认时机问题,不是事务隔离里的“幻读”问题。
12.5 再看一眼几种复制确认时机
如果只是记概念,异步复制和半同步复制已经够用了;但如果是为了复习和面试,最好再把“增强半同步”和“全同步”也放到同一张脑图里。
增强半同步复制 可以理解成在半同步复制基础上,进一步优化确认时机和事务丢失窗口控制的实现思路。它不是另一个完全独立的复制体系,而是对半同步复制行为的强化理解。
全同步复制 可以把它当成帮助理解一致性代价的对照概念:主库必须等所有副本都确认完成,才能向客户端返回成功。它能提供更强的一致性直觉,但延迟和可用性成本通常也最高,因此工程上并不是 MySQL 常规主流方案。
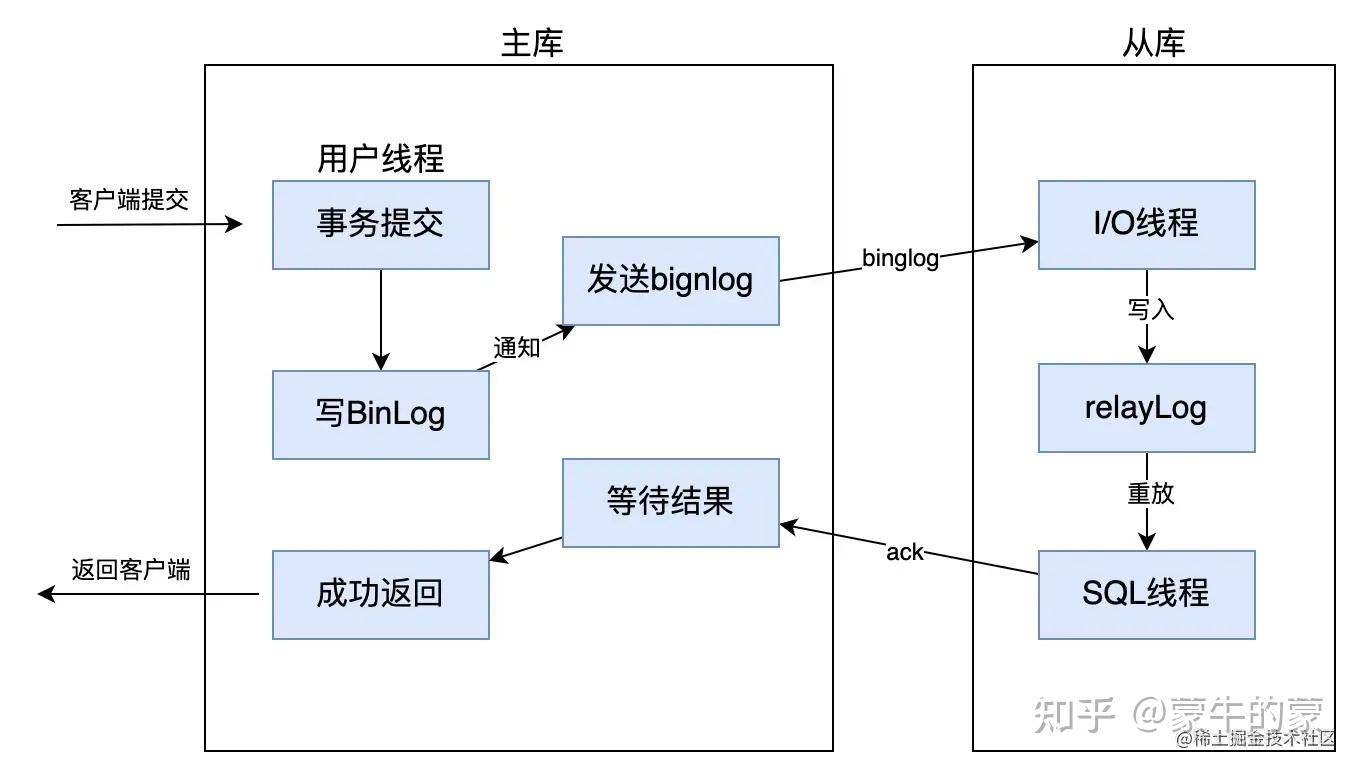
12.6 新从库怎么追主库
如果是传统方式初始化新从库,思路通常是:
- 在主库做一致性备份
- 把备份恢复到从库
- 让从库从备份时刻对应的 binlog 位点或 GTID 开始追
使用 mysqldump 时,下面这个组合比较常见:
1
mysqldump -u root -p --all-databases --single-transaction --master-data=2 > /tmp/master_data.sql
参数含义:
--single-transaction:对 InnoDB 表做一致性快照备份,尽量减少锁表影响--master-data=2:把备份时的 binlog 位点写进导出文件注释中,便于后续建立复制
如果环境已经全面使用 GTID,后续通常会配合自动定位能力,而不是手工维护文件位点。
12.7 GTID 的工程价值是什么
GTID 可以把“这个事务是谁、执行到哪里了”变成全局唯一标识,而不是只靠文件名和位点去追进度。
它的直接收益主要有三类:
- 主从切换时更容易定位复制进度
- 新从库追主库时更容易自动补齐缺失事务
- 故障恢复和拓扑调整时,人工判断成本更低
所以在现代部署里,GTID 更像是“复制管理能力”的基础设施,而不只是一个额外参数。
12.8 读写分离为什么容易让业务读到旧数据
很多业务把主库负责写、从库负责读,但一旦从库存在复制延迟,就可能出现“刚写完立刻去读,却读不到最新值”的现象。
这类问题本质上不是 SQL 写错,而是副本追平存在时间差。
常见应对方式包括:
- 写后短时间内强制读主库
- 关键链路不做读写分离
- 通过半同步复制、监控复制延迟等方式缩小风险窗口
- 业务端显式设计“读己之写”策略
因此,复制的核心问题从来不只是“能不能同步”,还包括“业务能不能接受这段延迟”。
13. UNION 和 UNION ALL 的真正区别
13.1 语义区别
UNION:合并结果并去重,等价于UNION DISTINCTUNION ALL:合并结果但不去重
13.2 性能差异
UNION 需要去重,通常比 UNION ALL 成本更高。
13.3 顺序问题
默认情况下,UNION 和 UNION ALL 的最终结果都不保证顺序。即便某次看起来像“按书写顺序返回”,那也不应该被当成稳定语义。
如果业务依赖顺序,必须在最外层写 ORDER BY:
1
2
3
4
SELECT id, name FROM t1
UNION ALL
SELECT id, name FROM t2
ORDER BY id;
14. 最后把整篇内容压缩成几条判断
如果只想带走最重要的判断,可以记住下面几条:
- InnoDB 里真正决定查询和锁范围的,往往不是“表”,而是“索引页和索引范围”。
- 二级索引叶子节点存的是主键,不是行地址,所以回表是常态,不是特例。
- 联合索引能不能继续利用,关键看前面列是否还保持有序,而不是只背“范围后失效”。
- 普通
SELECT默认是快照读,不是默认加共享锁。 - MVCC 解决的是读写并发可见性问题;锁解决的是当前读和写写冲突问题。
- redo log 负责崩溃恢复,binlog 负责复制和时间点恢复,undo log 负责回滚与历史版本。
- 半同步复制等待的是从库“收到并落日志”的确认,不是等待从库“执行完成”。
UNION ALL只是不过滤重复,不代表天然保序。