这篇笔记的目标是把 JVM 里最容易“背概念但没串起来”的几个主题重新梳理一遍:运行时数据区、对象分配、分代回收、G1 的 Region 化设计,以及 GC 为什么需要 Safepoint。
重点不是堆砌术语,而是把“内存布局为什么这样设计”“G1 到底比传统分代灵活在哪里”“哪些说法只是便于理解、哪些才是 HotSpot 下更准确的表述”讲清楚,便于继续往 GC 日志分析和参数调优深入。
参考资料:
The Java Virtual Machine Specification - Run-Time Data Areas
Oracle HotSpot GC Tuning Guide - Garbage-First (G1) Garbage Collector
Oracle HotSpot GC Tuning Guide - Garbage-First Garbage Collector Tuning
[TOC]
一张图先建立整体视角
1
2
3
4
5
6
7
8
9
10
┌──────────────────────────────────────────────────────────────────────┐
│ JVM 整体视图 │
├────────────────────┬────────────────────┬────────────────────────────┤
│ 线程共享 │ 线程私有 │ 执行与回收 │
├────────────────────┼────────────────────┼────────────────────────────┤
│ • 堆 Heap │ • 程序计数器 PC │ • 解释器 │
│ • 方法区 MethodArea │ • Java 虚拟机栈 │ • JIT 编译器 │
│ • 运行时常量池 │ • 本地方法栈 │ • GC / 并发标记 / 压缩整理 │
│ │ │ • Safepoint / Saferegion │
└────────────────────┴────────────────────┴────────────────────────────┘
如果把 JVM 看成一套“运行 Java 程序的操作系统内核”,那这篇笔记主要回答四个问题:
- 对象、类元数据、栈帧分别放在哪里。
- 为什么 GC 会天然偏爱“分代”这件事。
- G1 为什么用 Region 取代固定物理分区。
- GC 为什么不能随时打断线程,而要等到 Safepoint。
运行时数据区
线程共享与线程私有
| 区域 | 是否线程共享 | 主要内容 | 典型异常或关注点 |
|---|---|---|---|
| 程序计数器 | 否 | 当前线程下一条将要执行的字节码位置 | 几乎很少成为排障重点 |
| Java 虚拟机栈 | 否 | 栈帧、本地变量表、操作数栈、返回地址 | StackOverflowError |
| 本地方法栈 | 否 | Native 方法调用所需的数据 | 依赖具体实现 |
| 堆 | 是 | 对象实例、数组,GC 的主战场 | OutOfMemoryError: Java heap space |
| 方法区 | 是 | 类元数据、静态变量、运行时常量池等 | JDK 8+ 常关联 Metaspace |
| 运行时常量池 | 是 | Class 文件常量池在运行期的表现形式 | 符号引用解析、常量缓存 |
一个容易混淆但必须说清的点
方法区 是 JVM 规范层面的逻辑区域,Metaspace 是 HotSpot 在 JDK 8 之后对方法区的具体实现方式之一,二者不是完全同义词。
可以简单记成:
- 规范里讲的是“方法区”。
- HotSpot 实现里,类元数据通常放在“元空间”。
- 面试或笔记里如果直接把“方法区 = 元空间”,严格来说不够准确,但在 HotSpot 语境下通常能沟通。
栈帧为什么重要
GC、异常处理、方法调用返回,本质上都离不开栈帧。每次方法调用都会创建一个新的栈帧,典型包含:
- 局部变量表
- 操作数栈
- 动态链接信息
- 方法返回地址
- 一些附加的实现信息
这也是为什么 GC 做根枚举时,非常关心“线程当前是否处于可安全观察的状态”。
对象到底分配到哪里
默认路径:优先分配在 Eden
绝大多数普通对象,都会先分配在新生代的 Eden。原因很简单:
- 大多数对象很快就死掉。
- 把它们先放在年轻区域,回收成本最低。
- Minor GC 只要处理年轻代,就能回收大量垃圾。
1
2
3
4
5
6
7
8
9
new Object()
│
├─ 通常进入 Eden
│
├─ 经历一次 Young GC 后仍存活 -> 进入 Survivor
│
├─ 多次存活、年龄达到阈值 -> 晋升 Old
│
└─ 如果是 G1 下的超大对象 -> 直接走 Humongous 路径
为什么要有 Survivor
Survivor 的作用不是“再存一份对象”,而是充当一个缓冲区,让 JVM 不要因为对象只多活一两次 GC,就过早晋升到老年代。
如果没有 Survivor,会出现两个问题:
- 刚刚创建但短期内仍存活的对象会过早进入老年代。
- 老年代膨胀更快,导致 Major GC / Mixed GC 压力上升。
大对象分配
这里最容易出现“记住了一半”的情况。
先说结论:
- 在传统分代收集器语境里,大对象常被描述为“可能直接进入老年代”。
- 在 G1 里,超过 Region 一半大小的对象会被认定为 Humongous 对象,直接分配到一组连续的 Humongous Regions 中。
- Humongous Region 在 HotSpot 文档里属于 old generation 的一部分语义范畴,不能简单写成“Humongous 不属于 Old”。更准确的说法是:它是 G1 中对大对象的特殊 old-region 布局方式。
关于 -XX:PretenureSizeThreshold
这个参数常被拿来解释“大对象直接进老年代”,但要注意边界:
- 它属于传统分代收集器时代常见的思路。
- 是否生效,取决于具体收集器实现。
- 在 G1 语境下,不应该再拿这个参数作为理解大对象分配的核心入口。
更适合记住的是:G1 的大对象判断标准是 Region 视角,而不是单纯沿用旧式新生代/老年代物理边界思维。
为什么分代回收是合理的
本质来自分代假说
分代回收并不是“人为把堆切几块显得高级”,而是因为对象生命周期分布非常不均匀。
可以粗略理解为:
- 大多数对象朝生夕死。
- 少量对象会长期存活。
- 不同寿命对象,用同一种回收策略并不划算。
1
2
3
4
5
6
7
对象数量
^
| ███████████████████ 大量短命对象
| ███
| █
| █ 少量长寿对象
+----------------------------------> 存活时间
分区的真正意义
常见说法是“堆分成 Eden、Survivor、Old”,但更底层的理解应该是:
- 这是在按照对象年龄和存活概率进行分层管理。
- 年轻对象回收要快,宁可更频繁。
- 长寿对象回收要稳,避免反复扫描。
也就是说,分代不是目的,降低平均回收成本才是目的。
传统分代收集器怎么理解
固定物理分区
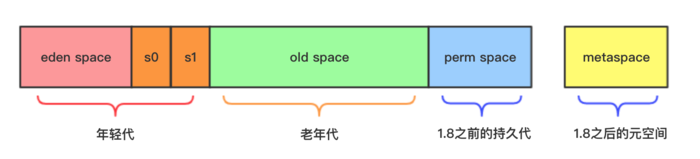
传统收集器可以先按“固定物理边界”来理解:
1
2
3
4
5
6
7
┌──────────────────────────────────────┐
│ Heap │
├──────────────────────────────────────┤
│ Young = Eden + Survivor0 + Survivor1 │
├──────────────────────────────────────┤
│ Old │
└──────────────────────────────────────┘
这种方式的优点是模型简单,缺点也很明显:
- 年轻代和老年代边界固定。
- Survivor 比例相对刚性。
- 工作负载变化时,容易出现一边紧张、一边空闲。
- CMS 一类基于标记-清除的老年代回收器,还会面临碎片问题。
复制存活对象时的限制
传统年轻代复制,通常在两个 Survivor 之间切换:
1
Eden + From Survivor --复制--> To Survivor
这个模型的问题不是不能工作,而是灵活性不足:
- 目标 Survivor 空间是预先切好的。
- 即使堆里别处有空闲,也不一定能直接拿来当 Survivor。
- 一旦存活对象超出预估,就会发生过早晋升甚至担保失败压力。
G1 收集器的核心变化
先记一句话
G1 不是取消分代,而是把“固定物理分代”改成了“基于 Region 的逻辑分代”。
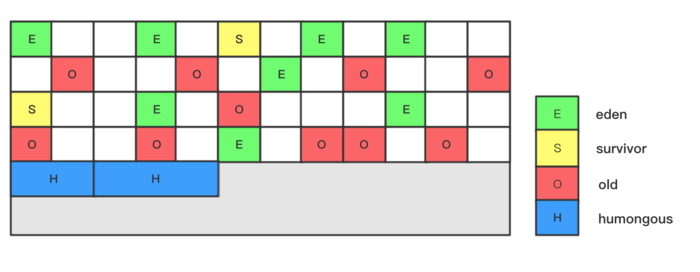
Region 化之后,堆长什么样
1
2
3
4
5
┌─────┬─────┬─────┬─────┬─────┬─────┬─────┬─────┐
│ Eden│ Eden│ Old │ Surv│ Old │ Hum │ Eden│ Old │
├─────┼─────┼─────┼─────┼─────┼─────┼─────┼─────┤
│ Old │ Old │ Eden│ Free│ Surv│ Old │ Old │ Eden│
└─────┴─────┴─────┴─────┴─────┴─────┴─────┴─────┘
这里有三个关键点:
- 堆被切成多个等大小 Region。
- Eden、Survivor、Old 不再要求物理连续。
- 一个 Region 的“角色”可以在不同阶段动态变化。
这才是 G1 灵活的来源
很多人会把 G1 的优势概括成“并行处理多个小 Region”,这方向是对的,但还不够完整。G1 真正的收益来自四件事同时成立:
- 按 Region 回收:每次不必盯着整个大分区。
- 逻辑分代:年轻代大小可以动态伸缩。
- 增量式整理:回收时通过对象搬迁顺手做压缩,降低碎片。
- 按收益排序:优先选择垃圾占比高、回收价值高的 Region。
G1 的“Garbage-First”到底指什么
并不是“看到垃圾就立刻回收”,而是:
- G1 会估算某些 Region 的可回收收益。
- 再结合预测暂停时间,挑一批最值得回收的 Region 进入 Collection Set,简称 CSet。
- 在尽量逼近暂停目标的前提下,优先做收益最高的回收。
G1 为什么更容易控制停顿时间
核心不是承诺,而是预测和折中
-XX:MaxGCPauseMillis=200 表示的是暂停时间目标,不是硬实时保证。
更准确的理解是:
- G1 会尽量把每次停顿控制在目标附近。
- 目标越小,G1 往往会缩小每次愿意处理的工作量。
- 如果堆压力太高、存活对象太多,暂停时间依然可能超过目标。
一个直观流程
1
2
3
4
5
6
7
8
9
设定暂停目标 200ms
│
├─ 预测扫描/复制/更新引用的成本
│
├─ 选择若干个最值得回收的 Region 进入 CSet
│
├─ 执行一次 Young GC 或 Mixed GC
│
└─ 根据本次结果继续调整下一次年轻代大小和回收节奏
和传统收集器相比差异在哪
传统思维更像:
- 年轻代大小先划好。
- 触发 GC 后,把这个分区整体收一遍。
G1 更像:
- 我有一堆 Region。
- 我先预测这次能处理多少工作量。
- 然后挑出最划算的一批来回收。
所以它的优势不是“绝对更快”,而是在大堆、延迟敏感场景下,更容易取得可预测的停顿表现。
G1 的回收过程要真正串起来看
1. Young GC
Young GC 仍然是最常见的 GC 事件。
其本质是:
- 回收 Eden Region。
- 连同上一次留下来的 Survivor Region 一起处理。
- 把存活对象复制到新的 Survivor Region 或晋升到 Old Region。
1
2
3
4
5
6
7
[Eden][Eden][Survivor(old)]
│
└── STW Evacuation Pause
│
├─ 存活对象 -> 新 Survivor
├─ 年龄足够 -> Old
└─ 原 Region -> Free
2. Concurrent Marking
当老年代占用达到阈值附近时,G1 会启动并发标记周期。这里是理解 Mixed GC 的前提。
大致分为:
- 初始标记
Initial Mark,通常搭在一次 STW Young GC 上。 - 根区域扫描
Root Region Scan。 - 并发标记
Concurrent Marking。 - 重新标记
Remark。 - 清理
Cleanup。
这里面一个重要关键词是 SATB(Snapshot-At-The-Beginning),可以理解为:
- G1 在并发标记开始时,逻辑上先拍一张“存活对象快照”。
- 后续应用线程继续运行,GC 通过写屏障等机制尽量维护这张快照的正确性。
3. Mixed GC
并发标记完成后,G1 不会马上做一次“整堆老年代大扫除”,而是进入 Mixed GC 阶段。
Mixed GC 的特点是:
- 依然会回收年轻代。
- 同时只挑一部分回收价值较高的 Old Regions 一起处理。
- 连续进行若干次,而不是一次性扫完整个老年代。
1
2
3
4
5
6
7
Concurrent Marking 完成
│
├─ 得到各 Region 存活度信息
│
├─ 选择一批高收益 Old Regions
│
└─ 在后续多次 Mixed GC 中逐步回收
这正是 G1 避免长时间停顿的关键:把老年代回收拆小、拆散、分批做。
G1 如何减少内存碎片
CMS 的痛点
CMS 的核心优点是低停顿,但老问题也很著名:
- 老年代主要基于标记-清除。
- 清掉垃圾后会留下不连续空洞。
- 碎片积累到一定程度,就可能触发 Full GC 或分配失败。
G1 的思路
G1 在回收 Region 时,会把活对象复制到新的 Region 中,这意味着它天然带有整理效果。
1
2
回收前: [Old(碎片多)] [Old(碎片多)] [Free] [Humongous]
回收后: [Old(紧凑)] [Old(紧凑)] [Free] [Humongous]
注意这里也不能说成“G1 完全不会碎片化”,更准确的说法是:
- 普通对象因为 evacuation + compaction,碎片问题明显缓解。
- Humongous 对象因为要求连续 Region,仍然可能带来特殊碎片压力。
G1 里的 Humongous 对象要单独理解
判定规则
在 G1 中:
- 对象大小 大于等于 Region 大小的一半,就会被视为 Humongous 对象。
- 它会直接分配到一组连续的 Humongous Regions。
例如 Region 大小是 4MB:
1MB对象:普通对象2MB及以上对象:Humongous 对象
为什么它仍然麻烦
Humongous 对象虽然绕开了普通年轻代复制路径,但代价也很明显:
- 需要连续 Region。
- 可能导致堆空间“看起来够,但连续空间不够”。
- 分配 Humongous 对象可能更早触发并发标记检查。
- 在极端情况下,可能把 G1 推向 Full GC。
所以这句话更准确
不建议写成:
- “Humongous Region 不属于 Old Generation。”
更建议写成:
- “G1 会把超大对象直接分配到一组连续的 Humongous Regions;这些 Region 是 G1 对 old 区域中的大对象做的特殊布局和管理方式。”
G1 会不会 Full GC
会,但 Full GC 不是 G1 的常态路径,而是兜底路径。
常见触发背景包括:
- 疏散失败
evacuation failure - 没有足够可用或连续 Region 完成对象转移
- Humongous 对象分配压力过大
- 并发标记回收跟不上分配速度
- 堆空间过小或存活对象比例过高
所以正确理解应该是:
- G1 的目标是减少 Full GC 发生概率。
- 不是“用了 G1 就没有 Full GC”。
从对象晋升角度再看 G1 的动态分区
传统模型
1
2
3
Eden + Survivor0 ---> Survivor1
Eden + Survivor1 ---> Survivor0
存活足够久 ---> Old
这个模型的重点是“在两个固定 Survivor 空间之间倒腾”。
G1 模型
G1 没有固定物理位置上的 Survivor0 / Survivor1 概念,更像是:
- 本次 GC 需要多少 Survivor 空间,就临时选择多少个空闲 Region 来扮演 Survivor。
- 下次 GC 后,这些 Region 还可以重新变成 Eden、Old 或 Free。
1
2
3
4
5
Young GC 前:
[Eden R1][Eden R2][Eden R3][Free R7][Free R9][Old R10]
Young GC 后:
[Free R1][Free R2][Free R3][Surv R7][Surv R9][Old R10]
这就是“逻辑分代、物理不固定”的真正含义。
G1 的几个核心内部术语
Remembered Set
如果一个 Old Region 指向了某个 Young Region,GC 不能每次都把整个堆扫描一遍去找这种跨 Region 引用。
G1 的做法是维护 Remembered Set:
- 记录“谁可能引用了当前 Region”。
- 回收某个 Region 时,只需扫描与它相关的引用集合,而不必全堆扫描。
这也是 G1 能按 Region 独立回收的重要基础。
Write Barrier
Remembered Set 和并发标记都不是白来的,它们依赖写屏障来记录引用变化。
可以粗略理解为:
- 应用线程每次修改对象引用时,JVM 会顺带做一些 GC 记账工作。
- 这会带来一定运行期开销。
- 换来的收益是更短、更可控的停顿。
因此 G1 的设计目标本来就是:用一部分吞吐量,换更好的延迟表现。
监控工具
命令行工具
1
2
3
4
5
jps # 查看 Java 进程
jstat # 查看 GC 与分代统计
jstack # 查看线程堆栈
jmap # 查看堆、对象分布、dump
jcmd # 功能更全,很多场景比 jmap/jstack 更推荐
图形化与诊断工具
1
2
3
jconsole
jvisualvm
arthas
如果是线上排障,通常更推荐组合使用:
jstat看 GC 频率和趋势jcmd GC.heap_info/GC.class_histogram看堆和对象分布jstack看线程状态arthas做在线诊断
G1 参数应该怎么记
最重要的不是“背全”,而是知道哪些别乱改
1
2
3
4
5
6
7
8
# 常见 G1 参数
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200
-XX:InitiatingHeapOccupancyPercent=45
-XX:G1HeapRegionSize=16m
-XX:ConcGCThreads=4
-XX:G1HeapWastePercent=5
-XX:G1MixedGCLiveThresholdPercent=85
参数理解顺序
建议按下面顺序理解:
-Xms/-Xmx决定总堆空间。-XX:MaxGCPauseMillis决定 G1 的暂停目标。IHOP影响并发标记何时开始。G1HeapRegionSize影响 Region 粒度和 Humongous 判定阈值。- Mixed GC 相关参数影响老年代回收节奏。
一个常见误区
很多从 Parallel/CMS 迁移到 G1 的调优习惯,会下意识想继续固定年轻代大小,比如:
1
2
3
-Xmn
-XX:NewRatio
-XX:SurvivorRatio
但对 G1 来说,年轻代大小本来就是它用来逼近暂停目标的重要调节手段。过度手工固定,反而可能破坏它的自适应能力。
Safe Point 为什么存在
先说本质
Safepoint 是一段程序执行位置,在这个位置上:
- GC Roots 是可枚举的。
- 栈和寄存器中的对象引用关系是已知且一致的。
- JVM 可以安全地暂停线程,执行 GC、反优化、线程 dump 等 VM 操作。
所以 Safepoint 的关键不是“方便暂停”,而是保证暂停时观察到的是一致状态。
为什么不能随时暂停线程
看一个非常简单的例子:
1
2
3
4
5
6
7
public class WhySafepoint {
public static void main(String[] args) {
int a = 1;
int b = 2;
int c = a + b;
}
}
如果线程刚执行到某条机器指令的一半,JVM 立刻强制停下,就会出现问题:
- 某些引用还在寄存器里,尚未回写。
- 栈帧可能处于过渡态。
- GC 不一定能准确识别所有根引用。
结果就可能是:
- 该存活的对象没被标记到。
- 不该回收的对象被错误回收。
- 或者 JVM 根本无法建立正确的栈与寄存器映射。
Safepoint 通常出现在哪里
可以大致理解为“编译器愿意保证状态可恢复、可扫描的那些位置”,常见包括:
- 方法调用处
- 方法返回处
- 循环回边处
- 异常跳转相关位置
它不是“每一行 Java 代码”都有,也不是“每条机器指令”都有。
GC 与 Safepoint 的配合流程
1
2
3
4
5
6
7
8
9
JVM 发起一次需要 STW 的 VM Operation
│
├─ 设置 Safepoint 请求
│
├─ 各线程运行到最近的 Safepoint 后挂起
│
├─ JVM 完成根枚举 / GC / 其他 VM 操作
│
└─ 恢复线程继续执行
还要知道 Saferegion
有些线程可能不是“正在跑”,而是处于阻塞、休眠或者等待状态。这时它不一定主动跑到 Safepoint,但 JVM 仍然需要知道它处于安全状态。
这时就会涉及 Saferegion 的概念:
- 线程进入某个区域后,即使不继续执行,也不会破坏 GC 根枚举正确性。
- 典型如阻塞或等待中的线程。
可以把它理解成:
- Safepoint 是“线程主动跑到一个安全位置”。
- Saferegion 是“线程虽然不跑,但所在状态本身已经安全”。
把整篇内容串成一条主线
1
2
3
4
5
6
7
8
9
类加载完成
│
├─ 类元数据进入方法区 / 元空间语境
├─ 对象通常在 Eden 分配
├─ Young GC 回收大多数短命对象
├─ 存活对象进入 Survivor / 晋升 Old
├─ G1 用 Region + CSet + 并发标记管理整堆
├─ 为了安全枚举根,JVM 在 Safepoint 执行关键 VM 操作
└─ 通过日志、jstat、jcmd、jstack 等工具观测运行状态
如果只记一条主线,可以概括为:
- 运行时数据区 解决“数据放哪儿”。
- 分代与对象晋升 解决“对象为什么分层管理”。
- G1 解决“大堆下如何更平滑地回收”。
- Safepoint 解决“GC 为什么能安全暂停线程”。
面试或复习时最值得区分的几个结论
1. 方法区不等于元空间
- 方法区是规范概念。
- 元空间是 HotSpot 的具体实现语境。
2. G1 不是不分代
- G1 仍然分代。
- 只是年轻代、老年代变成了 Region 集合上的逻辑概念。
3. MaxGCPauseMillis 不是强保证
- 它是目标值、参考值。
- 不代表任何情况下都严格满足。
4. Humongous 对象不是“完全脱离 Old”
- 它是 G1 对大对象做的特殊 Region 布局。
- 不能简单粗暴地说“不属于 Old Generation”。
5. G1 也会 Full GC
- 只是希望尽量少发生。
- Full GC 出现通常说明堆压力、分配模式或调优存在问题。
继续深挖时建议看什么
如果要从“概念理解”继续走向“性能分析”,建议顺着下面路径继续:
- 学会读
-Xlog:gc*日志,先分清 Young GC、Mixed GC、Full GC。 - 理解
SATB、Remembered Set、写屏障各自解决什么问题。 - 结合
jstat、jcmd、jmap看真实堆变化,而不是只背术语。 - 把 G1 和 ZGC、Shenandoah 的设计目标做对比,理解“低延迟”路线差异。
- 再回头看源码或 HotSpot 文档,会更容易抓到重点。