这篇笔记的目标是把文件系统放回操作系统的整体语境里来理解:文件到底如何映射到磁盘,目录、inode、VFS、页缓存分别负责什么,以及应用程序调用
open、read、write时内核究竟做了哪些事。
它更偏概念梳理和关系辨析,重点是建立一张完整心智图,而不是展开某一种具体文件系统的源码细节。文中会以 Linux 和 ext 系文件系统为主线,同时补上几处容易混淆但很关键的实现差异。
参考资料:
Overview of the Linux Virtual File System
[TOC]
文件系统到底在解决什么问题
文件系统是操作系统中负责管理持久化数据的子系统。内存断电后数据会丢失,而磁盘、SSD 等外部存储设备可以长期保存数据,文件系统要做的事情,就是把上层“按文件和目录访问数据”的需求,翻译成底层“按块组织和读写存储介质”的操作。
如果只从硬件角度看,磁盘看到的是一串又一串的数据块;如果只从应用程序角度看,开发者看到的是有名字的文件、层级化的目录、可顺序或随机访问的字节流。文件系统就在这两者之间,负责完成三类核心工作:
- 组织数据,把逻辑文件映射到物理块
- 管理元数据,记录权限、大小、时间戳、位置等信息
- 提供统一接口,让不同存储设备和不同文件系统都能以类似方式使用
Linux 中常说“一切皆文件”,本质上强调的是统一抽象:普通文件、目录、块设备、字符设备、管道、socket 等,都尽量通过统一的文件接口暴露给用户空间。
文件系统的基本组成
inode、目录记录和 dentry
在 Linux/Unix 风格文件系统里,理解文件最关键的两个问题是:
- 文件名放在哪里?
- 文件元数据和数据块位置又放在哪里?
答案并不是“都放在同一个地方”。通常可以拆成两层:
- inode(索引节点):记录文件的元数据,例如文件类型、权限、拥有者、大小、时间戳、链接计数,以及数据块或 extent 的定位信息。inode 是文件在文件系统内部的重要标识。
- 目录记录(directory entry / dirent):记录“文件名 -> inode 编号”的映射关系。目录本身也是一种文件,它的数据块里保存的就是这些目录记录。
这里有一个很容易混淆的点:很多资料会把“目录项”直接等同于 dentry。严格来说,Linux 内核里的 dentry(directory entry cache)主要是 VFS 层的内存对象,用于缓存路径解析结果;而磁盘上真正保存的是目录文件中的目录记录。两者相关,但不是同一件东西。
因此,更准确的理解应该是:
- 文件名主要存在目录文件的目录记录里
- 文件元数据主要存在 inode 里
- 内核为了加速路径查找,会在内存里维护 dentry 缓存
这也解释了为什么inode 不保存文件名。一个 inode 可以被多个目录记录引用,所以一个文件可以拥有多个硬链接名。
目录和普通文件的共同点与区别
目录在文件系统里也是“文件”,因此它也有 inode,也会占用数据块。
区别在于:
- 普通文件的数据块保存的是用户数据
- 目录文件的数据块保存的是目录记录,也就是“名字和 inode 的对应关系”
所以目录并不是“一个特殊的纯内存结构”,而是有磁盘表示的;只是为了提高性能,内核会把最近访问过的目录相关信息缓存在内存里。
文件系统最基本的读取路径
一个路径如 /home/user/a.txt 被访问时,内核通常要做这些事:
- 从根目录开始逐级解析路径分量
- 在每一级目录中查找对应名字的目录记录
- 根据目录记录拿到 inode 编号
- 读取或命中对应 inode
- 根据 inode 中的数据块映射找到真正的数据
可以概括为:路径查找靠目录,文件定位靠 inode,真正的数据读取靠块映射或 extent。
文件数据如何存储在磁盘上
磁盘读写并不是按“1 个字节”来完成的,而是按更大的物理或逻辑单位完成。
扇区、块和页缓存
磁盘设备的最小物理读写单位通常可以抽象为扇区,传统上常见为 512B,也有 4KB 的高级格式磁盘。为了提高管理和 I/O 效率,文件系统会把若干扇区组织成块(block),块才是文件系统分配空间和组织数据时最基础的单位之一。
在 Linux 中,很多文件系统常见块大小是 4KB,但这不是绝对固定值。
文件系统格式化后,通常至少会包含下面几类信息:
- 超级块(superblock):记录整个文件系统的全局元数据,例如块大小、块数、inode 数量、挂载状态等
- inode 表或 inode 区:存放 inode
- 数据块区:存放文件内容和目录内容
- 位图或其他分配结构:记录哪些 inode、哪些数据块仍然空闲
哪些结构会进入内存
磁盘上的元数据并不会一次性全部装入内存。更常见的做法是:
- 文件系统挂载时读取超级块等关键全局信息
- 访问具体文件时,再把对应 inode 读入内存并缓存
- 路径查找过程中,把常用目录项、inode、页缓存保留在内存里
所以内核里通常会同时存在:
- superblock 的内存对象
- inode cache
- dentry cache
- page cache
这几层缓存一起决定了“第二次访问同一文件为什么会比第一次快很多”。
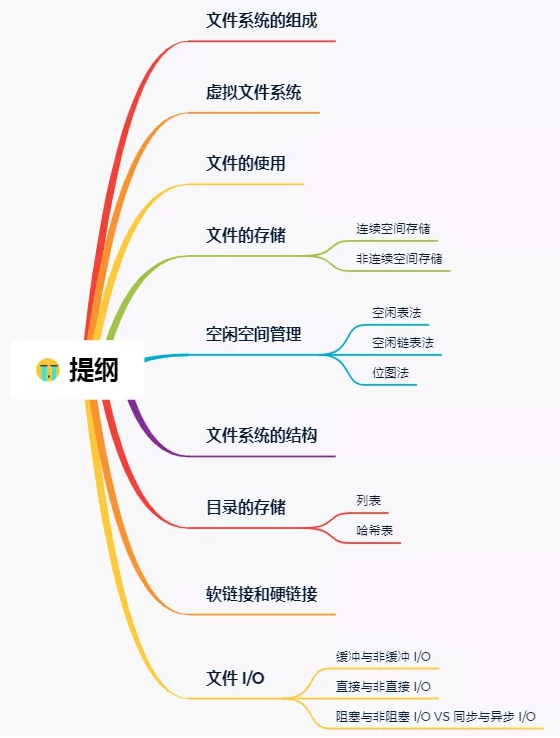
虚拟文件系统 VFS
Linux 支持的文件系统种类很多,例如 ext4、XFS、Btrfs、F2FS、procfs、tmpfs、NFS、SMB 等。如果每种文件系统都向应用程序暴露完全不同的接口,那么上层程序几乎无法编写。
因此,Linux 在系统调用和具体文件系统实现之间引入了一层统一抽象,这一层就是 VFS(Virtual File System,虚拟文件系统)。
VFS 的核心作用是:
- 为上层提供统一的文件操作接口,如
open、read、write、stat - 为下层文件系统定义一组统一对象和操作方法
- 屏蔽 ext4、XFS、tmpfs、NFS 等底层差异
在 VFS 语义下,常见的几个核心对象包括:
super_block:表示一个已挂载的文件系统实例inode:表示某个文件对象的元数据dentry:表示路径中的一个目录项缓存file:表示一次已经打开的文件实例
这里尤其要区分 inode 和 file:
- inode 更像“这个文件本身”
- file 更像“某个进程这一次打开它之后得到的打开实例”
这也是为什么同一个文件被两个进程同时打开时,它们可能共享同一个 inode,但拥有不同的文件偏移量。
按照存储位置或用途,大致可以把文件系统分为三类:
- 磁盘文件系统:如 ext4、XFS,数据主要持久化在块设备上
- 内存文件系统:如 tmpfs;
/proc、/sys更准确地说是伪文件系统,内容由内核动态生成,不是传统意义上的磁盘文件 - 网络文件系统:如 NFS、SMB,用于访问远端主机上的数据
文件系统要先挂载到某个目录树节点上,之后才能被统一访问。Linux 启动后看到的一棵完整目录树,本质上往往是多个文件系统挂载拼接出来的结果。
文件是如何被使用的
从用户态看:open、read/write、close
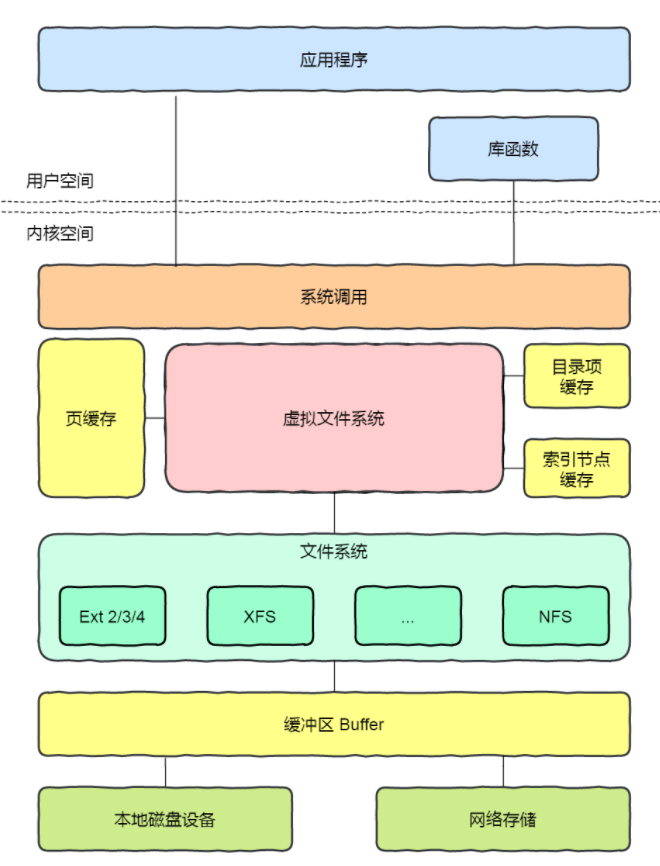
应用程序最常见的文件使用方式,是先通过 open 打开文件,再通过 read 或 write 读写,最后调用 close 关闭。
这几个调用里最值得注意的是:
open的输入是路径名,返回的是文件描述符fd- 后续
read、write、lseek等操作,主要使用的是fd close用于释放打开文件相关资源
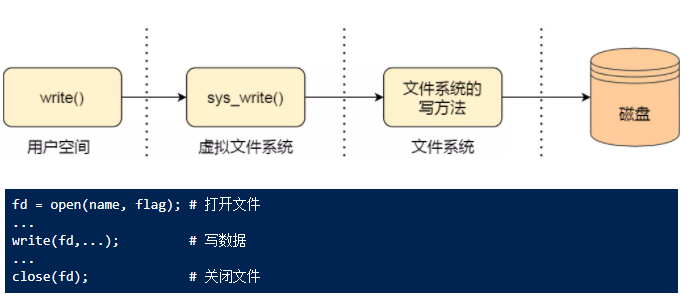
文件描述符并不是文件本身,而是进程文件描述符表中的一个整数索引。
从内核看:打开文件后到底记录了什么
当一个进程打开文件后,内核通常至少需要维护下面几类信息:
- 文件描述符表项:把进程里的整数
fd映射到一个打开文件对象 - 打开文件对象(open file description / struct file):记录当前文件偏移量、打开标志、访问模式等
- inode 引用:指向文件对应的 inode
因此,一个打开文件对象里常见的信息有:
- 文件偏移量:下一次读写从哪里开始
- 打开标志:只读、只写、读写、追加等
- 引用计数:有多少个文件描述符引用该打开实例
- 指向 inode 的引用:定位到真正的文件对象
这里可以补一个很重要但经常被忽略的知识点:
dup复制文件描述符时,新的fd往往共享同一个打开文件对象,所以共享文件偏移量fork之后,父子进程继承的文件描述符通常也指向同一个打开文件对象
这也是很多并发 I/O 行为看起来“互相影响”的根源。
删除文件为什么不一定马上释放空间
在 Unix 语义中,删除一个文件名,本质上通常是在删除目录中的那条目录记录,并减少 inode 的链接计数。
只有同时满足下面两个条件,文件数据才真正有资格被回收:
- 没有目录记录再指向该 inode
- 没有进程继续打开这个文件
所以会出现一种很典型的现象:
- 进程 A 打开了日志文件
- 管理员把这个文件
rm掉 - 只要进程 A 还没关闭文件,磁盘空间通常仍不会立刻回收
这也是排查“文件明明删了但磁盘空间没回来”时必须掌握的知识点。
文件的存储方式
文件的数据最终都要落到磁盘块上。如何从“逻辑文件”映射到“物理块”,决定了文件系统在空间利用率、随机访问能力、顺序访问性能、扩展性上的差异。
常见思路可以概括为两大类:
- 连续分配
- 非连续分配
而非连续分配又可以继续分成:
- 链式分配
- 索引分配
连续空间存放方式
连续分配是最直观的方式:一个文件占据磁盘上一段连续的物理空间。
这样做的优点非常明显:
- 顺序读写性能好
- 随机访问也简单,只要知道起始块号和偏移即可定位
- 元数据开销较小
因此,文件头里只需要记录两项关键信息:
- 起始块位置
- 文件长度或占用块数
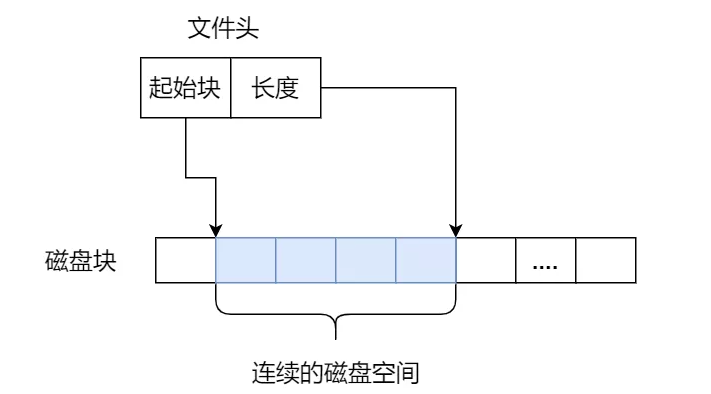
但它的问题同样明显:
- 容易产生外部碎片
- 文件扩展困难

如果一个文件需要继续增长,而它后面的连续区域已经被别的文件占用,就只能搬迁整个文件,代价很高。因此,纯连续分配并不适合通用文件系统长期使用。
非连续空间存放方式:链式分配
链式分配的思路是:文件的各个数据块不要求连续,每个块通过指针串到下一个块。
优点是:
- 消除了连续空间要求
- 文件扩展方便
- 空间利用率更高
隐式链表
隐式链表会在每个数据块里留出一部分空间保存“下一个块的位置”,文件头记录第一块,之后顺着指针一路往后找。
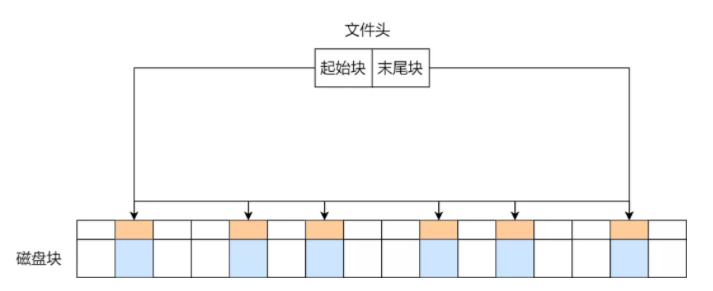
缺点也很典型:
- 无法高效随机访问,通常只能顺着链走
- 每个数据块都要额外存指针
- 一旦链断裂,后续数据可能无法恢复
显式链接与 FAT
显式链接把“块与块之间的指针”从数据块中抽出来,统一放到一张表里,这就是 FAT(File Allocation Table) 的核心思路。
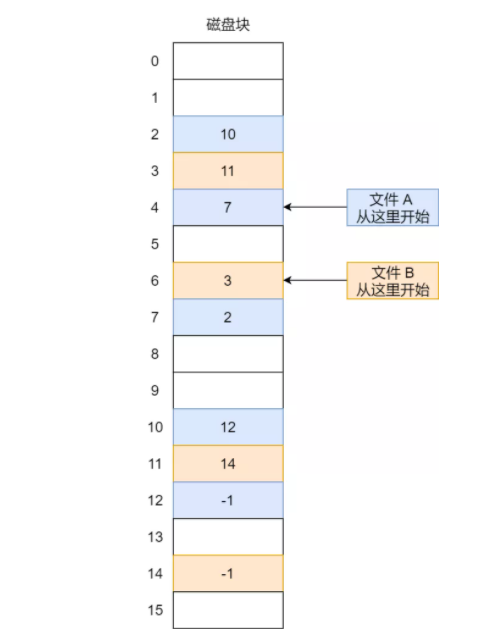
这样做之后:
- 数据块本身不用再保存后继指针
- 块链追踪主要在内存中的 FAT 表里完成
- 比隐式链表更容易管理
但 FAT 也有明显缺点:
- FAT 表可能非常大
- 大容量磁盘下内存开销明显
- 文件访问仍然容易受链式组织影响
因此,FAT 在简单场景里足够实用,但不适合今天的大型通用文件系统作为主要组织方式。
非连续空间存放方式:索引分配
索引分配的核心思路是:为文件单独维护一个索引块或索引结构,里面记录文件数据块的位置。
这样一来,文件头只要指向索引结构,就能进一步找到真正的数据块。
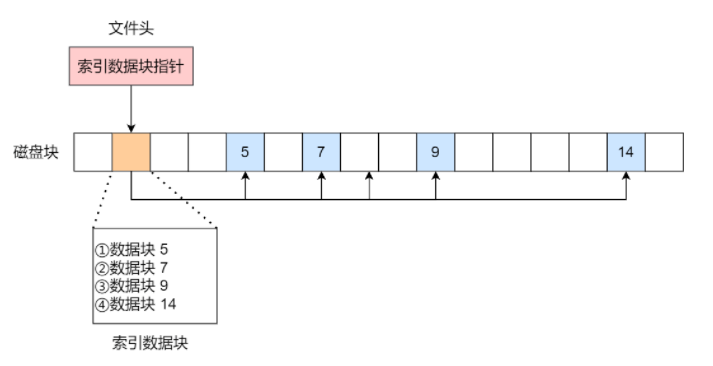
它的优点是:
- 支持随机访问
- 文件扩展、缩小都更灵活
- 不需要连续物理空间
- 不会像链式分配那样必须逐块追踪
缺点是:
- 要额外维护索引结构
- 小文件也可能要承担额外索引开销
大文件怎么办:多级索引与更现代的 extent
当文件很大、单个索引块装不下所有块指针时,传统 Unix 文件系统会引入多级索引。
链式索引块
链式索引块是“索引 + 链表”的组合:索引块里除了记录数据块地址,还会记录下一个索引块的位置。
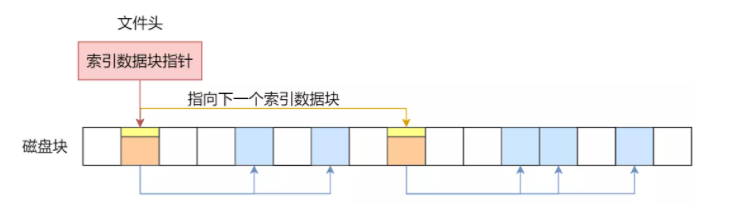
它能处理更大的文件,但也继承了链式结构的脆弱性。
多级索引块
多级索引块是“索引指向索引”,例如一级间接、二级间接、三级间接。早期 Unix 文件系统常通过这种方式支持大文件。
| 方式 | 访问磁盘次数 | 优点 | 缺点 |
|---|---|---|---|
| 顺序分配 | 通常较少 | 顺序访问快,实现简单 | 要求连续空间,易碎片,扩展困难 |
| 链式分配 | 随链长增长 | 扩展方便,空间利用率高 | 随机访问弱,链损坏风险高 |
| 索引分配 | 取决于索引层级 | 支持随机访问,扩展灵活 | 需要索引开销 |
早期 Unix 常见的 inode 设计会在文件头中保留若干直接块指针,再加一级、二级、三级间接指针,这样能兼顾小文件和大文件:
- 小文件直接通过少量直接指针访问,开销低
- 大文件再逐级走间接索引,扩展能力强
这里可以补充一个现代文件系统知识点:ext4 现在更常见的是使用 extent,而不是完全依赖传统的直接块/间接块寻址。
extent 不再逐块记录地址,而是记录“一段连续块区间”,例如“从第 N 个逻辑块开始,连续映射到磁盘上的 M 个块”。这样做的好处是:
- 大文件元数据更紧凑
- 顺序文件的定位效率更高
- 更适合现代大容量磁盘和 SSD
因此,学习“直接块 + 间接块”更像是在理解文件系统设计思想;而理解 ext4 等现代文件系统时,extent 同样是关键概念。
空闲空间管理
文件写入之前,文件系统除了要知道“文件怎么组织”,还要知道“哪里还有空闲块可用”。这就是空闲空间管理。
常见方法有三类:
- 空闲表法
- 空闲链表法
- 位图法
空闲表法
空闲表法会记录每一段空闲区的起始块号和块数。
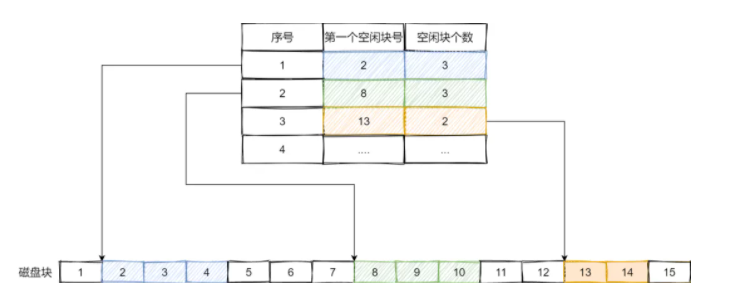
优点是实现直观,适合连续分配场景;缺点是当空闲区被切得很碎时,表会变得很大,查找效率下降。
空闲链表法
空闲链表法把所有空闲块串成链表,每个空闲块指向下一个空闲块。
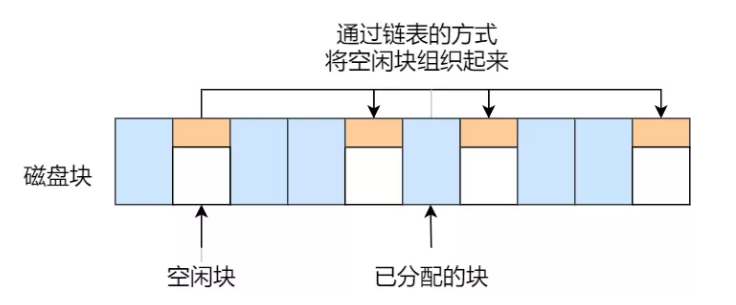
这种做法的优点是结构简单,但随机定位效率低,而且维护链表需要额外 I/O 和空间开销,所以并不适合大型通用文件系统。
位图法
位图法使用一个 bit 对应一个块:
0表示空闲1表示已分配
例如:
111111001100011111000111101010101010111001...
位图法的优点是:
- 空间开销相对可控
- 查找和统计方便
- 易于批量管理块和 inode
Linux 的 ext 系文件系统广泛使用位图来管理空闲块和空闲 inode。
Linux 文件系统的结构
以 ext2/ext3/ext4 这一类文件系统为例,文件系统并不是只有一个“超级块 + inode 区 + 数据区”那么简单。为了支持更大空间和更高可靠性,它们会把整个文件系统拆成多个 块组(block group)。
每个块组内部通常包含:
- 超级块副本或相关关键元数据
- 块组描述符相关信息
- 数据块位图
- inode 位图
- inode 表
- 数据块
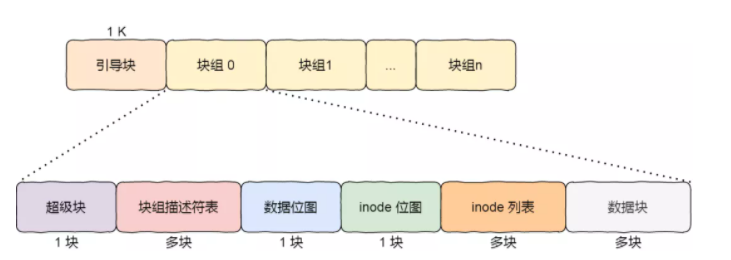
这样设计主要有两个目的:
- 局部性更好:尽量让 inode、位图和数据块彼此靠近,减少寻道
- 可靠性更高:关键元数据可以有冗余副本,损坏后更容易恢复
需要注意的是,现代 ext 文件系统会采用稀疏超级块等优化手段,并不是每个块组都完整复制同样数量的全局元数据。
目录是如何存储的
从文件系统视角看,目录就是一种特殊文件,它的数据块里保存的不是普通用户数据,而是一条条目录记录。
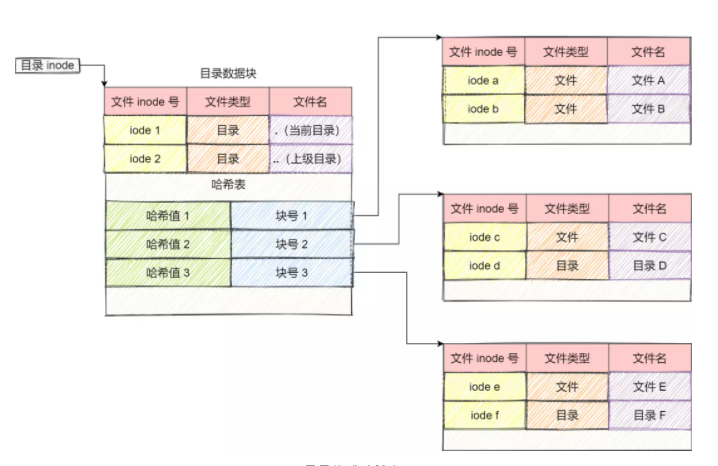
最简单的目录组织方式就是线性表:
- 每一项记录文件名、inode 编号、记录长度、类型等信息
- 查找某个名字时,从前往后扫描
这种方式在目录较小时完全够用;但当一个目录里文件非常多时,线性扫描效率会明显下降。
因此,现代文件系统往往会为大目录引入更高效的索引结构。以 ext 系文件系统为例,更准确的说法是:
- 小目录可以仍然采用线性目录项布局
- 大目录通常会启用 hash tree(htree) 一类索引机制,加速按名称查找
所以,把 ext 文件系统简单说成“目录就是哈希表”并不严谨。更准确地说,它会在需要时为目录引入基于哈希的树形索引。
目录中常见的特殊项有:
.表示当前目录..表示父目录
目录查找会频繁触发路径解析,因此内核会把最近访问的路径结果缓存在 dentry cache 中,以减少重复的磁盘 I/O。
软链接和硬链接
Linux 中常见的“给文件取别名”主要有两种方式:硬链接和软链接。
硬链接
硬链接的本质是:多个目录记录指向同一个 inode。
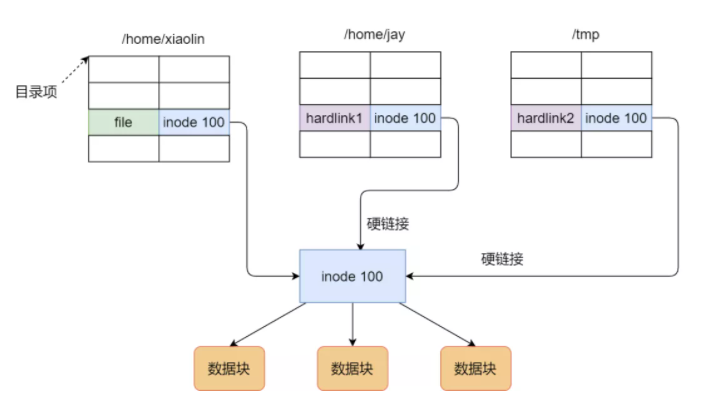
因此,硬链接具有这些特征:
- 不会新建一份文件内容
- 多个名字共享同一个 inode 和同一份数据
- 不能跨文件系统使用,因为 inode 编号只在各自文件系统内部有效
- 通常不能给目录创建普通硬链接,以避免目录环导致遍历和一致性问题
只要还有任何一个目录记录指向该 inode,文件数据通常就不会被真正删除。
软链接
软链接本质上是一个独立文件,它有自己的 inode,但文件内容保存的是“目标路径”。
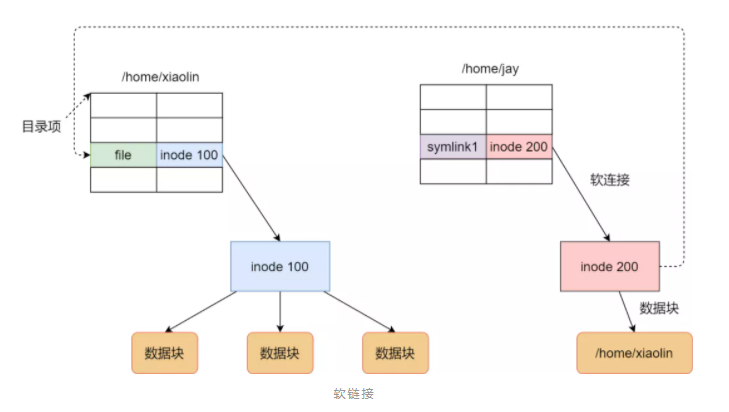
因此软链接具有这些特征:
- 可以跨文件系统
- 可以指向目录
- 目标删除后,软链接本身仍然存在,但会变成悬空链接
可以概括为:
- 硬链接链接的是 inode
- 软链接链接的是路径名
文件 I/O
文件 I/O 经常会看到几组容易混在一起的概念:
- 缓冲与非缓冲 I/O
- 直接与非直接 I/O
- 阻塞与非阻塞 I/O
- 同步与异步 I/O
这几组维度讨论的并不是同一件事。
缓冲与非缓冲 I/O
这里的“缓冲”通常是指用户态标准库缓冲。
- 缓冲 I/O:例如
fopen、fwrite这一类标准库接口,会先把数据写到用户态缓冲区,攒到一定条件再调用系统调用 - 非缓冲 I/O:例如直接调用
read、write,绕过标准库缓冲,直接进入内核
所以,标准库是否缓冲,和内核是否使用页缓存,不是一回事。
直接 I/O 与普通缓存 I/O
Linux 内核为了减少磁盘访问次数,会使用 page cache(页缓存)。普通文件读写大多会经过页缓存:
- 读时,优先从页缓存命中
- 写时,往往先写入页缓存,之后再由内核回写到磁盘
对应地:
- 普通缓存 I/O:经过页缓存
- 直接 I/O(Direct I/O):主要指尽量绕过页缓存,常通过
O_DIRECT请求
这里也要避免一个常见误解:直接 I/O 不等于完全不经过内核,也不等于零拷贝。 它更准确的含义是“尽量不使用页缓存作为中间层”,但具体实现仍受文件系统、设备、对齐要求等约束。
写回什么时候发生
如果使用普通缓存 I/O 进行写入,数据通常会先进入页缓存,之后再回写到磁盘。触发回写的常见时机包括:
- 脏页累计过多
- 后台回写线程周期性刷盘
- 调用
fsync、fdatasync等显式持久化接口 - 内存压力较大,需要回收页缓存
所以,write 返回成功通常意味着“数据已经进入内核可管理的缓冲体系”,并不一定意味着“已经安全落盘”。如果需要持久化语义,通常还要结合 fsync 理解。
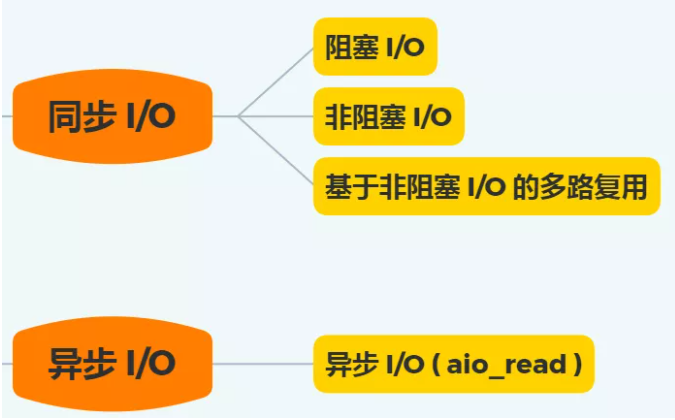
阻塞与非阻塞 I/O
阻塞和非阻塞主要讨论的是:当当前条件不满足时,系统调用会不会立刻返回。
- 阻塞 I/O:条件不满足时,调用线程会睡眠等待
- 非阻塞 I/O:条件不满足时,立即返回,通常得到
EAGAIN一类结果
对管道、socket、终端设备等对象,这个区别很重要;但对普通磁盘文件,O_NONBLOCK 往往没有用户直觉里那么强的意义,因为普通文件通常总是“可读/可写”,真正耗时的是页缓存缺页和底层存储访问。
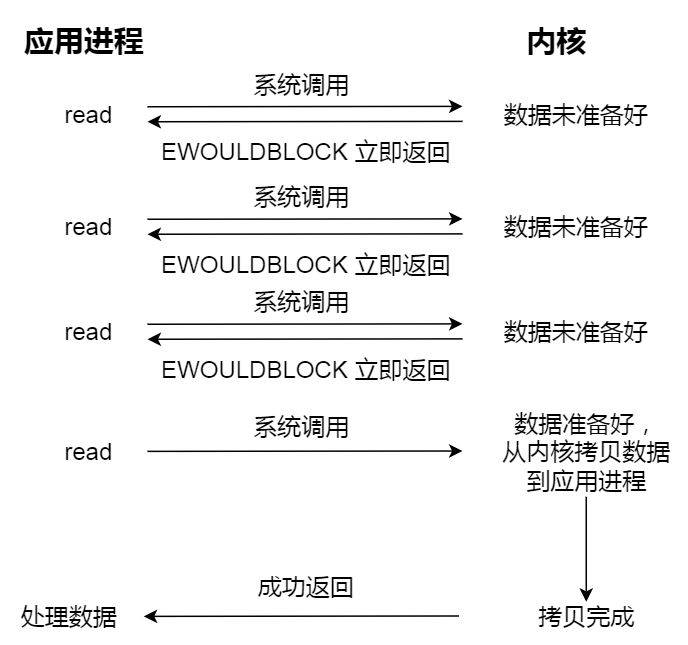
I/O 多路复用
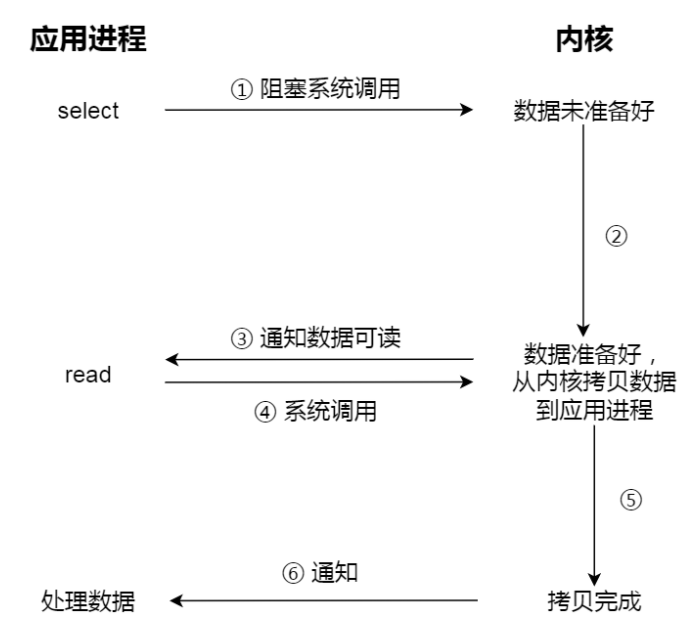
应用程序如果不断轮询多个文件描述符,会浪费 CPU,因此 Linux 提供了 select、poll、epoll 等 I/O 多路复用机制。
它们的核心不是“帮你把数据读完”,而是:
- 帮你等待多个 I/O 对象上的事件
- 当对象就绪后,再通知应用程序去执行实际的
read或write
因此,多路复用提升的是等待阶段的组织方式,而不是把同步读写直接变成异步。
同步与异步 I/O
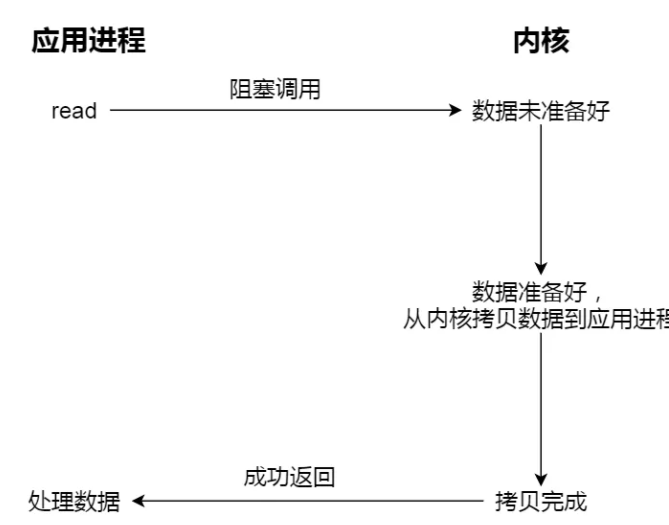
把一次读操作拆开,可以看到两个阶段:
- 数据准备好
- 数据从内核空间拷贝到用户缓冲区
据此可以理解:
- 阻塞 I/O:阶段 1 和阶段 2 都可能让调用线程等待
- 非阻塞 I/O:阶段 1 不一定阻塞,但真正拷贝数据时仍可能需要同步完成
- I/O 多路复用:把“等数据就绪”这件事交给统一事件机制,真正读数据时通常仍是同步完成
- 异步 I/O:提交请求后立即返回,后续由内核在合适时机完成数据准备和拷贝,并在完成后通知应用程序
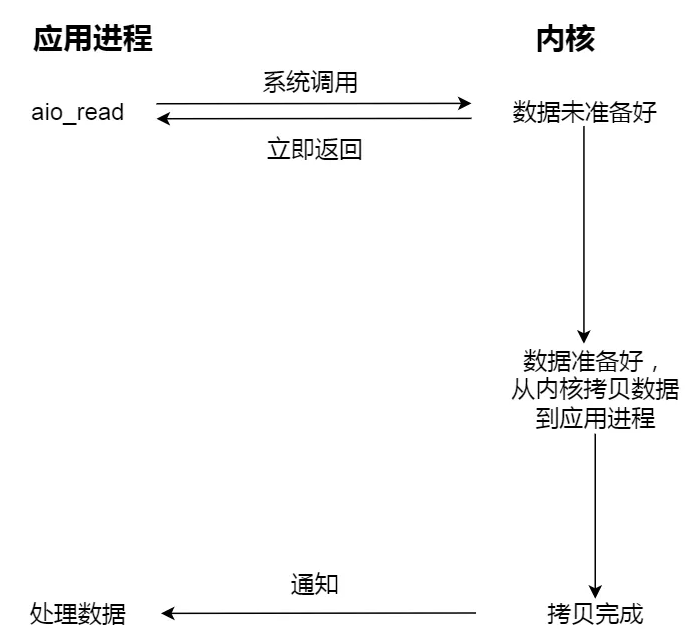
补充一点现代 Linux 背景:早期教材常用 aio_read 讲异步 I/O,但在 Linux 实践里,真正高性能、通用性更强的异步 I/O 讨论如今更常围绕 io_uring 展开。理解“异步 I/O 的标准定义”和“Linux 上常见工程实现”是两回事,最好区分开看。
一页总结
如果把整篇内容压缩成一张图,文件系统可以这样理解:
- 名字在哪里:在目录文件的目录记录里
- 元数据在哪里:在 inode 里
- 数据在哪里:在数据块或 extent 指向的物理区域里
- 统一接口是谁提供的:VFS
- 为什么重复访问会更快:有 dentry cache、inode cache、page cache
- 文件为什么能有多个名字:多个目录记录可以指向同一个 inode
- 删除为什么不一定立刻释放空间:链接计数和打开引用都要归零
- 普通写入为什么不一定立刻落盘:先进入页缓存,随后再回写
真正理解文件系统,关键不是死记某一种磁盘布局,而是把这几层关系串起来:
- 用户看到的是路径和文件名
- VFS 看到的是统一对象模型
- 具体文件系统看到的是 inode、目录、位图、块组、extent
- 块设备看到的是一段段可读写的存储块
当这几层抽象连接起来之后,很多操作系统问题都会变得清晰,比如路径解析为什么慢、为什么删了文件空间不一定回来、为什么 fsync 很关键、为什么小文件和大文件在底层组织方式上会有不同优化。