这篇笔记的目标是把
AREX Agent放到 Java 后端工程里真正拆开来看:一次录制到底会产出什么数据对象,数据如何落到Storage Service + MongoDB + Redis,回放时又是怎么把真实下游调用短路成录制结果。重点不再停留在“它能做回放测试”这类概念层,而是直接进入数据模型、运行机制和源码入口。
文章会尽量站在 Java 业务开发和源码阅读的双重视角来组织内容,重点围绕
Spring Boot / Spring Cloud / Dubbo / Redis / Caffeine / Elasticsearch / MyBatis这类常见技术栈展开,并补一个“订单聚合查询服务”的完整案例:从入口请求、依赖 mocker、recordId / replayId、存储方式,到premain -> AgentInitializer -> InstrumentationInstaller的源码切入路径。文中也会单独说明一个容易误解的点:AREX Agent擅长验证真实请求下的行为一致性,但它并不等于全能测试框架,覆盖效果取决于被拦截的组件、动态数据治理以及回放环境的约束是否设计得足够清楚。
参考资料:
Technical Implementation of AREX Agent
[TOC]
一、这篇笔记到底要回答什么
如果是做学习笔记,真正需要回答的其实是下面几个问题:
- 一次录制到底录了什么,数据长什么样?
- 这些数据是怎么组织、怎么存、怎么查、怎么在 UI 里看的?
AREX Agent为什么能在不改业务代码的前提下拦到请求和依赖调用?- 录制与回放在源码里分别从哪里切进去?
- 它在
Spring Boot / Dubbo / Redis / Caffeine / Elasticsearch / MyBatis这类 Java 栈里,到底是怎么串成一条完整链路的?
如果只用一句话先说结论:
AREX Agent本质上不是“流量抓包工具”,也不是“接口平台增强版”,而是一个基于Java Instrumentation + ByteBuddy的运行时增强代理。它把入口请求和依赖调用都包装成统一的录制对象,用recordId串成一条完整 case,在回放时再按同一条 case 的依赖快照去短路真实调用、返回录制结果,最后做差异比对。
所以真正要理解 AREX,重点不是记住“它支持哪些中间件”,而是要看清三层:
- 数据层:录制 case 由哪些对象组成
- 机制层:为什么它能录、能回放
- 源码层:入口、上下文、增强点、存储协作分别落在哪些模块
二、先建立一张整体图
可以先把 AREX 的完整工作流压缩成下面这张脑图:
- 应用通过
-javaagent挂载arex-agent.jar - JVM 启动时执行
premain - Agent 用
Instrumentation + ByteBuddy给入口类和依赖类织入 Advice - 真实请求进来后,入口 Advice 创建上下文,生成
recordId - 请求执行期间,Redis、Dubbo、MyBatis、HTTP、Elasticsearch、动态类、本地时间等拦截点把自己的请求与响应记录成 mocker
- Agent 把这些录制对象发给
AREX Storage Service - Storage 持久化到
MongoDB,并在回放阶段配合Redis做缓存 - 回放时,调度服务按
recordId取回入口请求并重新发给目标环境 - 同时,目标应用中的 Agent 发现这是回放请求,于是拦截内部依赖调用,直接返回已录制的响应
- 目标应用跑完后返回新的主响应,再和录制期的主响应做比对,生成报告
从这张图可以看出,AREX 其实同时解决了三件事:
- 如何拦截
- 如何串联
- 如何替换
其中最关键的是”串联”。
如果不能把入口请求、下游调用、最终响应放进同一条语义链里,就只能得到一堆散落的日志;那样不叫回放,只能叫采样。
AREX 平台组件一览
| 组件 | 职责 | 部署数 |
|---|---|---|
| AREX Java Agent | 挂载到应用 JVM,负责字节码增强、录制和回放 | n(每个被测应用实例一个) |
| Schedule Service | 发起回放请求,调度回放任务并收集响应 | 1 |
| Storage Service | 存储录制数据,回放时按 Mock 方式提供响应 | 1 |
| AREX-API | 为前端 UI 提供所有接口 | 1 |
| AREX-UI | 前端页面,查看录制/回放结果与差异 | 1 |
| MongoDB | 持久化录制数据和配置管理 | 1 |
| Redis | 高速回放缓存 | 1 |
三、AREX 录制的数据到底是什么结构
这是最应该先讲清楚的一层。
很多人第一次接触 AREX 时,以为它录下来的只是:
- 一个 HTTP 请求
- 一个 HTTP 响应
但从官方技术文档和源码里的模型定义看,AREX 真实录制的是一组围绕 recordId 组织起来的资源对象。
3.1 先记两个 ID
理解数据结构前,先记住两个标识:
recordId:一次录制 case 的主标识replayId:一次回放执行的主标识
可以把它们理解成:
recordId解决“原始基线是谁”replayId解决“这次验证跑的是哪一轮”
一个 recordId 可以被重复回放很多次,因此会对应多个 replayId。
3.2 一条 case 不是一个对象,而是一组对象
从 arex-storage 的 README 和 Agent 侧模型命名看,AREX 会把录制资源组织成类似下面的结构:
- 一个主入口对象
MainEntry - 多个依赖调用对象
MockItem / ArexMocker - 回放产生的结果对象
- 差异比较结果对象
换句话说,一条 case 的核心不是“一个 request-response”,而是:
一个入口请求,外加它在执行过程中碰到的所有关键依赖调用快照。
3.3 主入口对象可以怎么理解
arex-storage README 里给出的 MainEntry 接口大致有这些关键字段:
recordIdreplayIdcreateTimerequestcategoryTypeformatmethodrequestHeaderspath
如果把它翻译成业务含义,其实就是:
- 这是哪条录制
- 这是哪次回放
- 它什么时候生成
- 主入口请求体是什么
- 它属于哪类入口
- 入口格式、方法、请求头、路径分别是什么
也就是说,MainEntry 更像“这次 case 的封面页”。
3.4 依赖调用对象 ArexMocker 有哪些核心字段
从源码中的 ArexMocker 看,核心字段大致包括:
idcategoryTypereplayIdrecordIdappIdrecordEnvironmentrecordVersioncreationTimetargetRequesttargetResponseoperationNametagsrequestresponseaccurateMatchKeyfuzzyMatchKeyeigenMap
这组字段其实已经把它的用途说得很清楚了。
可以把一个 ArexMocker 近似理解成:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
{
"recordId": "AREX-xxx",
"replayId": null,
"categoryType": "REDIS",
"appId": "order-query-service",
"operationName": "RedisTemplate.opsForValue.get",
"targetRequest": {
"body": "base64/compressed request body",
"attributes": {
"key": "order:detail:1001"
}
},
"targetResponse": {
"body": "base64/compressed response body",
"type": "application/json"
},
"creationTime": 1711111111111,
"accurateMatchKey": 123456,
"fuzzyMatchKey": 654321,
"tags": {
"cluster": "prod-sh"
}
}
这里最值得关注的是六个字段:
categoryType:这是哪一类 mock,决定它属于入口、HTTP、Redis、Dubbo、数据库、动态类、时间等哪种资源targetRequest:这次依赖调用的请求快照targetResponse:这次依赖调用的响应快照operationName:这次调用到底是哪个操作recordId:它属于哪条主 casereplayId:这次是否已经进入某轮回放
categoryType 分类速查
| categoryType | 对应组件 | 典型 operationName 示例 |
|---|---|---|
SERVLET / MAIN_ENTRY |
HTTP 入口 | GET /api/orders/detail |
HTTP_CLIENT |
出站 HTTP 调用 | RiskClient.querySummary |
DUBBO |
Dubbo RPC | FulfillmentQueryFacade.query |
DATABASE |
数据库(MyBatis 等) | OrderMapper.selectById |
REDIS |
Redis 操作 | RedisTemplate.opsForValue.get |
DYNAMIC_CLASS |
本地缓存/动态类 | OrderLocalCache.get |
ELASTICSEARCH |
ES 查询 | SearchExtraClient.search |
TIME |
时间 mock | System.currentTimeMillis |
3.5 targetRequest 和 targetResponse 才是“可回放”的关键
真正支撑回放的不是 recordId 本身,而是每个依赖调用都被序列化成了“请求-响应对”。
因为回放时 Agent 要做的并不是“重新执行一遍录制期逻辑”,而是:
- 识别当前内部调用是什么
- 根据当前上下文找到与之匹配的录制对象
- 从
targetResponse里取回原始响应 - 直接返回给业务代码
这就是为什么 AREX 可以在回放时避免真实调用下游。
3.6 accurateMatchKey、fuzzyMatchKey、eigenMap 是干什么的
这几个字段很容易被忽略,但它们恰恰说明 AREX 不是简单地按“先来后到”匹配 mock。
可以把它们理解成匹配层的辅助索引:
accurateMatchKey:偏精确匹配fuzzyMatchKey:偏模糊匹配eigenMap:偏特征值匹配
官方文档在动态类配置里明确提到:
- 先按请求参数做精确匹配
- 找不到再做模糊匹配
- 同签名情况下找不到精确命中,则可能退化到按录制时间选最新结果
这就解释了一个很关键的问题:
AREX 回放不是只靠
recordId把整条依赖链“按顺序播录像”,而是每个依赖点都要基于上下文和请求特征找到最合适的录制数据。
3.7 为什么有 request、response 这两个原始字符串字段
在 ArexMocker 里还有两个容易被忽视的字段:
requestresponse
源码注释写得很直接:
request是原始压缩请求文本response是原始压缩响应文本
而 UI 文档也提到:
- 某些录制的 request/response body 会经过 base64 压缩
- 页面里看到后,必要时需要人工解码或解压才能直观看内容
这意味着:
- 平台侧看到的“请求体、响应体”不一定是明文 JSON
- 存储层会为性能和通用性保留压缩后的原始文本形态
所以如果后面你要排查“AREX 明明录了,为什么页面里看起来像乱码”,优先别怀疑数据坏了,先确认是不是压缩和编码问题。
四、这些数据到底怎么存
4.1 默认不是落本地文件,而是走 Storage Service
AREX 的默认存储路径不是:
- 业务应用本地磁盘上的一个 case 文件夹
而是:
- Agent 把录制资源发给
AREX Storage Service - Storage 再把录制数据持久化到
MongoDB
这一点在官方 README 里讲得很明确:
MongoDB用于持久化录制数据Redis用于回放阶段缓存
所以更准确地说:
MongoDB存”录制事实”Redis存”回放过程中的临时命中与缓存结果”
存储职责对比
| 维度 | MongoDB | Redis |
|---|---|---|
| 角色 | 权威持久化存储 | 回放高速缓存 |
| 存什么 | 录制 case 全量数据(MainEntry + 各 Mocker) | 本轮回放中的 mock 命中结果与比对中间态 |
| 生命周期 | 默认保留 4 天(TTL 可配) | 随回放任务生灭 |
| 数据量 | 大(文档型半结构化) | 小(热点命中键值) |
4.2 为什么录制数据适合落 MongoDB
因为一条 case 本质上是半结构化对象集合:
- 主入口对象字段较固定
- 各类依赖 mocker 都有共性字段
- 但不同组件的
targetRequest、targetResponse内部内容差异很大
例如:
- Redis 更关心 key、命令、值
- MyBatis 更关心 SQL、参数、结果集
- Dubbo 更关心接口名、方法签名、参数列表、返回对象
- Elasticsearch 更关心 DSL 和 hits
这类数据天然更适合文档型存储,而不是硬塞进高度规范化的关系表结构。
4.3 默认会过期,不是永久保存
官方 UI 文档特别提到:
- 默认只保留最近 4 天录制 case
- 过期数据会自动删除
- 本质上是通过 Storage Service 侧的 TTL 配置控制
这说明 AREX 默认把录制数据当成:
- 可消费的测试资源
- 而不是长期归档的审计日志
因此如果团队要长期保留某批 case,不能只靠默认配置。
4.4 一次回放时 Redis 在做什么
很多人会以为 Redis 只是平台的普通缓存,但在 AREX 体系里,它承担的是回放过程的性能加速角色。
官方文档提到:
- Redis 负责缓存 mock 数据和比较结果
可以把它理解成:
- MongoDB 负责权威存储
- Redis 负责本轮回放的高频命中和中间结果缓存
五、这些数据怎么查看
用户最直接能看到录制数据的地方,其实不是 MongoDB,而是 AREX UI。
5.1 在 UI 里怎么看录制 case
官方流量回放文档给出的查看路径大致是:
- 进入
Replay页面 - 选择已经接入 Agent 的应用
- 进入某个接口
- 再点进某条具体 case
进入 case 详情后,页面会展示两部分信息:
- 左侧:录制过程中的请求内容,包括主入口请求、动态类请求、外部依赖调用请求
- 右侧:对应的响应内容
下图为 AREX Replay 页面录制用例列表截图:
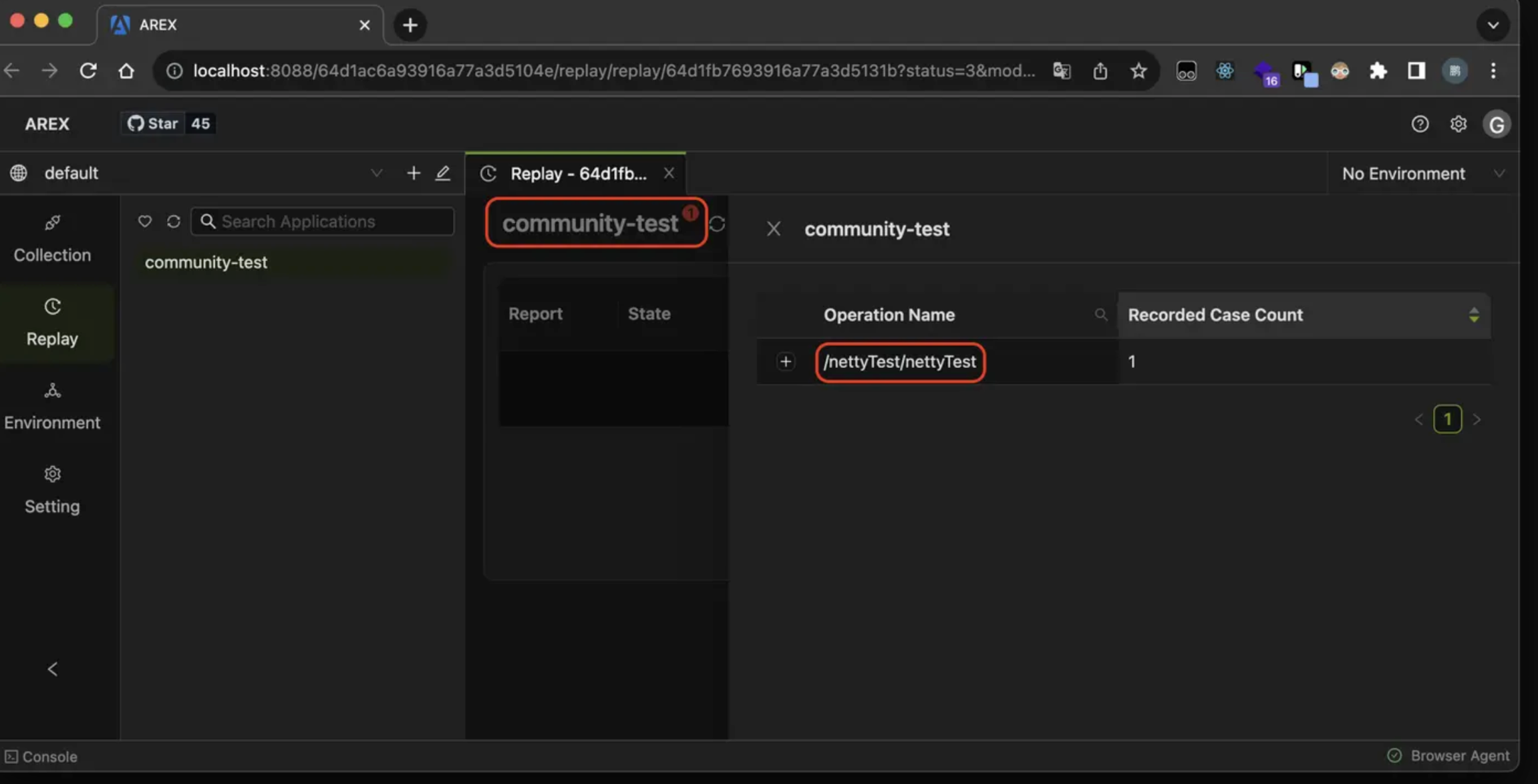
这其实正对应前面说的数据模型:
- 左边更接近
targetRequest - 右边更接近
targetResponse
5.2 在 UI 里能看到什么层次的信息
通常能看到:
- 主入口请求
- 各依赖调用的请求
- 各依赖调用的响应
- 最终主响应
如果一条 case 比较复杂,你看到的就不是“一条接口数据”,而是一个按依赖展开的调用快照列表。
从学习角度讲,这一点非常重要,因为它意味着:
AREX 的最佳使用姿势不是把它当成“接口测试平台”,而是把它当成“请求执行剖面快照查看器 + 回放器”。
5.3 页面里看到的是不是原始明文
不一定。
官方文档已经注明:
- 部分 request/response body 是压缩后再 base64 编码保存的
这意味着你在页面里看到的内容,有时需要额外处理才能恢复为直观结构。
因此如果要做深度排查,常见顺序通常是:
- 先在 UI 里确认主链路和依赖快照是否齐
- 再看具体 body 是否需要解码或解压
- 如果仍然不清楚,再下沉到存储层或源码层排查
5.4 强制录制时怎么看 recordId
AREX 支持强制录制一个指定请求。
常见方式是:
- 请求头加
arex-force-record: true
请求成功后,响应头里会返回:
arex-record-id
这个 recordId 就是后续定位这条 case、保存它、回放它的主键。
六、AREX Agent 为什么能录、又为什么能回放
这部分才是机制核心。
6.1 录制能力来自 Java Agent
AREX 的第一性原理不是 HTTP 代理,不是 sidecar,也不是 SDK 埋点,而是:
- 用
-javaagent把 Agent 挂到 JVM 启动过程 - 用
Instrumentation拿到类增强能力 - 用
ByteBuddy给目标类织入 Advice
这意味着它能在”方法真正执行前后”插入自己的逻辑,而不要求业务代码主动调用某个 SDK。
下图展示了 AREX Agent 录制与回放的整体流程(来自官方技术文章):
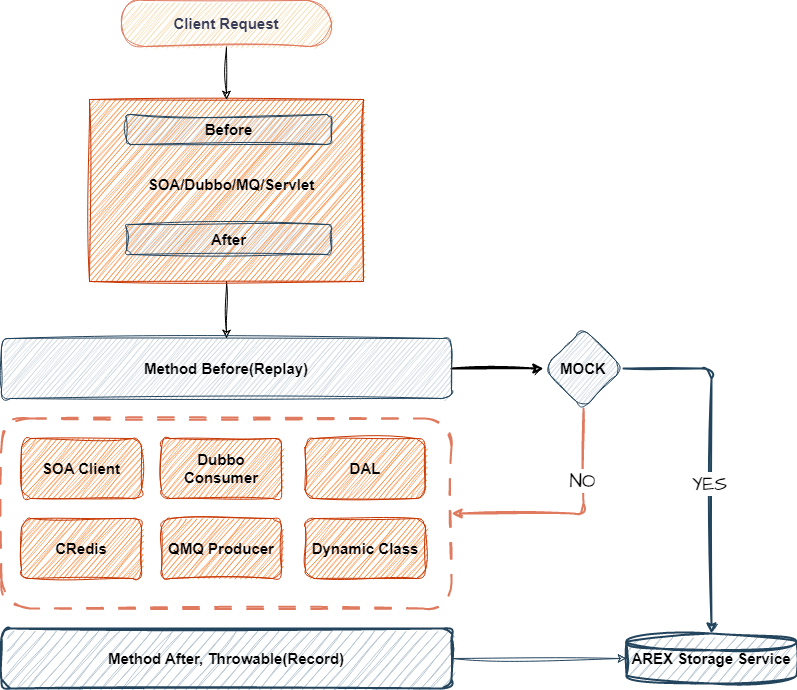
图中展示了一次请求的调用链:入口(Entry)和依赖调用(Dependencies)通过
RecordId串成一条完整的录制 case。录制时拦截并保存请求/响应;回放时拦截内部调用,直接返回录制期数据。
6.2 回放能力来自“拦截后短路真实调用”
它为什么能回放?
因为被织入 Advice 的方法,在运行时不只会判断“要不要录制”,还会判断“当前是不是回放态”。
如果是回放态,Advice 不一定继续执行原始逻辑,而是可以:
- 根据当前上下文找到对应的 mocker
- 取出已录制的
targetResponse - 直接作为方法返回值交还给业务代码
所以回放的本质不是“重新访问下游”,而是:
在应用内部,把原本应该发出去的下游调用拦住,然后用录制期的结果替代。
6.3 它为什么能把整条链串起来
因为入口点和内部依赖调用都共享上下文。
AREX 的技术文章里提到:
- 录制过程会通过
recordId把入口和依赖调用串起来 - 对多线程和异步框架,会通过线程增强传递上下文
这其实是在解决一个比“拦截”更难的问题:
- 不是能不能拦到某个 Redis 调用
- 而是怎么知道这次 Redis 调用属于哪条 HTTP 请求
如果没有上下文传播,录到的数据只会是一堆孤立碎片。
6.4 多线程和异步为什么是重点难点
因为 Java 业务里很常见:
- 线程池异步查询
CompletableFuture- Reactor
- Dubbo 线程切换
- 回调风格 HTTP 客户端
官方技术文章里提到,AREX 通过线程包装的方式传递上下文。简化理解就是:
1
2
3
4
executor.execute(runnable);
// 被增强后变成近似这样
executor.execute(ContextAwareRunnable.wrap(runnable));
被包装后的 Runnable 在构造时捕获当前上下文,在执行时再把上下文恢复到子线程里。
这一步非常关键,因为没有它,recordId 会在线程切换后丢失。
AREX 支持的线程/异步框架
| 类别 | 支持项 |
|---|---|
| 基础线程 | Thread、ThreadPoolExecutor、ForkJoinTask |
| Future 体系 | FutureTask、FutureCallback、CompletableFuture |
| 响应式 | Reactor Framework |
| RPC 线程切换 | Dubbo Provider/Consumer 线程传播 |
| 异步 HTTP | Apache AsyncClient callback |
6.5 本地缓存和时间为什么也要被录
如果只录外部调用,不录本地时间和本地缓存,回放成功率会大幅下降。
原因很直接:
- 时间不同,业务分支可能不同
- 本地缓存不同,执行路径可能不同
例如:
- 录制时
Caffeine命中 - 回放时本地缓存为空
- 代码就可能从“直接返回缓存”变成“回源查库”
这样即使数据库 mock 没问题,整条链路的执行顺序也变了。
所以 AREX 才会支持:
- 时间类 mock
- 动态类配置
- 本地缓存相关录制与替换
七、从源码看,AREX Agent 是怎么启动起来的
这一段建议按真正的启动链来读。
下图为 AREX Agent 启动接入流程(来自官方技术文章):
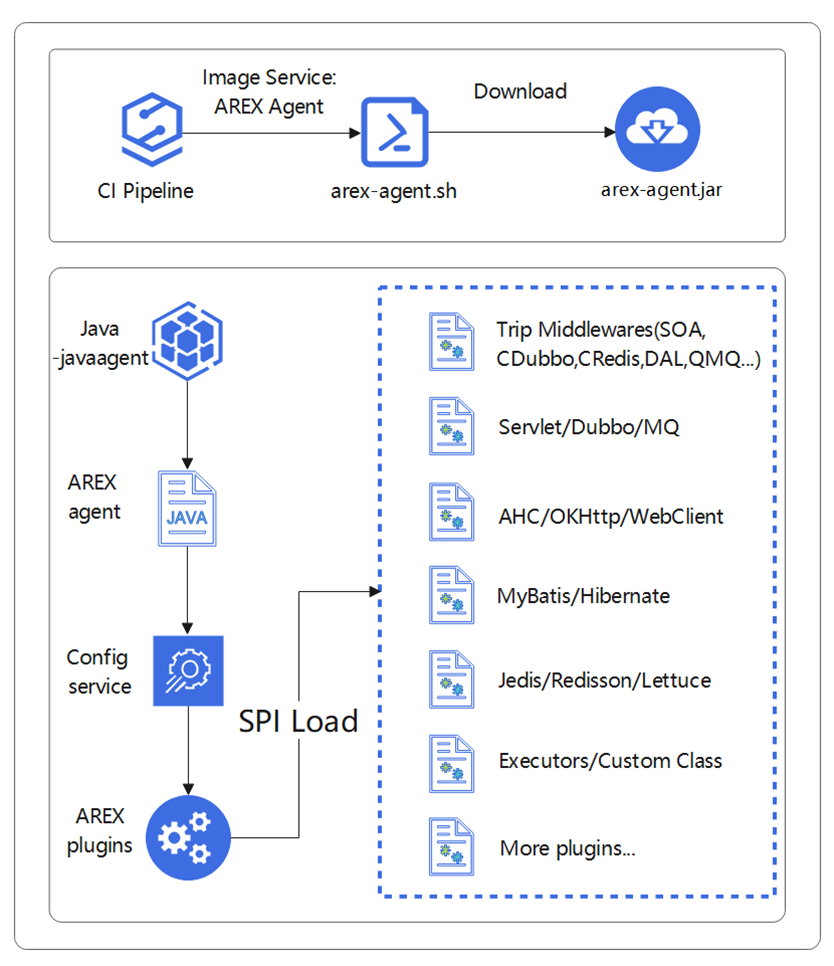
从 CI Pipeline 选择 Agent → 打入启动脚本 → 拉取 agent jar → JVM 调用 premain → 拉配置并按需加载插件 → 字节码增强生效。
启动链关键跳转一览
| 跳转 | 入口类/方法 | 职责 |
|---|---|---|
| 第一跳 | ArexJavaAgent.premain() |
JVM 入口,声明于 MANIFEST.MF |
| 第二跳 | premain → agentmain → init |
执行 installBootstrapJar() 挂入底层 ClassLoader |
| 第三跳 | AgentInitializer.initialize() |
创建 AgentClassLoader、加载扩展 jar、实例化 Installer |
| 第四跳 | InstrumentationInstaller.install() |
用 ByteBuddy AgentBuilder 遍历模块做字节码增强 |
7.1 第一跳:Premain-Class
AREX 是标准 Java Agent,因此打包时会在 MANIFEST.MF 里声明:
Premain-Class
对应的入口类是:
io.arex.agent.ArexJavaAgent
这意味着 JVM 启动应用时,只要看到 -javaagent 参数,就会优先调用这个类的 premain。
7.2 第二跳:premain -> agentmain -> init
官方源码分析文章给出的启动过程是:
premainagentmaininit
也就是说,AREX 的启动入口和普通 Java Agent 一样,先进入 Agent 主类,再进入初始化流程。
7.3 第三跳:把 bootstrap 代码挂进更底层 ClassLoader
源码分析里提到一个很关键的动作:
installBootstrapJar()
它会把包含 AgentInitializer 的 jar 追加到 Bootstrap ClassLoader 的搜索路径中。
这一层的意义是:
- 某些基础能力必须在更底层类加载器可见
- 否则应用类加载器在运行 Advice 时可能找不到 Agent 需要的类
7.4 第四跳:AgentInitializer.initialize()
AgentInitializer 这层做的事情,从源码可以概括成:
- 初始化日志目录
- 查找
extensions/目录下的扩展 jar - 创建
AgentClassLoader - 记录
Instrumentation和 agent 文件 - 通过自定义类加载器加载
InstrumentationInstaller - 把 agent jar 和 extension jar 交给 Advice 类收集器
- 调用 installer 的
install()
这一层有两个非常重要的设计点:
- 自定义类加载器隔离 Agent 和业务应用依赖
- 扩展 jar 机制允许后续按插件补充增强能力
7.5 为什么要自己做 AgentClassLoader
因为 Agent 往往依赖很多自己的库,比如:
- ByteBuddy
- 序列化库
- 比对库
- 各类运行时支持类
如果直接和业务应用共用类路径,很容易发生:
- 版本冲突
- 类覆盖
NoClassDefFoundErrorLinkageError
所以 AREX 的做法是:
- Agent 自己用一套类加载器
- 需要给应用使用的 Advice 相关字节码,再按受控方式注入应用类加载器可见范围
这就是为什么官方文章专门把”ClassLoader 隔离与互通”单独拿出来讲。
下图为 AREX Agent ClassLoader 隔离模型(来自官方技术文章):
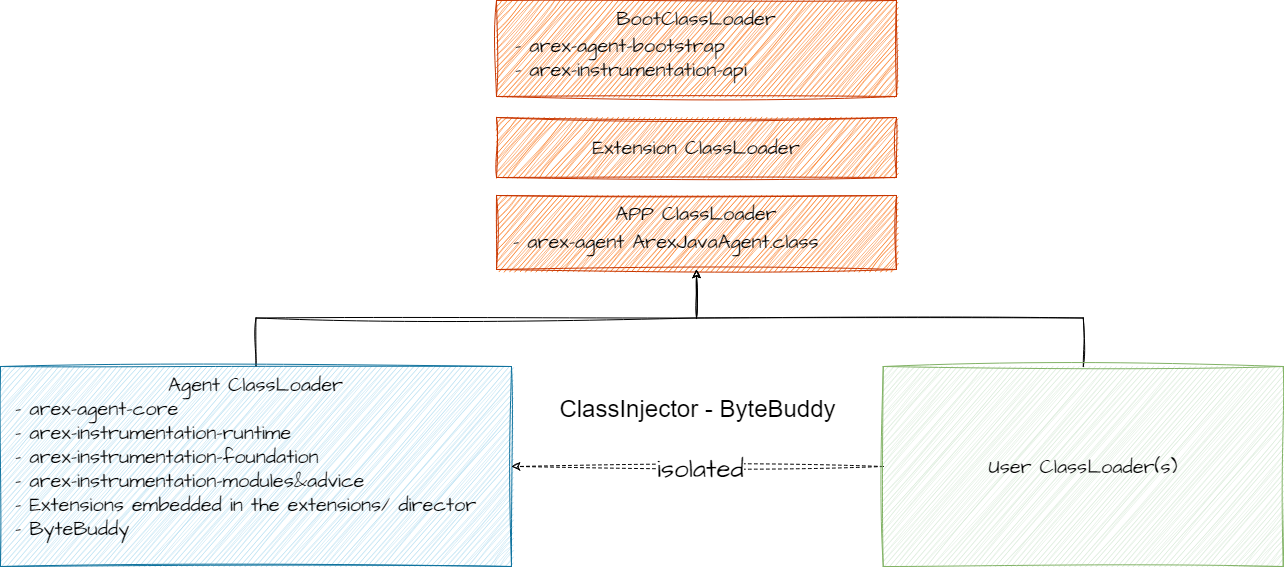
AgentClassLoader加载 Agent 核心代码,通过ByteBuddy ClassInjector将录制/回放所需字节码注入应用 ClassLoader,从而既保证隔离又保证运行时可见。
八、真正做增强的是谁
真正把录制和回放逻辑织进目标类的,不是 ArexJavaAgent,而是后面的安装器。
8.1 InstrumentationInstaller 是增强总装配器
从源码看,InstrumentationInstaller 做的事情可以概括为:
- 构建
ByteBuddy AgentBuilder - 通过 SPI 加载所有
ModuleInstrumentation - 遍历每个模块里的
TypeInstrumentation - 再遍历具体的
MethodInstrumentation - 把 Advice 织进目标方法
这说明 AREX 的增强机制不是“写死在一个大类里”,而是模块化组织的。
8.2 三层抽象:Module / Type / Method
AREX 对增强点做了三层抽象:
ModuleInstrumentationTypeInstrumentationMethodInstrumentation
可以这样理解:
ModuleInstrumentation:定义一个组件模块,例如 servlet、dubbo、redis、mybatisTypeInstrumentation:定义这个模块要匹配哪些类MethodInstrumentation:定义这些类里哪些方法要织入 Advice
三层抽象对照表
| 抽象层 | 职责 | 示例(Servlet 模块) |
|---|---|---|
ModuleInstrumentation |
声明一个完整组件模块 | FilterModuleInstrumentationV3 |
TypeInstrumentation |
指定该模块要匹配的类 | FilterInstrumentationV3(匹配 javax.servlet.Filter) |
MethodInstrumentation |
指定要织入的方法与 Advice | 匹配 doFilter,织入 FilterAdvice |
这种设计很适合做组件矩阵式扩展,因为每新增一个中间件支持,核心不是改一堆 if-else,而是新增一个模块实现。
8.3 ByteBuddy 在这里具体做了什么
从 InstrumentationInstaller 的实现看,核心是这类动作:
- 根据 matcher 找到目标类
- 根据 method matcher 找到目标方法
- 通过
Advice把前置和后置逻辑织进去
最终效果是:
- 方法进入时执行
OnMethodEnter - 方法退出时执行
OnMethodExit - 必要时还能替换、包装或短路原方法行为
这就是 AREX 能录制和回放的技术基础。
下图为 AREX Agent 对 SOA Client 同步调用做字节码增强的示例(来自官方技术文章):

左侧为原始调用逻辑,右侧为 Agent 增强后的逻辑。在
OnMethodEnter阶段判断录制/回放态,录制态保存请求响应,回放态直接从存储取出已录制响应返回。
8.4 为什么它支持那么多组件
因为 arex-agent 主工程本身就是由很多 instrumentation 模块拼出来的。
从依赖结构看,AREX 把不同组件拆成独立模块,例如:
- servlet
- executors
- mybatis
- redis
- dubbo
- http client
- mongo
- spring cache
- elasticsearch
这意味着“支持一个组件”本质上就是:
- 为这个组件写一套对应的 matcher 和 advice
九、录制阶段到底发生了什么
9.1 入口点先创建上下文
以 Servlet 为例,官方源码分析里提到会增强:
javax.servlet.Filter#doFilter
这意味着 HTTP 请求一进应用,AREX 就有机会在最靠前的位置做这些事:
- 清理旧上下文
- 创建新上下文
- 生成 trace / record 关联信息
- 初始化当前请求的时间 mock 状态
因此录制的第一步不是“马上写 MongoDB”,而是先把这次请求纳入一个受控上下文。
9.2 依赖调用在执行前后被拦截
当业务代码继续往下执行时,如果碰到被支持的组件:
- Redis
- MyBatis
- Dubbo
- OpenFeign / HttpClient
- Elasticsearch
- 动态类
- 时间类
对应 Advice 就会在方法前后记录:
- 调用参数
- 调用结果
- 异常信息
- 所属上下文
这些信息最终会被组织成前面说的 ArexMocker。
9.3 最终主响应也要被记录
入口点不是只负责开头建上下文,结束时还要把主响应补齐。
这样一条 case 最终才完整:
- 主入口请求
- 所有依赖请求与响应
- 主入口响应
如果缺最后一步,AREX 只能回放依赖,无法做“最终响应差异比对”。
9.4 录制时串联靠 recordId
官方技术文章明确提到:
- 录制过程通过
recordId把入口和依赖调用串起来
所以从语义上说,recordId 不是“这个 HTTP 请求的 ID”这么简单,它更像:
- 一次完整录制快照事务号
十、回放阶段到底发生了什么
下图为 AREX UI 中开始回放的操作界面(来自官方文档):
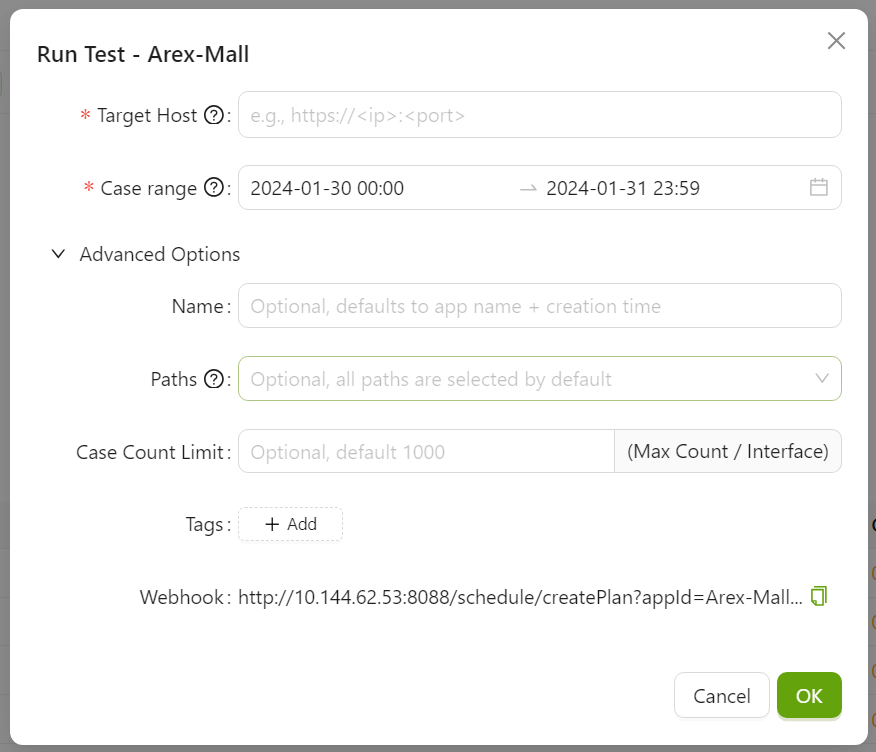
指定目标回放地址(Target Host)、用例时间范围(Case Range),点击 Start Replay 即可触发调度服务按录制 case 逐条回放。
10.1 回放的入口不是”录制文件重放”,而是重新发请求
AREX 的回放不是把 JVM 状态整个倒回去,而是:
- 调度服务拿到某条
recordId - 取回主入口请求
- 把同样的请求重新发到目标验证环境
所以主流程依然是真实执行当前代码。
10.2 但内部依赖不会真的再打出去
区别就在这里。
当目标环境里的业务代码再次执行到 Redis、Dubbo、MyBatis、Elasticsearch 等依赖点时,Agent 会判断当前请求处于回放态。
如果是回放态,就不会真的执行业务下游调用,而是:
- 根据
recordId + 当前调用特征找 mocker - 命中后取出
targetResponse - 直接把响应对象返回给当前方法
因此从业务代码角度看,它以为自己调了下游;
但从系统真实行为看,这次调用其实已经被 AREX 短路成内存态或本地态 mock 返回。
10.3 回放结果最终比对的是谁
最终至少会比两类东西:
- 录制时的主响应
- 回放时当前代码跑出来的主响应
必要时也会结合依赖调用层面的信息做差异分析。
下图为 AREX UI 中回放差异场景聚合视图(来自官方文档):
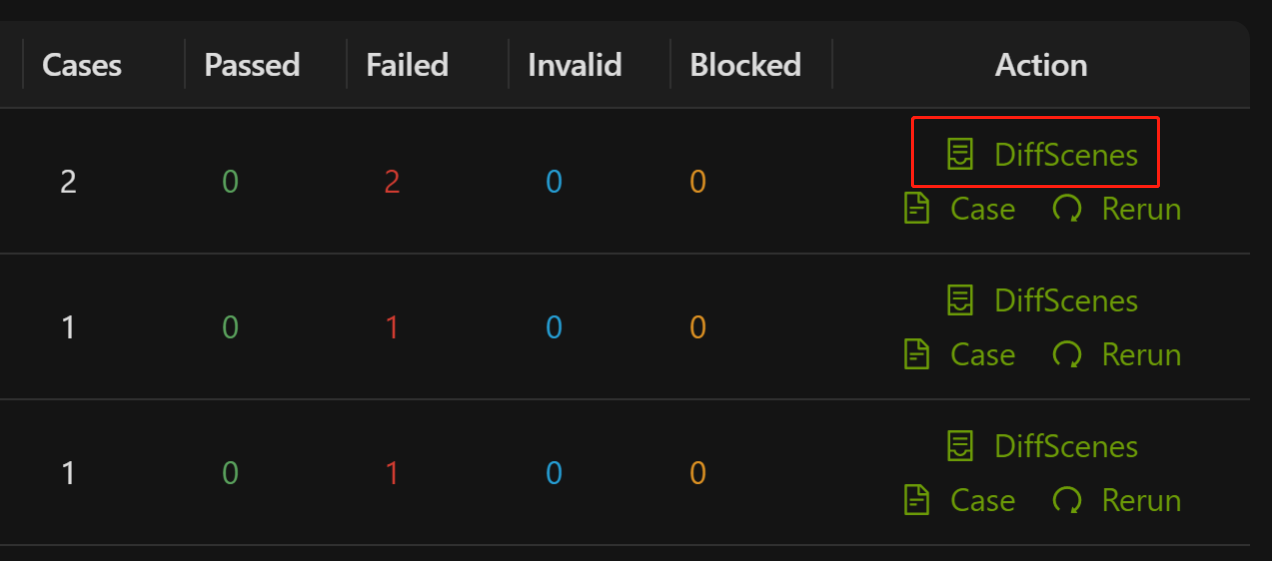
页面左侧按 Mock 类型和差异类型聚合展示差异场景;右侧可深入对比录制基线与回放结果的具体差异节点,蓝色高亮表示 value diff,橙色高亮表示 additional node。
所以 AREX 关心的核心问题其实是:
在“同一份入口请求 + 同一套依赖快照”下,新代码的行为和旧基线相比有没有变化。
10.4 replayId 在这里的意义
replayId 的作用就是把某一轮回放过程中的:
- 主入口请求
- 内部依赖命中情况
- 新主响应
- 差异结果
串成一组运行结果。
所以:
recordId对应基线replayId对应验证轮次
十一、用一个 Java 真实场景把数据和机制串起来
下面用一个更贴近 Java 业务的场景来把前面的抽象概念落地。
11.1 场景定义
假设有个 order-query-service,技术栈如下:
Spring BootSpring Cloud OpenFeignDubboRedisTemplateCaffeineElasticsearch ClientMyBatis
它暴露一个接口:
GET /api/orders/detail?userId=10&orderId=2001
执行链大致是:
- 先查
Caffeine - 未命中查
Redis - 再查
MyBatis - 查
Dubbo履约域 - 查
Feign风控服务 - 查
Elasticsearch搜索补充信息 - 聚合返回订单详情
11.2 如果这条请求被录制,会生成什么
结构上可以近似理解成下面这样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
recordId = AREX-20260621-0001
MainEntry
- method: GET
- path: /api/orders/detail
- query: userId=10&orderId=2001
- response: OrderDetailVO
Mocker #1
- categoryType: DYNAMIC_CLASS
- operationName: OrderLocalCache.get
- targetRequest: key=user:10:order:2001
- targetResponse: cached order summary
Mocker #2
- categoryType: REDIS
- operationName: RedisTemplate.opsForValue.get
- targetRequest: key=order:detail:2001
- targetResponse: json payload
Mocker #3
- categoryType: DATABASE
- operationName: OrderMapper.selectById
- targetRequest: sql + params
- targetResponse: row data
Mocker #4
- categoryType: DUBBO
- operationName: FulfillmentQueryFacade.query
- targetRequest: orderId=2001
- targetResponse: shipment list
Mocker #5
- categoryType: HTTP_CLIENT
- operationName: RiskClient.querySummary
- targetRequest: userId=10, orderId=2001
- targetResponse: risk summary
Mocker #6
- categoryType: ELASTICSEARCH
- operationName: SearchExtraClient.search
- targetRequest: DSL
- targetResponse: hits/aggregations
如果你从“数据模型”角度看这条 case,会发现它已经足够回答很多问题:
-
为啥能本地复现?
因为依赖快照都在。 -
为啥能避免真实调用下游?
因为每个依赖点都已经有targetResponse。 -
为啥能看出改动影响的是缓存、搜索还是聚合逻辑?
因为主响应之外,还能下钻看到每个依赖点。
11.3 如果这条请求被回放,会发生什么
假设改动后重新回放:
- 调度服务用原始入口请求再次访问测试环境
- Servlet 入口 Advice 检测到这次是回放
- 业务代码查
Caffeine时,命中动态类 mock 数据 - 查 Redis/MyBatis/Dubbo/Feign/Elasticsearch 时,都由 Agent 返回已录制的
targetResponse - 新代码完成聚合
- 返回新的
OrderDetailVO - 与录制期基线响应做差异比对
这时如果发现:
fulfillmentProgress从"2/3"变成null
你就可以快速判断:
- 不是下游 Dubbo 变了
- 因为 Dubbo 的 mock 数据本身就是录制期固定快照
- 问题大概率发生在当前服务的新聚合逻辑里
这就是回放验证比普通联调更有价值的地方。
十二、AREX 在 Java 技术栈里真正容易卡住的点
12.1 Spring Cloud 的问题不在“支不支持”,而在“具体走什么实现”
很多人说自己的系统是 Spring Cloud,但这还不够细。
真正决定 AREX 是否好接的是:
- 入口是不是
Servlet - 出站 HTTP 是不是
Feign / RestTemplate / WebClient - 熔断、线程隔离是不是改变了上下文传播
所以落地前一定要把生态词拆成组件词。
12.2 Dubbo 的问题不只是调用本身,还有线程与协议
Dubbo 在很多公司都有自定义过滤器、自定义协议、泛化调用或者线程切换逻辑。
这时要重点确认:
- Provider 和 Consumer 哪一侧被拦
- 自定义协议有没有脱离官方默认增强点
- 线程切换后
recordId是否仍能透传
12.3 Caffeine 的问题往往不是“支不支持”,而是“本地态不一致”
本地缓存和 Redis 最大的区别是:
- 它不天然可共享
- 它更依赖当前 JVM 的运行时状态
所以 AREX 才需要引入动态类配置,用“方法级录制回放”去模拟缓存读取,而不是试图把整块本地内存复制过去。
12.4 Elasticsearch 的问题往往出在 DSL 与结果后处理
搜索链路里最常见的回归点不是连接失败,而是:
- DSL 改了一个过滤条件
- 排序权重顺序变了
- 高亮字段变了
- hits 后处理逻辑改坏了
AREX 在这里的价值,主要体现在”用真实查询样本回放二次加工逻辑”。
Java 技术栈落地风险点速查
| 组件 | 核心风险 | 落地前确认点 |
|---|---|---|
| Spring Cloud | 生态词 ≠ 组件词 | 入口是 Servlet?出站走 Feign/RestTemplate?上下文是否被 Hystrix 线程隔离打断? |
| Dubbo | 线程切换 + 自定义协议 | Provider/Consumer 哪侧拦截?自定义 filter 是否丢 context?泛化调用是否在增强范围? |
| Caffeine | 本地态录制与回放不一致 | 是否配置了动态类?缓存 key 是否稳定?命中/未命中的执行路径差异是否可控? |
| Elasticsearch | DSL 与后处理逻辑 | DSL 变更后排序/过滤/高亮是否影响回放通过率?hits 后处理逻辑能否被 mocker 覆盖? |
| 异步框架 | recordId 跨线程丢失 |
用的是 ThreadPoolExecutor 还是自定义线程?Reactor 版本是否在支持列表? |
十三、如果要读源码,最值得看的模块顺序
如果只是泛读仓库,很容易迷路。更高效的顺序通常是:
源码阅读路线总览
| 阶段 | 模块 | 核心关注点 | 回答的问题 |
|---|---|---|---|
| ① 入口与装配 | arex-agent / arex-agent-bootstrap / arex-agent-core |
ArexJavaAgent → AgentInitializer → InstrumentationInstaller |
谁启动?谁装配? |
| ② 运行时上下文 | arex-instrumentation-api |
ArexContext、配置类、运行时模型 |
recordId 怎么传?回放态怎么判? |
| ③ 组件增强模块 | 各 arex-instrumentation-* |
匹配类、拦截方法、enter/exit 逻辑 | 每个组件怎么被录?怎么被回放? |
| ④ 存储协作层 | arex-storage |
MockItem、MainEntry、持久化策略 |
录完发给谁?怎么分层存? |
13.1 先看入口与装配
arex-agentarex-agent-bootstraparex-agent-core
重点理解:
ArexJavaAgentAgentInitializerInstrumentationInstaller
这三层分别回答:
- 谁起进程入口
- 谁做类加载与扩展初始化
- 谁真正把增强模块装配进去
13.2 再看运行时上下文
arex-instrumentation-api
重点看:
ArexContext- 配置类
- 运行时模型
这一层负责解释:
recordId怎么跟着请求走- 回放态怎么判断
- 当前线程上下文怎么保存
13.3 再看具体组件增强模块
按自己最关心的技术栈看对应 instrumentation:
- servlet
- executors
- redis
- mybatis
- dubbo
- http client
- elasticsearch
阅读重点不是把每行代码抠完,而是看三个问题:
- 匹配了哪个类?
- 拦了哪个方法?
- 在 enter/exit 阶段做了什么?
13.4 最后看存储协作层
arex-storage
重点看:
MockItemMainEntry- 持久化与缓存职责
这一层负责回答:
- Agent 录完之后把什么对象发给谁
- 这些对象在存储侧如何分层
- 为什么
MongoDB + Redis是默认组合
十四、我现在对 AREX Agent 的理解
如果把这篇笔记收成几个更工程化的判断,可以概括为:
14.1 它最核心的能力不是“录流量”,而是“录执行上下文”
只录入口流量不难,真正难的是把依赖调用、时间、本地缓存、异步线程上下文一起带上。
AREX 的价值,主要就体现在这一层。
14.2 它最关键的抽象不是“接口 case”,而是“以 recordId 为中心的一组 mocker 资源”
一旦理解这一点,很多设计都会变得顺:
- 为什么需要
recordId - 为什么还有
replayId - 为什么有
MainEntry - 为什么依赖调用也要被建模成统一对象
14.3 它最难做好的不是字节码增强,而是上下文一致性
真正决定回放质量的,不只是能不能拦到某个组件,而是:
- 上下文能不能跨线程传递
- 本地缓存和时间能不能对齐
- 动态字段能不能降噪
- 依赖调用能不能稳定匹配到正确录制对象
14.4 它更像“真实流量驱动的回归执行引擎”,不是一把万能测试锤子
所以最适合它的使用位置通常是:
- 复杂依赖服务的回归验证
- 线上问题本地复现
- 重要变更前后的真实流量比对
而不是替代:
- 单元测试
- 集成测试
- 压测
- 业务验收
十五、最后总结
回到开头提的两个关键问题,现在可以给出更具体的答案。
15.1 回放的数据什么结构、怎么存、怎么看
可以概括为:
- 结构上:不是单条请求响应,而是
MainEntry + 多个 ArexMocker + replay result + compare result - 主键上:用
recordId串录制基线,用replayId串某轮回放 - 内容上:每个 mocker 至少包含
categoryType、targetRequest、targetResponse、operationName等关键字段 - 存储上:默认由
AREX Storage Service落到MongoDB,并配合Redis做回放缓存 - 查看上:优先在 UI 的
Replay页面看 case 详情,左边请求、右边响应,必要时处理 base64/压缩内容
15.2 AREX Agent 机制是什么,为什么能录制回放
也可以概括为:
- 启动机制:
-javaagent触发premain - 增强机制:
Instrumentation + ByteBuddy - 装配机制:
AgentInitializer + InstrumentationInstaller + SPI 模块化 instrumentation - 录制机制:在入口和依赖调用的 Advice 中记录请求、响应、异常与上下文
- 串联机制:用
recordId和线程上下文把整条链串起来 - 回放机制:在回放态拦截内部依赖调用,直接返回录制期
targetResponse
如果后面继续写,这个主题最值得再展开三篇:
AREX Agent运行时上下文与多线程传播AREX Agent具体组件增强点逐个拆读AREX Storage的模型、缓存与差异比对链路