[TOC]
1
2
3
4
5
6
7
8
9
10
| ┌─────────────────────────────────────────────────────────────┐
│ JVM 运行时数据区 │
├─────────────┬─────────────┬─────────────────────────────────┤
│ 线程共享区 │ 线程私有区 │ 执行引擎 │
├─────────────┼─────────────┼─────────────────────────────────┤
│ • 方法区 │ • 程序计数器 │ • 解释器 │
│ • 堆内存 │ • 虚拟机栈 │ • JIT编译器 │
│ • 运行时常量池│ • 本地方法栈 │ • 垃圾收集器 │
│ │ │ • 本地方法接口 │
└─────────────┴─────────────┴─────────────────────────────────┘
|
监控工具
1
2
3
4
5
6
7
8
9
10
| # 命令行工具
jps # 查看Java进程
jstat # 查看GC统计信息
jstack # 查看线程堆栈
jmap # 查看内存使用
# 图形化工具
jconsole
jvisualvm
arthas # 阿里开源诊断工具
|
收集器
传统收集器
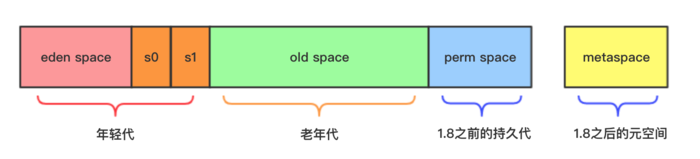
物理分区 、逻辑分区
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public class TraditionalCollectorDesign {
/**
* 传统收集器(Serial, Parallel, CMS)的设计选择:
* - 在堆内存中划出固定的物理区域
* - 年轻代:Eden + 2个Survivor(固定比例)
* - 老年代:剩余部分、老年代是连续的大内存块
* - 大对象直接在老年代的连续空间中分配
* - 分代边界是固定的物理地址
*/
// 物理内存布局:
// 0x0000 ┌─────────────┐ ← 年轻代起始
// │ Eden │
// ├─────────────┤
// │ Survivor0 │
// ├─────────────┤
// │ Survivor1 │
// ├─────────────┤ ← 年轻代/老年代边界(固定)
// │ Old Gen │
// 0x8000 └─────────────┘
}
|
G1收集器
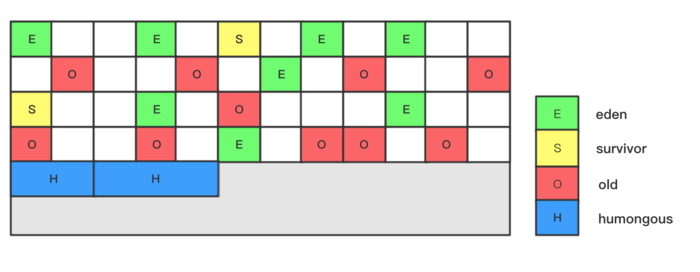
物理不分代 、 逻辑分代
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public class G1CollectorDesign {
/**
* G1收集器的设计选择:
* - 将堆划分为多个大小相等的Region
* - 每个Region可以动态扮演不同角色::Eden、Survivor、Old、Humongous
* - 大对象在连续的Humongous Region中分配
* - Humongous Region是特殊类型,不属于Old Generation
* - 分代是逻辑概念,不是物理边界
*/
// 逻辑内存布局:
// Region0: Eden │ Region4: Old
// Region1: Old │ Region5: Eden
// Region2: Humongous │ Region6: Survivor
// Region3: Survivor │ Region7: Eden
// 没有固定的物理分代边界!
}
|
G1逻辑分代的核心优势
1、可预测的停顿时间(G1的核心目标)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| public class PredictablePauseTimes {
/**
* 传统收集器的问题:
* - 收集整个年轻代或整个老年代
* - 停顿时间随着堆大小增长而增加
*
* G1的解决方案:
* - 将堆划分为多个Region
* - 每次只收集一部分Region(Collection Set)
* - 停顿时间可控,通常设定为-XX:MaxGCPauseMillis=200ms
*/
public void demonstratePauseControl() {
// G1通过以下机制实现可预测停顿:
// 1. 增量式回收:每次只处理部分Region
// 2. 优先级回收:优先回收垃圾最多的Region(Garbage-First)
// 3. 用户可设定目标停顿时间
}
}
|
2、内存管理的灵活性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| public class FlexibleMemoryManagement {
/**
* 传统收集器的固定分代问题:
* - 新生代/老年代比例固定
* - 容易导致过早晋升或内存浪费
*
* G1的灵活分代优势:
* - Region可以动态改变角色
* - 自动调整各代大小
* - 更好的内存利用率
*/
// Region角色动态转换示例
class RegionRoleTransition {
/**
* Region生命周期:
* 空闲Region → Eden Region → Survivor Region → Old Region
* ↘ Humongous Region
*
* 根据应用需求自动调整:
* - 如果年轻代对象存活率高,增加Survivor Region
* - 如果分配速率高,增加Eden Region
* - 如果大对象多,分配更多Humongous Region
*/
// 场景1:大量短期对象
// G1自动增加Eden Region数量,提高吞吐量
// 场景2:对象存活率高
// G1自动增加Survivor Region,减少过早晋升
// 场景3:内存分配速率变化
// G1动态调整Region分配策略
// 传统收集器需要手动调整:
// -XX:NewRatio, -XX:SurvivorRatio, -Xmn等参数
// 而G1自动完成这些调整
}
}
|
3、避免内存碎片
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| public class MemoryFragmentationAvoidance {
/**
* 传统CMS收集器的碎片问题:
* - 使用标记-清除算法,不整理内存
* - 长时间运行后产生内存碎片
* - 导致Full GC和长时间停顿
*
* G1的解决方案:
* - 在并发标记过程中识别垃圾最多的Region
* - 在Mixed GC时,优先回收这些Region并整理内存
* - 通过复制算法消除碎片
*/
public void demonstrateDefragmentation() {
// G1的内存整理过程:
// 回收前:│ Eden │ Old(fragmented) │ Humongous │ Old(fragmented) │
// 回收后:│ Eden │ Old(compacted) │ Free │ Old(compacted) │
// 优势:
// 1. 增量式整理,避免长时间停顿
// 2. 选择性整理,只整理最有价值的Region
// 3. 持续维护堆的健康状态
}
}
|
4、更好的大对象处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| public class LargeObjectHandling {
/**
* 传统收集器的大对象问题:
* - 大对象直接进入老年代
* - 可能导致老年代碎片化
* - 大对象回收需要Full GC
*
* G1的Humongous对象优势:
* - 专门用Humongous Region管理大对象
* - 大对象不会导致老年代碎片
* - 可以在并发周期中回收Humongous对象
*/
public void compareLargeObjectManagement() {
// 传统收集器:
// 老年代布局:│ 小对象 │ 大对象(6M) │ 小对象 │ 大对象(8M) │ → 产生碎片
// G1收集器:
// Region布局:│ Eden │ Humongous(6M) │ Old │ Humongous(8M) │ → 隔离管理
}
}
|
性能对比
停顿时间对比
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public class PauseTimeComparison {
/**
* 实际应用中的停顿时间表现:
*/
public void comparePauseTimes() {
// 传统Parallel GC:
// Young GC: 50-100ms(随堆增长而增加)
// Full GC: 1-10秒(随堆增长显著增加)
// G1 GC:
// Young GC: 50-100ms(相对稳定)
// Mixed GC: 100-200ms(可控)
// Full GC: 极少发生(只在并发模式失败时)
// 关键优势:G1的停顿时间更可预测和可控
}
}
|
思考:应该是 将堆划分为多个Region 这个特性带来的优势吧,不再需要整个大分区回收,而是通过 并行处理 多个小Region
内存使用效率
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| public class MemoryEfficiency {
/**
* 内存使用效率对比:
*/
public void demonstrateEfficiency() {
// 场景:堆大小4GB,对象分配模式变化
// 传统收集器(固定分代):
// - 年轻代固定为1.3GB
// - 如果实际需要2GB年轻代,会导致频繁GC
// - 如果实际需要0.5GB年轻代,造成内存浪费
// G1收集器(动态分代):
// - 年轻代可以在0.5GB-2GB之间动态调整
// - 根据分配速率和存活率自动优化
// - 无内存浪费,适应工作负载变化
}
}
|
G1收集器参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| public class G1TuningParameters {
/**
* G1的调优参数反映其设计优势:
*/
public void tuningExamples() {
// 1. 停顿时间目标(核心优势)
// -XX:MaxGCPauseMillis=200
// 2. 自适应行为控制
// -XX:G1HeapWastePercent=5 // 允许的堆浪费比例
// -XX:G1MixedGCLiveThresholdPercent=85 // 老年代Region回收阈值
// 3. 并发控制
// -XX:ConcGCThreads=4 // 并发GC线程数
// -XX:InitiatingHeapOccupancyPercent=45 // 触发并发标记的堆占用率
// 对比传统收集器繁琐的调优:
// -XX:NewRatio, -XX:SurvivorRatio, -XX:MaxTenuringThreshold等
}
}
|
G1收集器 - 动态调整
G1垃圾收集器能根据应用程序的运行情况,动态调整内存布局和回收策略,核心目标是尽可能满足你设置的停顿时间目标(通过 -XX:MaxGCPauseMillis 指定),同时保持高吞吐量
G1的Region角色在运行时可以动态改变。例如,一个在一次垃圾回收后空闲出来的Region,下次分配时可能被用作Eden区,也可能用于分配大对象(Humongous区),或者变成Survivor区
| 调整维度 |
动态机制概述 |
| 内存管理 |
将堆划分为多个固定大小的 Region,Region的角色(Eden、Survivor、Old、Humongous)可以动态变化。新生代(Eden和Survivor Region的集合)的空间会动态扩容或缩容 |
| 回收策略 |
采用 Garbage-First 原则:优先回收垃圾最多(即可回收空间最大)的 Region。通过 Mixed GC 模式,在一次回收中同时处理年轻代和部分老年代 Region |
| 停顿预测 |
基于衰减平均算法,利用历史GC数据预测下一次GC的耗时。根据预测结果,动态决定每次回收的Region数量,以逼近停顿目标 |
对象内存分配
优先在Eden区分配
超大对象,分配在 老年代(传统收集器) 或者 Humongous区(G1收集器)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| # 针对对象分配的调优参数
# 1. 大对象阈值设置
-XX:PretenureSizeThreshold=3145728 # 3MB,对象超过此大小直接在老年代分配
# 2. TLAB相关参数
-XX:+UseTLAB # 启用TLAB(默认开启)
-XX:TLABSize=512k # 设置TLAB大小
-XX:+PrintTLAB # 打印TLAB信息
# 3. G1收集器大对象参数
-XX:+UseG1GC # 使用G1收集器
-XX:G1HeapRegionSize=16m # 设置Region大小
-XX:+PrintAdaptiveSizePolicy # 打印自适应大小策略
# 4. 内存分配监控
-XX:+PrintGCDetails # 打印GC详细信息
-XX:+PrintHeapAtGC # GC时打印堆信息
-XX:+PrintPromotionFailure # 打印分配失败信息
|
大对象分配:传统收集器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public class TraditionalLargeObjectAllocation {
/**
* 使用-XX:PretenureSizeThreshold参数
* 对象大小超过该阈值时,直接在老年代分配
*/
public void allocateLargeObject() {
// JVM参数:-XX:PretenureSizeThreshold=3145728 (3MB)
byte[] smallObj = new byte[2 * 1024 * 1024]; // 在Eden区分配
byte[] largeObj = new byte[4 * 1024 * 1024]; // 直接在老年代分配
// 为什么直接在老年代分配?
// 1. 避免在新生代来回复制大对象
// 2. 避免大对象导致频繁的Minor GC
// 3. 避免占用大量Eden区空间
}
}
|
大对象分配:G1收集器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| public class G1HumongousAllocation {
/**
* G1堆内存布局:
* ┌─────┬─────┬─────┬─────┬─────┬─────┐
* │Region│Region│Region│Region│Region│Region│
* └─────┴─────┴─────┴─────┴─────┴─────┘
*
* 超大对象分配:
* 对象大小 > RegionSize/2 → 认定为Humongous对象
*/
public void allocateHumongous() {
// 假设Region大小为4MB
int regionSize = 4 * 1024 * 1024;
// 大小超过2MB的对象被认为是Humongous对象
byte[] largeObj1 = new byte[3 * 1024 * 1024]; // Humongous对象
byte[] largeObj2 = new byte[8 * 1024 * 1024]; // 需要2个连续Region
// 分配过程:
// 1. 在老年代寻找连续的Region空间
// 2. 如果找不到,触发Full GC尝试整理空间
// 3. 如果还找不到,抛出OutOfMemoryError
}
}
|
从分区、对象晋升比较G1收集器
传统收集器的固定分区问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| public class TraditionalFixedPartition {
/**
* 传统收集器的固定分区导致内存浪费
*/
// 典型的新生代布局(-XX:NewRatio=2, -XX:SurvivorRatio=8)
// ┌─────────────────┐
// │ Eden │ 80% 年轻代
// ├─────────────────┤
// │ Survivor0 │ 10% 年轻代 ← 一半时间闲置
// ├─────────────────┤
// │ Survivor1 │ 10% 年轻代 ← 一半时间闲置
// └─────────────────┘
// 传统收集器内存布局:
class TraditionalLayout {
// ┌─────────────────────────────────┐
// │ 年轻代 │
// │ ┌─────┬─────────┬─────┐ │
// │ │ Eden│Survivor0│Surv1│ │
// │ │ 80% │ 10% │ 10% │ │
// │ └─────┴─────────┴─────┘ │
// ├─────────────────────────────────┤
// │ 老年代 │
// └─────────────────────────────────┘
// 问题1:Survivor空间固定,无法动态调整
// - 如果存活对象少:Survivor空间浪费
// - 如果存活对象多:导致过早晋升到老年代
// 问题2:物理分区限制
// - Survivor0和Survivor1必须相邻
// - 无法利用碎片化的空闲内存
}
}
|
G1收集器动态分区
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| public class G1DynamicAdvantage {
/**
* G1的动态Region分配如何减少内存浪费
*/
// Region分布(角色动态变化):
// ┌─────┬─────┬─────┬─────┬─────┬─────┬─────┬─────┐
// │ Eden │ Eden │ Eden │Surv│ Old │ Eden │Surv│ Hum │
// │Region│Region│Region│Region│Region│Region│Region│Region│
// └─────┴─────┴─────┴─────┴─────┴─────┴─────┴─────┘
// 注意:
// 1. Survivor Region不是固定的物理位置
// 2. 每次GC后,Region的角色可能改变
// 3. 没有固定的"Survivor0"和"Survivor1"概念
public void g1MemoryEfficiency() {
// 优势1:按需分配Survivor空间
// - 存活对象多:分配更多Survivor Region
// - 存活对象少:分配较少Survivor Region
// - 没有固定的"一半Survivor空间闲置"问题
// 优势2:利用碎片化空间
// 传统:只能使用固定的Survivor空间
// G1:可以使用堆中任何空闲Region作为Survivor
}
}
|
传统收集器-复制存活对象过程
1
2
3
4
5
6
7
8
| public void traditionalPromotion() {
// 传统复制过程:
// 1. 从Eden + Survivor0 复制到 Survivor1
// 2. 或者从Eden + Survivor1 复制到 Survivor0
// 3. 总是在这两个固定的Survivor空间之间切换
// 限制:即使堆中有其他空闲区域,也无法使用
}
|
G1收集器-复制存活对象过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| public class G1CopyingProcess {
/**
* G1年轻代GC时,存活对象的复制过程:
*/
public void youngGCInG1() {
// 初始状态:多个Eden Region中有存活对象
// ┌─────────┐ ┌─────────┐ ┌─────────┐
// │ Eden R1 │ │ Eden R2 │ │ Eden R3 │
// │ objA │ │ objB │ │ objC │ ← 存活对象
// │ objD │ │ │ │ objE │
// └─────────┘ └─────────┘ └─────────┘
// GC过程:
// 1. 标记所有Eden Region中的存活对象
// 2. 选择空闲Region作为目标Survivor Region
// 3. 将存活对象复制到新的Survivor Region
// 结果:
// ┌─────────┐ ┌─────────┐ ┌─────────────┐
// │ Free │ │ Free │ │ Survivor R7 │ ← 新分配的Survivor Region
// │ │ │ │ │ objA │
// │ │ │ │ │ objB │
// └─────────┘ └─────────┘ │ objC │
// │ objD │
// │ objE │
// └─────────────┘
// 示例场景:
// 堆中有空闲Region:R4, R7, R9, R12
// GC时,可以选择R4和R7作为Survivor Region
// 下次GC时,可能选择R9和R12作为Survivor Region
}
}
|
分区的意义
堆中分:eden、survivor、old 区,其实说白了,这些是根据对象年龄(也就是存活时间)判断,针对不同存活时间的对象,采用不同的回收机制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| public class GenerationalWisdom {
/**
* 对象年龄的核心意义:预测对象存活概率
*/
public void ageBasedPrediction() {
// 对象年龄与存活概率关系:
// 年龄0(新创建):存活概率 5-10%
// 年龄1(1次GC):存活概率 20-30%
// 年龄2(2次GC):存活概率 50-60%
// 年龄5+(5+次GC):存活概率 90%+
// 这就像"生存考验":
// 经历GC次数越多,证明对象越"顽强"
}
/**
* 分代设计体现的工程智慧
*/
// 1. 基于观察而非假设
class BasedOnObservation {
/**
* 不是理论上应该怎样,而是实际观察到的现象:
* - 对象生命周期分布不均匀
* - 大多数对象很短命
* - 少数对象很长寿
*/
}
// 2. 差异化处理
class DifferentialTreatment {
/**
* 对不同特征的对象使用不同策略:
* - 短期对象:快速分配,快速回收
* - 中期对象:观察筛选,避免误判
* - 长期对象:稳定存储,少打扰
*/
}
// 3. 渐进式优化
class ProgressiveOptimization {
/**
* 通过多级筛选确保准确性:
* - 第一级:Eden区快速淘汰(大多数对象)
* - 第二级:Survivor区精细筛选(可能长期的对象)
* - 第三级:老年代长期存储(确认长期的对象)
*/
}
}
|
safe point 安全点
和GC中的 STW停顿(Stop-The-World) 有关
安全点的工作机制:协作式暂停
说通俗点,就是jvm现在需要GC,但是又不能随时暂停工作中线程,需要各个工作中线程协同配合,到达代码安全点的时候,先暂停工作,等待GC完成
1
2
3
4
5
6
7
8
9
10
11
12
| public class WhySafepoint {
private static boolean stop = false;
public static void main(String[] args) {
// 问题场景:GC需要暂停所有线程来枚举GC Roots
// 但如果线程正在执行以下代码:
int a = 1;
int b = 2;
int c = a + b; // 执行到一半被GC暂停?
// 此时JVM无法确定寄存器、栈帧的状态,可能导致错误
}
}
|
核心原因:
GC需要准确枚举GC Roots(栈帧中的引用)
如果线程执行到一半被暂停,栈帧状态不确定
可能导致对象漏标记或错误回收
安全点通常设置在
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| public class SafepointLocations {
public void method() {
// 1. 方法返回前
return; // ← 安全点
// 2. 循环跳转处
for (int i = 0; i < 100; i++) {
// 循环末尾 ← 安全点
}
// 3. 抛出异常时
throw new RuntimeException(); // ← 安全点
// 4. 调用方法时
otherMethod(); // ← 安全点
}
// 但不是所有地方都是安全点!
public void notSafepoint() {
int a = 1;
int b = 2;
int c = a + b; // 这里通常不是安全点
}
}
|
执行流程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| public class GCWithSafepoint {
public static void main(String[] args) {
// 初始状态:所有线程正常运行
// ┌─────┐ ┌─────┐ ┌─────┐
// │线程A │ │线程B │ │线程C │ ← 都在执行代码
// └─────┘ └─────┘ └─────┘
// 步骤1:JVM需要GC,设置安全点请求
// JVM.safepointRequested = true
// 步骤2:各线程到达最近的安全点后暂停
// ┌─────┐ ┌─────┐ ┌─────┐
// │线程A │ │线程B │ │线程C │ ← 都在安全点暂停
// └─────┘ └─────┘ └─────┘
// ↓ ↓ ↓
// 安全点 安全点 安全点
// 步骤3:JVM确认所有线程已暂停,执行GC
System.gc(); // 实际GC发生在这里
// 步骤4:GC完成,恢复所有线程
// JVM.safepointRequested = false
// 所有线程从安全点继续执行
}
}
|