[TOC]
双重检锁
双重检锁,不是加2次锁,而是2次判空。可以是一种缓存穿透的解决方案
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
public String getData(String key) {
String value = stringRedisTemplate.opsForValue().get(CACHE_KEY + key);
// 第一次缓存判空
// 问题在于,并发情况下,大量请求通过了此次判空,进入到了下面的逻辑,准备查询DB
if (value != null) {
return value;
}
// 获取分布式锁
RLock lock = redissonClient.getLock(LOCK_KEY + key);
lock.lock(10, TimeUnit.SECONDS); // 设置锁的超时时间
try {
// 第二次缓存判空。这是双重检锁的关键,防止上一步并发的大量请求,直查DB
value = stringRedisTemplate.opsForValue().get(CACHE_KEY + key);
if (value != null) {
return value;
}
// 缓存中不存在数据,请求数据库
value = loadDataFromDatabase(key);
// 更新缓存
stringRedisTemplate.opsForValue().set(CACHE_KEY + key, value, 10, TimeUnit.MINUTES);
} finally {
// 释放锁
lock.unlock();
}
return value;
}
mysql执行顺序
join连接
on 后面跟的 and 条件,执行:先根据 and 条件 where 筛选非驱动表,再执行 on 关联。所以如果 and 后面的条件是驱动表条件,sql是不生效的
顺序
from > on > where > group by > having > select > order by > limit
每个子句执行后都会产生一个中间结果,供接下来的子句使用
最左匹配原则(补充 索引下推、mrr 优化)
最左匹配原则,主要针对联合索引。innodb的索引底层结构为B+树,最下层叶子节点为有序链表,且只能根据一个值来构建,因此数据库依据联合索引最左的字段构建B+树
从叶子节点数据顺序来看(a,b 字段):1、a是有序的 2、a确定的情况下,b是有序的
所以:a = 1 and b = 2,ab都可以使用索引; a > 1 and b = 2,a索引,b不走索引
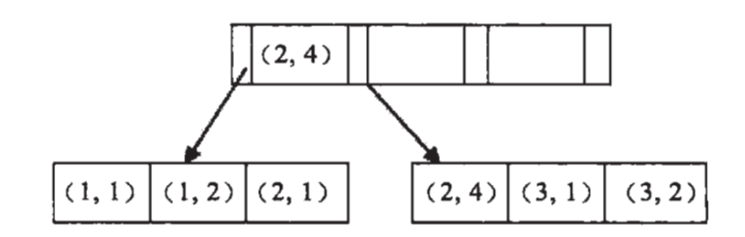
索引下推(Index Condition Pushdown)
一种根据索引进行查询的优化方式。在 Mysql5.6 之前,进行索引查询时,先在索引树上查询出结果集,然后再根据where条件过滤需要的结果。在 Index Condition Pushdown 出现后,mysql 在取出索引的同时,判断是否可以进行 where 条件的过滤,也就是将where的部分过滤放在了存储引擎层。在某些情况下,可以大大减少上层sql层对记录的索取,从而提高数据库的整体性能
支持 range、ref、eq_ref、ref_or_null类型的查询,支持MyISAM 和 InnoDB 存储引擎
MRR(Multi-Range Read)
Mysql5.6以后开始支持 MRR,优化的目的是为了减少磁盘的随机访问,并且将随机访问转化为较为顺序的数据访问,这对于 IO-bound 类型的sql查询语句性能带来了极大的提升。MRR 优化可使用于 range、ref、eq_ref 类型的查询
1、MRR 使数据访问变得较为顺序。在查询辅助索引时,首先根据得到的结果集,按照主键进行排序,并按照主键排序的顺序进行书签查找 2、减少缓冲池中页被替换的次数 3、批量处理对键值的查询操作
开启mrr:
1
2
SHOW VARIABLES LIKE '%optimizer_switch%';
set @@optimizer_switch='mrr=on,mrr_cost_based=off';
mysql锁
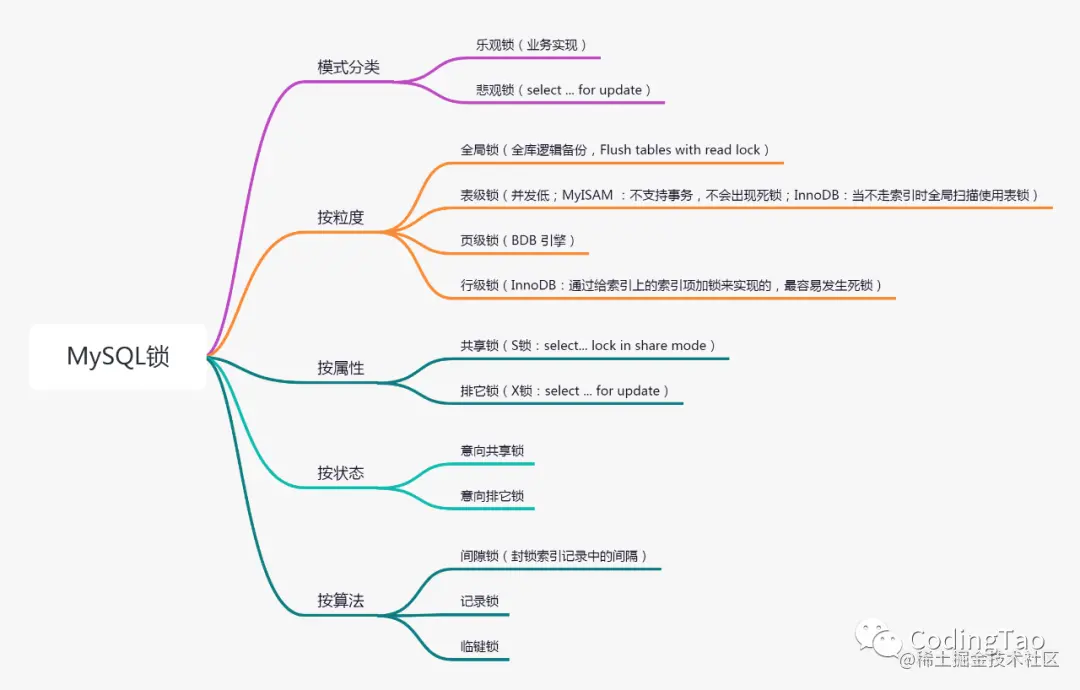
表锁
表级别的锁:1、表锁 2、元数据锁(meta data lock,MDL)
一般行锁都有锁超时时间。但是MDL锁没有超时时间的限制,只要事务没有提交就会一直锁注
当前操作的整张表加锁
lock tables …read/write
给一个表加字段、或者修改字段、或者加索引,需要全表扫描
行级锁
行级锁是粒度最低的锁,发生锁冲突的概率也最低、并发度最高。但是加锁慢、开销大,容易发生死锁现象
MySQL中只有InnoDB支持行级锁,行级锁分为共享锁(s锁,也叫读锁)和排他锁(x锁,也叫写锁)
在MySQL中,行级锁并不是直接锁记录,而是锁索引。索引分为主键索引和非主键索引两种,如果一条sql语句操作了主键索引,MySQL就会锁定这条主键索引;如果一条语句操作了非主键索引,MySQL会先锁定该非主键索引,再锁定相关的主键索引。在UPDATE、DELETE操作时,MySQL不仅锁定WHERE条件扫描过的所有索引记录,而且会锁定相邻的键值,即所谓的next-key locking
InnoDB这种行锁实现特点意味着:只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁!
共享锁
允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。这保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改
排他锁
允许获取排他锁的事务更新数据,阻止其他事务取得相同的数据集共享读锁和排他写锁。若事务T对数据对象A加上X锁,事务T可以读A也可以修改A,其他事务不能再对A加任何锁,直到T释放A上的锁
间隙锁
mysql仅在可重复读隔离级别下才有效
在索引记录之间的间隙上的锁,MySQL中用于保护范围查询和防止并发问题的重要机制
保证某个间隙内的数据在锁定情况下不会发生任何变化
当使用唯一索引来搜索唯一行的语句时,不需要间隙锁定
触发条件:
- 使用普通索引锁定:当一个事务使用普通索引进行条件查询时,MySQL会在满足条件的索引范围之间的间隙上生成间隙锁
- 使用多列唯一索引:如果一个表存在多列组成的唯一索引,并且事务对这些列进行条件查询时,MySQL会在满足条件的索引范围之间的间隙上生成间隙锁
- 使用唯一索引锁定多行记录:当一个事务使用唯一索引来锁定多行记录时,MySQL会在这些记录之间的间隙上生成间隙锁,以确保其他事务无法在这个范围内插入新的数据
加锁规则:
- 加锁的基本单位是 Next-Key Lock(临键锁),左开右闭区间
- 查找过程中访问到的对象才会加锁
- 唯一索引上的范围查询会上锁到不满足条件的第一个值为止
- 唯一索引等值查询,并且记录存在,Next-Key Lock 退化为行锁
- 索引上的等值查询,会将距离最近的左边界和右边界作为锁定范围,如果索引不是唯一索引还会继续向右匹配,直到遇见第一个不满足条件的值,如果最后一个值不等于查询条件,Next-Key Lock 退化为间隙锁
1
2
3
/* 如果id列有唯一索引,此时只会对id值为10的行使用记录锁
如果是普通查询则是快照读,不需要加锁,加了for update就不是普通查询 */
select * from t where id = 10 for update
需要注意的是,当id列上没有索引时,SQL会走聚簇索引的全表扫描进行过滤,由于过滤是在MySQL Server层面进行的。因此每条记录(无论是否满足条件)都会被加上X锁。但是,为了效率考量,MySQL做了优化,对于不满足条件的记录,会在判断后放锁,最终持有的,是满足条件的记录上的锁。但是不满足条件的记录上的加锁/放锁动作是不会省略的。所以在没有索引时,不满足条件的数据行会有加锁又放锁的耗时过程

1
2
3
4
/* 间隙锁锁定的间隙为:(5,11),所以你再想插入5到11之间的数就会被阻塞
执行update t set number = 6 where id = 1也会被阻塞
要保证每次查询number=6的数据行数不变,如果将另外一条数据修改成了6,会多一条记录,所以此时不会允许任何一条数据被修改成6 */
select * from t where number=6 for update;
临键锁
临键锁由记录锁和间隙锁组合而成,它在索引范围内的记录上加上记录锁,并在索引范围之间的间隙上加上间隙锁。这样可以避免幻读(Phantom Read)的问题,确保事务的隔离性
间隙锁的区间是左开右开的,临键锁的区间是左开右闭的
聚族索引
很简单记住一句话:找到了索引就找到了需要的数据,那么这个索引就是聚簇索引,所以主键就是聚簇索引,修改聚簇索引其实就是修改主键
非聚族索引:索引的存储和数据的存储是分离的,也就是说找到了索引但没找到数据,需要根据索引上的值(主键)再次回表查询,非聚簇索引也叫做辅助索引
聚族索引并不是单独的索引类型,而是一种数据存储方式;
在InnoDB的聚族索引实际上在同一结构中保存了B-Tree索引和数据行;
聚族就表示数据行和相邻的键值紧凑地存储在一起,因为无法同时将数据行放在两个不同的地方,所以一个表只能有一个聚族索引;
存储引擎负责实现索引,不是所有的存储引擎都支持聚族索引;
InnoDB通过主键聚集数据,如果没有定义主键,InnoDB会选择一个唯一的非空索引来代替(unique索引)。如果没有这样的索引,InnoDB会隐式定义一个主键来作为聚族索引,InnoDB只聚集在同一个页面中的记录
好处:
1、可以将相关数据保存在一起。聚集的数据放在一起保存,读取少数的数据页就可以获取某个条件的全部数据
2、数据访问更快,索引和数据保存在同一个B-Tree中
3、使用覆盖索引扫描的查询可以直接使用页的主键值
4、插入的速度严重依赖插入的顺序,是否按照主键顺序
innodb和MyISAM
InnoDB:mySQL默认的事务型引擎 MyISAM:在MySQL 5.1 及之前的版本,MyISAM是默认引擎
1、事务支持
MyISAM:不支持事务,强调的是性能
InnoDB:支持事务:支持4个事务隔离级别
2、表锁差异
MyISAM:表级锁定形式,数据在更新时锁定整个表
InnoDB:行级锁定,但是全表扫描仍然会是表级锁定
3、读写过程
MyISAM:数据库在读写过程中相互阻塞。会在数据写入的过程阻塞用户数据的读取,也会在数据读取的过程中阻塞用户的数据写入
InnoDB:读写阻塞与事务隔离级别相关
4、缓存特性
MyISAM:可通过key_buffer_size来设置缓存索引,提高访问性能,减少磁盘I/O的压力。但缓存只会缓存索引文件,不会缓存数据
InnoDB:具有非常高效的缓存特性:能缓存索引,也能缓存数据
5、存储方式
MyISAM:釆用 MyISAM存储引擎数据单独写入或读取,速度过程较快且占用资源相对少
InnoDB:表与主键以簇的方式存储
6、外键支持
MyISAM:MyISAM存储引擎它不支持外键约束
InnoDB:支持外键约束
7、全文索引
MyISAM:只支持全文索引
InnoDB:5.5以前不支持全文索引,5.5版本以后支持全文索引
8、在磁盘上的存储类型
MyISAM:每个 MyISAM在磁盘上存储成三个文件,每一个文件的名字以表的名字开始,扩展名指出文件类型
InnoDB:所有的表都保存在同一个数据文件中(也可能是多个文件,或者是独立的表空间文件),InnoDB表的大小只受限于操作系统文件的大小,一般为2GB
9、存储空间
MyISAM:支持三种不同的存储格式:
- 静态表(默认,但是注意数据末尾不能有空格,会被去掉)
- 动态表
- 压缩表
InnoDB:需要更多的内存和存储,它会在主内存中建立其专用的缓冲池用于高速缓冲数据和索引
10、表主键
MyISAM:允许没有任何索引和主键的表存在,索引都是保存行的地址
InnoDB:如果没有设定主键或者非空唯一索引,就会自动生成一个6字节的主键(用户不可见),数据是主索引的一部分,附加索引保存的是主索引的值
11、表的具体行数
MyISAM:保存有表的总行数,如果select count() from table;会直接取出出该值
InnoDB:没有保存表的总行数,如果使用select count(*) from table;就会遍历整个表,消耗相当大,但是在加了wehre条件后,myisam和innodb处理的方式都一样
12、读写性能
MyISAM:读取性能优越,但是写入性能差。如果执行大量的select,MyISAM是更好的选择
InnoDB:写入性能较强,如果执行大量的insert或者update,InnoDB是更好的选择