这篇笔记的目标是把开发里最常见的几类事务问题串起来:单库事务如何工作,跨库跨服务后为什么变难,Spring
@Transactional到底做了什么,以及消息最终一致性方案为什么会成为工程里的主流选择。
内容更偏向概念关系梳理 + 实战选型总结,重点关注原理、边界、常见误区和适用场景;不展开数据库内核实现和中间件部署细节,但会尽量把容易混淆的知识点讲清楚。
参考资料:
Spring Framework Reference - Transaction Management
Spring Framework Reference - Transaction-bound Events
[TOC]
1. 先建立整体图景
很多“事务问题”看起来都叫事务,但解决的其实不是同一层问题。
| 场景 | 核心问题 | 常见方案 |
|---|---|---|
| 单库单服务 | 一组 SQL 要么都成功,要么都失败 | 数据库本地事务、Spring @Transactional |
| 跨库/跨服务 | 一个业务动作拆成多个服务步骤后如何保持一致 | XA、TCC、Saga、Seata |
| 业务 + 消息 | 本地事务提交后,如何可靠通知下游 | 本地消息表、RocketMQ 事务消息 |
可以先记住一个总图:
1
2
3
4
5
6
7
8
单体应用时代
订单服务 + 账户表 + 库存表都在一个数据库
-> 本地事务就够用
服务拆分之后
订单服务 -> 账户服务 -> 库存服务 -> 消息服务
-> 单个数据库事务已经覆盖不了整个调用链
-> 需要分布式事务 / 最终一致性方案
事务设计里通常有两个目标:
- 强一致性:一旦返回成功,各参与方状态立刻一致
- 最终一致性:允许短暂不一致,但系统会通过补偿、重试、回查等机制收敛到一致
工程上并不是“一定追求最强一致性”。越强的一致性,通常意味着越高的锁成本、等待成本和系统耦合度。
2. 分布式事务常见方案
2.1 2PC(Two-Phase Commit,两阶段提交)
核心思想是引入一个协调者(Transaction Manager),统一控制所有参与者提交或回滚。
1
2
3
4
5
6
7
8
阶段一:Prepare
协调者 -> 参与者A:你能提交吗?
协调者 -> 参与者B:你能提交吗?
参与者执行本地操作,但先不真正提交,返回 Yes / No
阶段二:Commit / Rollback
如果全部 Yes -> 协调者通知所有参与者 Commit
只要有一个 No -> 协调者通知所有参与者 Rollback
优点:
- 模型直接,容易理解
- 偏向强一致性
缺点:
- 同步阻塞,Prepare 阶段会持有资源锁
- 协调者是单点
- 第二阶段可能出现部分成功、部分失败,恢复复杂
- 分支越多,性能越差
2PC 更像很多分布式事务方案的理论起点,真正大规模业务里直接使用并不理想。
2.2 3PC(Three-Phase Commit,三阶段提交)
3PC 在 2PC 基础上增加了 CanCommit 阶段和超时机制,试图降低阻塞风险。
1
2
3
CanCommit -> 先询问是否具备提交条件,不真正锁资源
PreCommit -> 预提交,执行操作但不最终提交
DoCommit -> 正式提交
相对 2PC 的改进:
- 引入超时,减少参与者无限阻塞
- 多了一层预判,降低直接进入 Prepare 的代价
局限:
- 网络分区和极端故障下,仍然无法彻底避免不一致
- 实现复杂度更高
- 工程落地远不如 TCC、Saga、消息最终一致性常见
2.3 XA
XA 可以看作数据库层面对 2PC 的标准化实现。
- TM:Transaction Manager,事务管理器
- RM:Resource Manager,资源管理器,通常就是数据库
- 应用通过 JTA / XA 协议协调多个数据库资源
特点:
- 强一致性更好理解
- 数据库原生参与协议
- 代价是性能差、锁持有时间长、吞吐低
适用场景:
- 对一致性要求极高
- 并发量不大
- 参与资源都支持 XA
如果系统是高并发互联网业务,XA 往往不是第一选择。
2.4 TCC(Try-Confirm-Cancel)
TCC 是业务层面的分布式事务,把一个动作拆成三个显式阶段,需要明显的业务侵入。
| 阶段 | 职责 | 转账示例 |
|---|---|---|
| Try | 资源检查与预留 | 冻结金额,但暂不真正扣减 |
| Confirm | 确认执行 | 真正扣款并到账 |
| Cancel | 取消预留 | 解冻金额,恢复资源 |
1
2
3
4
5
发起方
-> 调用账户服务 Try
-> 调用库存服务 Try
-> 全部成功后统一 Confirm
-> 任一步失败则统一 Cancel
优点:
- 不依赖数据库长事务锁
- 性能通常优于 XA
- 业务语义清晰,适合核心资金链路
缺点:
- 业务侵入性强,每个服务都要实现三套接口
- 要处理幂等、空回滚、悬挂等经典问题
三个高频概念需要分清:
- 幂等:Confirm / Cancel 重复调用,结果仍然正确
- 空回滚:Try 没成功或根本没执行,Cancel 却到了
- 悬挂:Cancel 已执行后,迟到的 Try 又执行成功,导致状态错误
TCC 适合高价值、高一致性要求且业务能够清晰建模“预留资源”的场景,例如支付、余额、库存冻结。
2.5 Saga
Saga 适合长事务。它把一个大事务拆成多个本地事务,通过补偿操作实现最终一致性。
1
2
3
4
T1 -> T2 -> T3 -> T4(失败)
|
v
C3 <- C2 <- C1
其中:
Tn是正向业务动作Cn是对应的补偿动作
两种组织方式:
- 编排式(Orchestration):由中心协调器推进流程
- 协同式(Choreography):服务间通过事件协作推进
优点:
- 无全局锁
- 适合跨服务、长流程业务
- 对第三方系统和遗留系统更友好
缺点:
- 隔离性较弱,中间状态对外可见
- 补偿逻辑复杂
- 不是所有操作都天然可补偿
典型场景包括:旅游下单、订单履约、跨组织审批等长链路业务。
2.6 Seata 框架
Seata 是分布式事务框架,提供了 AT、TCC、Saga、XA 多种模式,可以理解成一套统一的事务治理工具箱。
| 模式 | 一致性 | 性能 | 业务侵入 | 适用场景 |
|---|---|---|---|---|
| AT | 最终一致 | 高 | 低 | 常规关系型数据库业务 |
| TCC | 最终一致 | 很高 | 强 | 资金、库存等核心链路 |
| XA | 强一致 | 低 | 低 | 对一致性要求极高且流量不大 |
| Saga | 最终一致 | 高 | 中 | 长流程、可补偿业务 |
Seata 中几个角色要先分清:
- TM:定义全局事务边界
- TC:协调全局事务状态
- RM:管理分支事务资源
Seata AT 模式原理
AT 是 Seata 最常用的模式,特点是低业务侵入,但前提是关系型数据库 + JDBC 访问模型比较标准。
一阶段:
- 执行业务 SQL
- 记录
undo_log - 在同一个本地事务中一起提交
- 释放本地锁和连接资源
二阶段提交:
- 全局提交时,异步清理
undo_log
二阶段回滚:
- 根据
undo_log做反向补偿
可以把它理解成“自动帮你维护回滚镜像 + 全局锁控制”的增强版本地事务。
需要注意:
- AT 并不是完全零成本,需要代理数据源、维护
undo_log - 对 SQL 形态、数据库类型、隔离要求都有一定约束
- 不适合所有复杂 SQL 和非关系型存储场景
2.7 如何选型
可以先用一个很实用的判断顺序:
- 单库能解决,就不要上分布式事务
- 能接受异步收敛,就优先考虑最终一致性方案
- 只有确实要求强一致且链路可控时,再考虑 XA / 强协调方案
- 核心资金、库存预留类业务,更适合 TCC
- 长流程、可补偿业务,更适合 Saga
一个简化版选型表:
| 场景 | 更常见选择 |
|---|---|
| 单库订单创建 | Spring 本地事务 |
| 下单后发积分、发通知 | 本地消息表 / 事务消息 |
| 支付、扣减余额、冻结库存 | TCC |
| 多库强一致且并发不高 | XA |
| 审批流、履约流、跨系统长流程 | Saga |
| 普通微服务数据库事务治理 | Seata AT |
3. 消息最终一致性
分布式事务里最常落地的,并不是 XA,而是“本地事务 + 可靠消息 + 重试补偿”这一类最终一致性方案。
3.1 本地消息表(Transactional Outbox)
本地消息表,本质上就是常说的 Transactional Outbox 模式。
核心思想:把“业务数据变更”和“待发送消息记录”放进同一个本地事务里提交。只要本地事务成功,消息记录就一定存在;后续再由异步任务把消息投递出去。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
步骤1:本地事务内
- 写业务表
- 写消息表(status = 待发送)
步骤2:事务提交后
- 投递程序扫描消息表
- 发送到 MQ
步骤3:消费方处理成功
- 更新消息状态 / 记录消费结果
步骤4:发送失败或超时
- 定时任务重试
- 超过阈值后告警
实现流程:
- 在同一个本地事务里完成业务操作和消息入表
- 事务提交后,由投递任务把消息发给 MQ
- 下游消费后返回成功状态,或上游根据状态机完成关闭
- 定时任务扫描超时未完成消息,做重试补偿
- 超过最大次数后进入人工介入或死信处理
本地消息表示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
CREATE TABLE local_message (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
biz_id VARCHAR(64) NOT NULL COMMENT '业务ID,用于幂等',
topic VARCHAR(128) NOT NULL COMMENT '消息主题',
body TEXT NOT NULL COMMENT '消息体(JSON)',
status TINYINT NOT NULL DEFAULT 0 COMMENT '0-待发送 1-发送中 2-已完成 3-失败',
retry_count INT NOT NULL DEFAULT 0 COMMENT '已重试次数',
max_retry INT NOT NULL DEFAULT 5 COMMENT '最大重试次数',
next_retry_time DATETIME COMMENT '下次重试时间',
create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
update_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
INDEX idx_status_retry (status, next_retry_time)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
关键设计点:
- 原子性保证:业务写库和消息入表必须在同一本地事务
- 幂等消费:消息可能重复投递,下游必须幂等
- 退避重试:建议使用递增退避,而不是高频死循环重试
- 状态机设计:待发送、发送中、已完成、失败要清晰
- 消息清理:已完成消息要归档或删除,避免表膨胀
优点:
- 通用性强,不依赖特定 MQ 的事务能力
- 思路稳定,工程上容易审计与排障
缺点:
- 需要维护额外的消息表和投递程序
- 与业务存在一定耦合
- 存在异步延迟
3.2 RocketMQ 事务消息
RocketMQ 事务消息通过半消息(Half Message)+ 本地事务 + Broker 回查机制,保证“消息发送”和“本地事务执行结果”之间的最终一致性。
它解决的是生产端原子性问题,不等于消费端天然强一致;消费侧依然必须考虑幂等、重试和去重。
执行流程:
1
2
3
4
5
6
7
1. Producer 发送半消息到 Broker
2. Broker 持久化成功,但此时消息对 Consumer 不可见
3. Producer 执行本地事务
4. Producer 根据本地事务结果返回 Commit / Rollback
5. Broker 把 Commit 的消息变为可消费
6. 若 Broker 长时间没收到明确结果,会回查 Producer
7. Producer 根据本地事务最终状态再次回答 Commit / Rollback / UNKNOW
代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
TransactionMQProducer producer = new TransactionMQProducer("tx_producer_group");
producer.setNamesrvAddr("localhost:9876");
producer.setTransactionListener(new TransactionListener() {
@Override
public LocalTransactionState executeLocalTransaction(Message msg, Object arg) {
try {
orderService.createOrder(arg);
return LocalTransactionState.COMMIT_MESSAGE;
} catch (Exception e) {
return LocalTransactionState.ROLLBACK_MESSAGE;
}
}
@Override
public LocalTransactionState checkLocalTransaction(MessageExt msg) {
String orderId = msg.getKeys();
boolean exists = orderService.existsOrder(orderId);
return exists
? LocalTransactionState.COMMIT_MESSAGE
: LocalTransactionState.UNKNOW;
}
});
Message msg = new Message("order_topic", "创建订单消息体".getBytes());
msg.setKeys("ORDER_202311130001");
producer.sendMessageInTransaction(msg, orderParam);
关键点:
- 半消息对消费者不可见,避免“本地事务失败但消息已被消费”
- 回查逻辑必须能根据业务数据判断最终事务状态
UNKNOW只是中间态,不能长期停留- 消费端仍然必须保证幂等
适用场景:
- 本地事务完成后必须可靠投递事件
- 已经使用 RocketMQ,想减少自建消息表成本
优缺点:
- 优点:不需要自建消息表,生产端链路更自然
- 缺点:依赖 RocketMQ 生态,回查逻辑需要自己实现
3.3 本地消息表 vs RocketMQ 事务消息
| 维度 | 本地消息表 | RocketMQ 事务消息 |
|---|---|---|
| MQ 依赖 | 弱 | 强,依赖 RocketMQ |
| 实现复杂度 | 要维护消息表和投递任务 | 要实现事务监听与回查 |
| 可观测性 | 数据库里天然可查 | 依赖 MQ 侧状态与日志 |
| 通用性 | 高 | 中 |
| 适用建议 | 多数系统都能用 | 已深度使用 RocketMQ 时更合适 |
4. Spring 事务核心接口与管理器
Spring 事务本质上是在统一抽象不同资源的事务管理能力。
4.1 核心接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
// 事务管理的核心入口
public interface PlatformTransactionManager {
TransactionStatus getTransaction(TransactionDefinition definition) throws TransactionException;
void commit(TransactionStatus status) throws TransactionException;
void rollback(TransactionStatus status) throws TransactionException;
}
// 事务定义:传播行为、隔离级别、超时、只读等
public interface TransactionDefinition {
int getPropagationBehavior();
int getIsolationLevel();
int getTimeout();
boolean isReadOnly();
String getName();
}
// 事务状态:是否新事务、是否标记回滚、是否已完成等
public interface TransactionStatus {
boolean isNewTransaction();
boolean hasSavepoint();
void setRollbackOnly();
boolean isRollbackOnly();
boolean isCompleted();
}
这三者的职责可以这样理解:
PlatformTransactionManager:真正执行开启、提交、回滚TransactionDefinition:描述“这个事务想怎么跑”TransactionStatus:描述“这个事务现在跑成什么状态了”
4.2 常见事务管理器
1
2
3
4
5
6
7
8
// JDBC 场景最常用
public class DataSourceTransactionManager implements PlatformTransactionManager
// JPA 场景常用
public class JpaTransactionManager implements PlatformTransactionManager
// JTA / XA 分布式事务
public class JtaTransactionManager implements PlatformTransactionManager
实际开发里最常遇到的通常还是 DataSourceTransactionManager。
5. Spring 事务传播行为
传播行为定义的是:一个事务方法被另一个事务方法调用时,Spring 该如何处理当前事务上下文。
| 传播行为 | 说明 | 常见场景 |
|---|---|---|
REQUIRED |
当前有事务则加入,没有则新建 | 大多数业务方法 |
REQUIRES_NEW |
总是新建事务,挂起当前事务 | 日志、审计、独立记录 |
NESTED |
当前有事务则创建保存点 | 子操作失败可局部回滚 |
SUPPORTS |
有事务就加入,没有就非事务执行 | 查询方法 |
NOT_SUPPORTED |
以非事务方式执行,挂起当前事务 | 不想被事务包裹的操作 |
MANDATORY |
当前必须有事务,否则抛异常 | 强制调用方带事务 |
NEVER |
当前不能有事务,否则抛异常 | 禁止事务上下文进入 |
三个最常考的区别:
REQUIRED:最常用,外层有事务就共用一个事务REQUIRES_NEW:内层永远开新事务,和外层相互独立NESTED:基于 savepoint,内层回滚不一定影响外层,但外层回滚会带着内层一起回滚
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// REQUIRED:A 和 B 在同一个事务里,B 抛异常,A 一般也会回滚
@Transactional(propagation = Propagation.REQUIRED)
public void methodA() {
methodB();
}
// REQUIRES_NEW:B 独立事务
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void methodB() {
// 与外层事务独立
}
// NESTED:基于保存点,常见于 JDBC + DataSourceTransactionManager
@Transactional(propagation = Propagation.NESTED)
public void methodC() {
// savepoint
}
NESTED依赖底层事务管理器对保存点的支持,实际使用时要看具体管理器和数据源能力,不能默认所有场景都生效。
6. Spring 事务隔离级别
隔离级别关注的是:并发事务同时读写时,会出现什么现象。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 说明 |
|---|---|---|---|---|
READ_UNCOMMITTED |
可能 | 可能 | 可能 | 隔离性最低,几乎不用 |
READ_COMMITTED |
不会 | 可能 | 可能 | Oracle、PostgreSQL 常见默认级别 |
REPEATABLE_READ |
不会 | 不会 | 可能 | MySQL InnoDB 常见默认级别 |
SERIALIZABLE |
不会 | 不会 | 不会 | 隔离性最高,性能最差 |
一个常见面试点:MySQL InnoDB 在 REPEATABLE_READ 下,结合 MVCC 与 Next-Key Lock,对很多场景下的幻读问题做了较强控制,因此常被总结为“基本解决幻读”;但这背后要区分快照读和当前读,不能机械地背成一句绝对化结论。
7. @Transactional 工作原理
@Transactional 的核心不是注解本身,而是 AOP 代理 + 事务拦截器 + 事务管理器 这套协作机制。
7.1 核心链路
- 代理机制:Spring AOP 创建代理对象拦截方法调用
- 事务拦截:
TransactionInterceptor决定何时开启、提交、回滚 - 事务管理:
PlatformTransactionManager屏蔽具体资源差异 - 资源绑定:通过
ThreadLocal绑定连接等事务资源 - 同步回调:
TransactionSynchronization提供事务生命周期钩子
7.2 执行时间线
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
T0: 进入代理对象方法
-> TransactionInterceptor 开始处理
T1: 读取 @Transactional 元信息
-> 传播行为、隔离级别、超时、只读等
T2: 判断当前线程是否已有事务
-> 决定加入 / 新建 / 挂起
T3: transactionManager.doBegin()
-> 获取连接
-> 设置自动提交、隔离级别、只读属性
-> 绑定资源到当前线程
T4: 执行业务方法
-> 执行 SQL / 调用 Repository
T5: 业务成功
-> commit
T6: 业务抛异常
-> 根据回滚规则 rollback
T7: 清理 ThreadLocal 中绑定的资源
T8: 返回结果或继续抛异常
这也是为什么 @Transactional 默认对同线程、通过代理进入的方法调用最有效。
7.3 @TransactionalEventListener
事务事件监听适合处理“只有事务真正完成后才能做”的事情,例如:
- 事务提交后发送领域事件
- 提交后删缓存
- 回滚后做清理或补偿
Spring 里的事务阶段:
1
2
3
4
5
6
public enum TransactionPhase {
BEFORE_COMMIT,
AFTER_COMMIT,
AFTER_ROLLBACK,
AFTER_COMPLETION
}
示例:
1
2
3
4
@TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)
public void handleOrderCreated(OrderCreatedEvent event) {
messageSender.send(event);
}
需要注意两个边界:
- 默认相位是
AFTER_COMMIT - 如果事件发布时没有活动事务,监听器默认不会执行,除非设置
fallbackExecution = true
还有一个容易忽略的点:在 AFTER_COMMIT / AFTER_ROLLBACK / AFTER_COMPLETION 阶段,原事务虽然已经结束,但某些事务资源可能还挂在线程上;这时做数据库写操作,不应该误以为还能“顺带提交到原事务”里。
8. @Transactional 失效场景
很多事务“不生效”,本质上不是 Spring 坏了,而是没有走到 Spring 事务代理的拦截点。
| 失效场景 | 原因 | 解决思路 |
|---|---|---|
自调用 this.xxx() |
没经过代理,直接调用目标对象 | 注入自身代理、AopContext、拆分到其他 Bean |
private / final / 代理无法拦截的方法 |
代理机制无法织入 | 尽量放在可被代理的方法上 |
| 异常被吃掉 | Spring 不知道要回滚 | 继续抛出异常,或显式 setRollbackOnly() |
| 抛出的是受检异常但未配置回滚规则 | 默认通常只回滚 RuntimeException / Error |
配置 rollbackFor |
| 对象未交给 Spring 管理 | 没有代理对象 | 注册为 Bean |
多线程 / @Async |
事务上下文绑在线程上 | 不要指望跨线程共享同一事务 |
| 数据库引擎不支持事务 | 如 MyISAM | 使用支持事务的存储引擎 |
8.1 自调用失效示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
@Service
public class OrderService {
@Autowired
private OrderService self;
@Transactional
public void createOrder() {
saveOrder();
self.bindCoupon();
}
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void bindCoupon() {
// 独立事务
}
}
如果写成 this.bindCoupon(),就会绕过代理,导致 REQUIRES_NEW 根本没有机会生效。
9. Spring 事务回滚规则
默认情况下,Spring 更倾向于在 RuntimeException 和 Error 上回滚。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// 默认回滚 RuntimeException 和 Error
@Transactional
public void method() { }
// 如果业务把失败定义为 checked exception,需要显式声明
@Transactional(rollbackFor = Exception.class)
public void method2() { }
// 可以排除某些不希望触发回滚的业务异常
@Transactional(
rollbackFor = Exception.class,
noRollbackFor = BusinessException.class
)
public void method3() { }
这里不要机械记成“总是配置 rollbackFor = Exception.class”。更准确的理解是:回滚规则应该与项目异常体系一致。如果项目大量使用受检异常表示业务失败,那么就应该明确配置。
10. 实战中的几个高频误区
10.1 事务不能跨线程传播
Spring 的经典事务模型基于线程绑定资源。主线程开启事务后,新线程并不会天然共享这个事务上下文,所以 @Async、线程池、并行流一旦混进来,就要重新审视事务边界。
10.2 只靠数据库事务解决不了跨服务一致性
数据库事务只能覆盖当前数据源。跨服务调用一旦出现网络波动、超时、重试、重复投递,就已经超出单库事务的能力边界。
10.3 最终一致性不等于不一致
最终一致性不是“放弃一致性”,而是通过状态机、重试、回查、补偿、幂等等手段,让系统在允许的时间窗口内收敛到一致。
10.4 事务粒度不是越大越好
长事务会占用连接、锁和线程资源,吞吐会明显下降。很多时候,把大事务拆成更小的本地事务,再配合异步收敛,反而更符合高并发系统的目标。
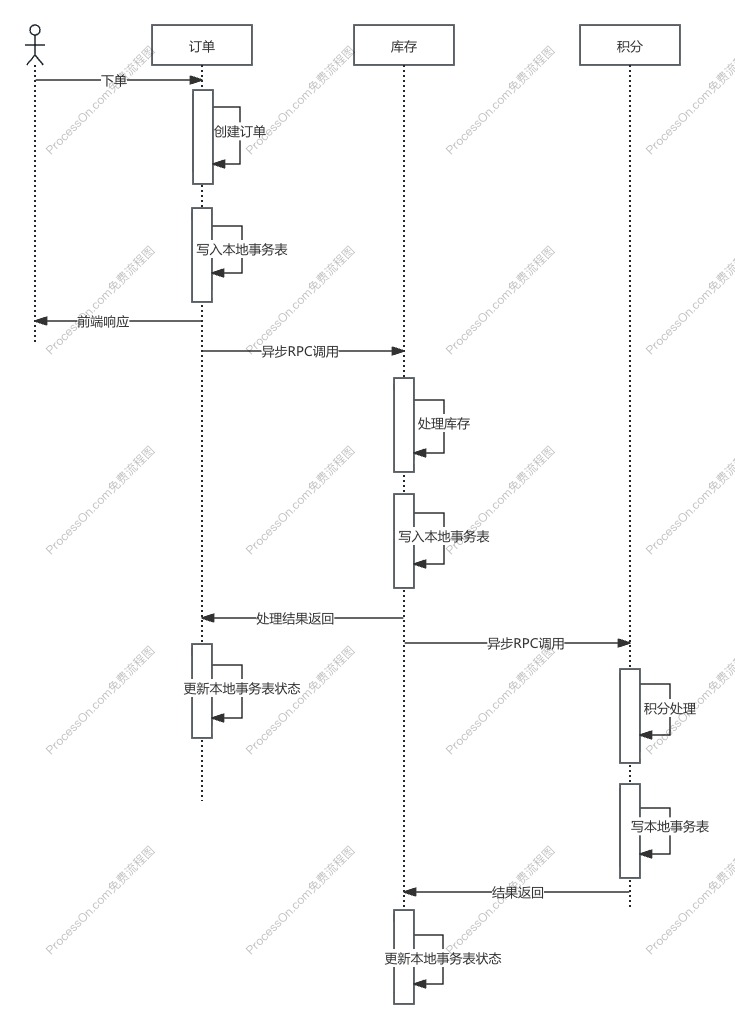
11. 订单-库存-积分完整案例对比
下面用一个统一业务场景,把 TCC、本地消息表、RocketMQ 事务消息 三种方案放到同一条链路里对比。
11.1 业务背景
假设现在有一个电商下单流程,涉及三个动作:
- 创建订单
- 扣减库存
- 发放积分
业务目标如下:
- 订单创建成功后,库存必须最终扣减成功
- 订单创建成功后,积分要最终发放
- 系统希望避免“订单成功但库存完全没扣”或“库存扣了但订单没了”这类错误状态
可以把这个流程抽象成:
1
2
3
4
用户下单
-> 订单服务创建订单
-> 库存服务扣减库存
-> 积分服务发放积分
这三个动作放在不同方案里,事务边界完全不同。
11.2 方案一:TCC
TCC 适合把“订单确认”“库存预留”“积分预留”都显式建模成业务资源操作。
业务建模
- 订单服务:Try 创建待确认订单,Confirm 改为已创建,Cancel 关闭订单
- 库存服务:Try 冻结库存,Confirm 正式扣减,Cancel 释放冻结库存
- 积分服务:Try 预留积分账户额度或记录待发放,Confirm 真正加积分,Cancel 取消预留
流程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
下单请求
-> 订单服务 Try:创建订单,状态 = PENDING
-> 库存服务 Try:冻结 1 件库存
-> 积分服务 Try:预留 100 积分发放资格
如果三个 Try 都成功
-> 订单服务 Confirm:订单状态改为 CREATED
-> 库存服务 Confirm:正式扣减库存
-> 积分服务 Confirm:账户增加 100 积分
只要有一个 Try / Confirm 失败
-> 订单服务 Cancel
-> 库存服务 Cancel
-> 积分服务 Cancel
示例代码骨架
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public interface OrderTccService {
void tryCreate(OrderParam param);
void confirmCreate(String orderNo);
void cancelCreate(String orderNo);
}
public interface StockTccService {
void tryFreeze(String skuCode, int count);
void confirmDeduct(String skuCode, int count);
void cancelFreeze(String skuCode, int count);
}
public interface PointTccService {
void tryReserve(String userId, int point);
void confirmAdd(String userId, int point);
void cancelReserve(String userId, int point);
}
优缺点
- 优点:一致性强,可控性高,特别适合库存、余额、额度冻结这类业务
- 缺点:业务侵入极强,每个参与方都要实现 Try / Confirm / Cancel
- 难点:要额外处理幂等、空回滚、悬挂、重复确认
更适合这个案例里的哪部分
- 库存扣减最适合 TCC,因为库存天然适合“冻结 -> 扣减 -> 解冻”
- 积分发放通常不一定值得做成 TCC,因为积分一般允许异步到账
结论是:如果这个案例里“库存必须强控制,积分可以稍后到账”,那就很可能演变成“库存用 TCC,积分不用 TCC”。
11.3 方案二:本地消息表
本地消息表更像一种“先把订单创建稳住,再异步驱动库存和积分完成”的工程化方案。
核心思路
订单服务在一个本地事务里同时做两件事:
- 写入订单表
- 写入消息表
事务提交后,再由投递任务把消息发送给库存服务和积分服务。
流程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
步骤1:订单服务本地事务
- 插入 order 表,状态 = CREATED
- 插入 local_message 表,topic = order_created
步骤2:事务提交成功
- 投递任务扫描 local_message
- 发送 order_created 到 MQ
步骤3:下游消费
- 库存服务消费消息,扣减库存
- 积分服务消费消息,发放积分
步骤4:失败补偿
- 某个消费失败 -> 重试
- 超过阈值 -> 告警 / 人工处理
简化示例
1
2
3
4
5
6
7
8
9
10
11
@Transactional
public void createOrder(OrderParam param) {
Order order = orderRepository.save(Order.create(param));
LocalMessage message = new LocalMessage(
"order_created",
order.getOrderNo(),
toJson(order)
);
localMessageRepository.save(message);
}
消息投递任务:
1
2
3
4
5
6
public void dispatchPendingMessages() {
List<LocalMessage> messages = localMessageRepository.findPendingMessages();
for (LocalMessage message : messages) {
mqProducer.send(message.getTopic(), message.getBody());
}
}
优缺点
- 优点:实现稳定,工程可观测性好,数据库里能直接查消息状态
- 优点:订单服务不需要为库存和积分实现复杂的 Confirm / Cancel
- 缺点:库存和积分是异步完成的,存在短暂不一致窗口
- 缺点:需要维护消息表、投递任务、重试机制
这个案例里会出现什么状态
- 订单已创建,但库存还没扣
- 订单已创建,库存已扣,但积分还没发
- 某次消费失败后,系统靠重试恢复
这种方案的关键不在于“绝不出现中间态”,而在于“中间态最终可收敛,且过程可追踪、可补偿”。
更适合这个案例里的哪部分
- 积分发放非常适合本地消息表,因为通常允许异步到账
- 库存扣减要看业务。如果是热门秒杀库存,异步扣减风险就会更大;如果是普通商品库存,很多系统也会接受
11.4 方案三:RocketMQ 事务消息
RocketMQ 事务消息和本地消息表解决的是一类问题:订单本地事务提交后,如何可靠把“订单已创建”这个事实通知出去。
区别在于:本地消息表把消息状态存在业务库里,而 RocketMQ 事务消息把“半消息 + 回查”能力交给 MQ。
流程
1
2
3
4
5
6
7
8
9
10
11
12
步骤1:订单服务发送半消息
步骤2:Broker 持久化半消息,但消费者不可见
步骤3:订单服务执行本地事务
- 创建订单
步骤4:本地事务成功
- 向 Broker 返回 Commit
步骤5:Broker 投递消息
- 库存服务消费,扣减库存
- 积分服务消费,发放积分
步骤6:如果订单服务来不及返回结果
- Broker 回查订单服务
- 订单服务根据订单记录回答 Commit / Rollback
简化示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public LocalTransactionState executeLocalTransaction(Message msg, Object arg) {
OrderParam param = (OrderParam) arg;
try {
orderService.createOrder(param);
return LocalTransactionState.COMMIT_MESSAGE;
} catch (Exception e) {
return LocalTransactionState.ROLLBACK_MESSAGE;
}
}
public LocalTransactionState checkLocalTransaction(MessageExt msg) {
String orderNo = msg.getKeys();
return orderService.exists(orderNo)
? LocalTransactionState.COMMIT_MESSAGE
: LocalTransactionState.ROLLBACK_MESSAGE;
}
优缺点
- 优点:不需要自建消息表,消息投递和本地事务原子性更自然
- 优点:适合已经深度使用 RocketMQ 的系统
- 缺点:仍然是最终一致性,不是“订单、库存、积分同时原子成功”
- 缺点:回查逻辑必须做好,否则消息状态会长期悬而未决
更适合这个案例里的哪部分
- 和本地消息表一样,适合把“订单创建成功”这个事件可靠发给库存服务和积分服务
- 如果库存服务和积分服务都已经围绕 RocketMQ 建设事件驱动流程,这种方式会更顺手
11.5 三种方案放在同一案例里怎么理解
同样是“订单-库存-积分”,三种方案的事务边界完全不同:
| 方案 | 事务边界 | 一致性特点 | 适合点 |
|---|---|---|---|
| TCC | 订单、库存、积分都显式参与全局业务协作 | 更强,可控,但开发最重 | 核心库存、余额、额度 |
| 本地消息表 | 先保证订单本地事务,再异步驱动库存和积分 | 最终一致,可观测性强 | 普通订单、积分、通知 |
| RocketMQ 事务消息 | 先保证订单本地事务 + 消息可靠投递,再异步驱动下游 | 最终一致,依赖 RocketMQ | 事件驱动系统、RocketMQ 生态 |
再换一种更实战的说法:
- 如果你最怕的是“超卖”,优先思考库存是否要用 TCC 或其他强约束方案
- 如果你最怕的是“订单成功后消息丢了”,优先思考本地消息表或 RocketMQ 事务消息
- 如果你最在意的是“开发成本不能太高”,通常不会把积分发放做成 TCC
11.6 一个更接近真实业务的组合方案
真实项目里,经常不是三选一,而是组合使用。
例如这个案例很常见的一种拆法是:
- 订单创建:本地事务
- 库存扣减:TCC 或强约束库存中心
- 积分发放:本地消息表或 RocketMQ 事务消息异步发放
流程可以是:
1
2
3
4
5
用户下单
-> 订单服务本地事务创建订单
-> 同步调用库存服务做冻结 / 扣减
-> 订单提交成功后发送 order_created 事件
-> 积分服务异步消费事件并发放积分
这类组合方案背后的原则是:
- 高价值资源用更强控制
- 低价值可补偿动作用异步最终一致
- 不把所有动作都硬塞进同一种分布式事务模型里
11.7 这个案例最后该怎么选
如果让这个案例直接落地,可以按业务等级判断:
| 业务要求 | 更推荐方案 |
|---|---|
| 库存绝对不能错,积分允许延迟 | 库存用 TCC,积分用消息方案 |
| 普通电商,能接受秒级收敛 | 订单本地事务 + 本地消息表 / RocketMQ 事务消息 |
| 全链路都要求强控制,且团队能承受高复杂度 | TCC |
| 系统已经大量使用 RocketMQ | 优先考虑 RocketMQ 事务消息 |
| 系统更重数据库可观测性和通用性 | 优先考虑本地消息表 |
这个案例最值得记住的一点不是“哪种方案最好”,而是:
同一个业务流程里,不同子动作的一致性要求往往不同。库存、订单、积分不一定要用同一种事务方案,真正合理的设计通常是按资源价值和失败成本做拆分。
12. 复习时可以这样记
如果只想快速建立一条主线,可以按下面的顺序记:
- 单库事务靠数据库和 Spring
@Transactional - 跨服务事务无法再靠单库事务兜底
- 强一致性方案有 XA / 2PC 思路,但性能成本高
- 业务型方案有 TCC,适合资源预留类业务
- 长流程方案有 Saga,靠补偿收敛
- 工程上最常见的是消息最终一致性:本地消息表或事务消息
- Spring 面试核心主要看传播行为、隔离级别、AOP 原理、失效场景、回滚规则
再压缩成一句话:
单库靠本地事务,跨服务靠分布式协调,而高并发业务里最常落地的是“本地事务 + 可靠消息 + 补偿重试”的最终一致性方案。