[TOC]
深分页
limit实现,但是当偏移量特别大的时候,查询效率就变得低下
个人理解:limit 执行策略,先拿到完整结果集,再从结果集中,丢弃前 100w 数据,只返回20条
那么这里就有问题了,完整结果集,要回表,数据量大,必然慢
优化的点:尽量依赖覆盖索引,避免回表。锁定 索引键范围后,再小批量的查询
InnoDB 页
MySQL 的默认存储引擎 InnoDB
内存页(也称 “数据页”)大小是核心配置之一,直接影响 I/O 效率和数据存储布局,默认16KB,可通过参数 innodb_page_size 调整,支持的取值包括 4KB、8KB、16KB、32KB、64KB
InnoDB 页,可以理解成 B+ 树的一个节点
每个页中,存的是数据元素
非叶子节点: 索引键 + 指针,指针指向新的 InnoDB 页,也就是页号 子节点:
-
聚簇索引(主键索引),存完整行记录。聚簇索引核心:索引即数据
-
二级索引(非主键索引),存 主键 + 指针
在 InnoDB 的 B+ 树索引中,指针通常占用6个字节
假设 1个主键,占用8个字节,那么一个元素就是 8+6=14个字节。一个页16kb,能存 16kb*1024/14
问题一:行记录大于16kb,超出了innodb的默认页大小
行溢出机制
InnoDB 5.7+ 的处理方式
1、MySQL的默认行格式DYNAMIC 2、完全外部存储:整个BLOB/TEXT/VARCHAR列(如果太大)存储在外部页中 3、数据页中只存储20字节的指针 4、使用专门的BLOB页来存储大对象数据
InnoDB有自动的溢出检测机制:
-
默认阈值:约8000字节(页大小的一半)
-
影响因素:行格式、字段类型、页大小配置
B树和B+树的核心区别
叶子节点、非叶子节点 的存储上有区别
B树:任何节点都存储数据
B+树:只有叶子节点,存数据
会导致,树的层级较高
问题一:为什么不用二叉树
二叉树,就2个子节点,还不如 B 树,树层级太高了
问题二:为什么不用 HashMap
- HashMap 要根据key 做 hash,没法模糊查询
- 范围查询也没支持
表设计初期就要考虑调优问题
每个字段用多大的量
量的上限严格把控,因为和 innodb 索引有关系,尽量减少I/O次数
定义索引,随机性越高,效率越高
SHOW INDEX FROM table_name
cardinality: 索引的基数。这是一个估算值,表示索引中唯一值的数量,值越接近1,说明值越分散
联合索引查询问题
A、B 2个字段联合索引,where A > 2,B=3
结合索引B+树的特性,节点是有序的。固定第一个字段的时候,第二个字段才是有序的
- 联合索引为 (A, B)
- 索引的逻辑结构:先按 A 排序,A 相同的记录再按 B 排序。
- 查询分析:A > 2 是范围查询,会导致索引中 A 右侧的 B 字段失效(因为 A>2 的记录中,B 的值是无序的,无法通过索引快速定位 B=3)。
- 实际效果:只能利用索引中 A 字段的部分(快速定位 A>2 的记录),但 B=3 的过滤需要在内存中完成(无法利用 B 部分的索引)
- 联合索引为 (B, A)
- 索引的逻辑结构:先按 B 排序,B 相同的记录再按 A 排序。
- 查询分析:B=3 是等值查询,可通过索引快速定位所有 B=3 的记录(这些记录在索引中是连续的);且在 B=3 的范围内,A 是有序的(因为索引按 B 排序后,相同 B 再按 A 排序),因此 A>2 可以继续利用索引的 A 部分快速过滤。
- 实际效果:整个查询能完整利用联合索引 (B,A),先定位 B=3,再在该范围内定位 A>2,效率很高
回表
结合 索引B+树节点存储的内容,有助于理解什么是回表 聚簇索引,存的是主键 primary key 非聚簇索引,非叶子节点 存的是 索引键
当使用二级索引(非主键索引)进行查询时,如果查询的字段不全部包含在二级索引中,MySQL需要先通过二级索引找到对应的主键值(其实这里已经查到B+树的叶子节点了,只有叶子节点上,是存了主键值),然后再用这些主键值回到聚簇索引(主键索引)中查找完整的行数据
总结:
- 查询时只选择需要的字段,避免 SELECT *
- 优先使用主键查询获取单条记录
索引下推
核心思想: 将WHERE条件中索引列的过滤操作”下推”到存储引擎层执行,而不是在Server层执行
在索引扫描阶段就过滤掉更多不满足条件的记录,减少不必要的回表操作
注意下,其实核心,还是利用的联合索引。就比如提到的(A,B)字段,where A>2 and B = 3 的查询,其实B字段是走不了索引的,这个时候就是索引下推提前过滤
索引失效快捷记忆
LOL
L:like查询,根据最左匹配原则
O:or查询,A or B,2个字段都是索引字段的时候,索引不失效。只要其中1个不是索引字段,失效
L:联合索引查询,(A,B),where B>2,不走索引,因为A没确定。要从首个索引列开始
加减乘除
where a+1 = 2,有运算的,索引实效
not
!=
<>
is not
where age != 10,失效
mysql总取非的结果集,索引会失效
null
where age is not null 可能用到索引,mysql允许索引值为null,但是处于游离在B+树节点边缘。不为null的字段,创建的时候最好加上 not null 限制,便于后期加索引。如果不清楚字段值的,建议设置默认值
mysql内置函数
where date_add(date, -1) = 2021, 索引失效
where date = date_add(CURDATE(), -1),索引生效
隐式类型转换
MRR 优化
主要解决随机I/O问题,特别适用于范围查询和二级索引查询
举例:索引查到叶子节点,拿到id=[1001, 2045, 3056, 4089, 5102, …],随机回表,按找到的主键顺序访问聚簇索引。主键值在磁盘上可能是随机分布的,导致大量随机磁盘寻道
关键机制:排序 + 批量顺序读取
单纯排序并不能完全解决随机I/O,但结合InnoDB的存储特性、页机制和磁盘预读,MRR能显著改善I/O模式,从”完全随机”变成”相对顺序”
InnoDB的预读机制会被触发:
线性预读:如果顺序访问N个页,预读下一个范围的页
随机预读:检测到当前页中的记录可能被连续访问
MRR的执行过程
-
收集阶段:扫描二级索引,收集所有需要的主键值
-
排序阶段:将收集到的主键值进行排序
-
批量回表:按排序后的主键顺序访问聚簇索引
MVCC 多版本并发控制
Multi-Version Concurrency Control,多版本并发控制,也叫一致性非锁定读
- 基于回滚机制,为并发场景下的读操作做的优化
- 多版本是为读操作控制的,并发环境下,读操作不需要被锁定的目的
Read View是MVCC机制中的”可见性判断器”,它决定了事务能够看到哪些数据版本
第一次读会生成Read-view视图
Read View 是InnoDB为每个事务创建的一个”数据快照视图”,它包含了判断数据版本可见性所需的所有信息
Read View
Read View 是 MySQL InnoDB 实现 MVCC 和事务隔离级别的核心数据结构
本质是一个”数据可见性快照”,它定义了事务能够看到哪些数据版本
mysql 4种隔离级别:由低到高 排序
MVCC在事务隔离级别当中的应用
读未提交数据
MVCC几乎不起作用。相当于及时性读取,MVCC多版本控制没意义
A、B 线程,写线程 C 线程,读线程
场景: A、C 同时向一条数据,发起读和写操作
1、C先发起了读操作
2、A发起了写操作,写操作会生成一份快照,undo log,用于回滚
A还没有提交事务,但是这个时候C线程过来读,可以拿到A没提交的数据,更像是一种中间缓存数据
如果能读中间态的数据,并发环境下乱套了
mysql 的 脏读,就发生在 读未提交
读已提交数据
A、B 线程,写线程 C 线程,读线程
场景: A、B 线程,写线程 C 线程,读线程
场景: A、C 同时向一条数据,发起读和写操作
1、C先发起了读操作
2、A发起了写操作,写操作会生成一份快照,undo log,用于回滚
3、A修改完成后,提交数据
这个时候,MVCC 有2个数据版本。A修改之前的版本,A修改之后的版本
4、B线程发起写操作,继续生成一份快照
5、B修改完成,提交数据
这个时候,MVCC 有3个数据版本。A修改之前的版本,A修改之后的版本,B修改之后的版本
读取提交数据 可能出现:幻读、不可重复读
不可重复读:对同一条数据,2次读结果不一样 (修改导致) 幻读:执行同一条语句,查出来的数量不一样 (新增或删除导致)
C 再读,读取的最新版本,也就是B提交之后的数据
可重复读 (mysql 默认)
A、B 线程,写线程 C 线程,读线程
场景: A、C 同时向一条数据,发起读和写操作
1、C先发起了读操作
2、A发起了写操作,写操作会生成一份快照,undo log,用于回滚
3、A修改完成后,提交数据
这个时候,MVCC 有2个数据版本。A修改之前的版本,A修改之后的版本
4、B线程发起写操作,继续生成一份快照
5、B修改完成,提交数据
这个时候,MVCC 有3个数据版本。A修改之前的版本,A修改之后的版本,B修改之后的版本
问题一:读未提交有脏读;读已提交有幻读、不可重复读,可重复读是怎么解决的
利用锁机制
innoDB存储引擎采用Next-Key Locking 临键锁 这种锁定算法
行锁 + 间隙锁 组合解决 幻读
C 再读,读取的还是第一个最原始的版本
串行读
读写,都是串行的。
问题一:读已提交,不满足 ACID 中的隔离性
A、B 线程,写线程
C 线程,读线程
C开启事务
AB开启事务修改完成后提交
C再读,读的是 B 修改后的数据
AB事务影响了 C 线程,违反了事务隔离性
mysql 锁
总结:mysql锁有3种锁定算法
1、锁行:但其实锁的是索引
2、锁范围:间隙锁,锁定一个范围,但不包含记录本身
3、锁行+锁范围:Next-Key Locks 临键锁
当查询的索引含有唯一属性时,InnoDB存储引擎会对Next-Key Lock进行优化,将其降级为Record Lock,即仅锁住索引本身,而不是范围
什么是唯一属性,其实就是我们所说的能够标识该行数据唯一的标识。unique 字段。比如:主键就是唯一的,不重复的
锁的区间,左开右闭
mysql 插入
自增长id,永远不重复,说明数据安全,说明有锁。有锁就涉及到性能问题
锁的是自增长计数器
事务的提交,涉及到mysql持久化问题(持久化到磁盘,必然有消耗)
mysql对并发大数据量插入的情况下,老版本,还是一个个锁定自增。新版本有互斥量的概念
互斥量,在已知插入量的情况下,预分配id。如果不知道插入量,延用老版本的策略,一个个锁定
极端策略,总是使用互斥量,那么会导致id不连续。从而影响mysql主从同步
mysql日志系统
bin log
记录的是mysql执行语句的log日志
做主从同步
bin log 数据恢复
PITR(Point-In-Time Recovery,时间点恢复)
Binlog(二进制日志)和 PITR(Point-In-Time Recovery,时间点恢复)是 MySQL 数据备份与恢复体系的核心组件,二者紧密配合,可实现 “将数据库恢复到过去任意时间点的状态”,尤其适用于误操作(如误删表、误更新)后的精确恢复
Binlog 的核心作用
- 主从同步:主库通过 Binlog 将数据变更同步到从库(之前讲主从同步时已详述)
- 数据恢复:通过重放 Binlog 中的操作,可恢复误删除 / 修改的数据,或回滚到历史状态
- 审计追踪:分析 Binlog 可追溯 “谁在何时做了什么变更”(需结合日志中的时间戳和用户信息)
全量备份(如每天凌晨 2 点备份)只能将数据库恢复到备份时刻的状态,若误操作发生在 “备份之后、下次备份之前”(如凌晨 3 点误删表),仅靠全量备份会丢失 1 小时的数据。而 PITR 可结合全量备份和 Binlog,精确恢复到误操作前的瞬间(如凌晨 2:59),最大限度减少数据丢失
redo log(重做日志,也就是持久化)
记录是 mysql 内存页的修改逻辑
只有事务真正commit后,才会从 redo_log_buf 刷到到磁盘 redo log 中
三种策略
- 每commit一次:进行一次 sync 刷新磁盘
- 每一秒:进行一次 sync
- 不刷新:不做持久化,没有redo log文件
undo log
做事务回滚
主从同步
MySQL早期只有 statement 这种bin log格式,这种格式下,bin log记录的是SQL语句的原文
当出现事务乱序的时候,就会导致备库在 SQL 回放之后,结果和主库内容不一致
为了解决这个问题,MySQL默认采用了Repetable Read这种隔离级别,因为在 RR 中,会在更新数据的时候增加记录锁的同时增加间隙锁。可以避免这种情况的发生
RC + row
RR + statement
但 rc 模式,数据更真实,性能也更好。大型互联网主要用 rc, Oracle、Sql server 默认级别都是 rc
mysql 默认级别是 rr,也是当年的无奈之举
主从同步 数据流向
主库数据变更 → 写入Binlog → Binlog Dump发送 → 从库I/O线程接收 → 写入Relay Log 中继日志 → SQL线程重放 → 从库数据更新
主从同步 复制格式
- statement 基于语句
优点:二进制日志小,网络传输少 缺点:非确定性函数可能造成主从不一致(有一些函数不敢用,比如 current()、uuid)
- row 基于行
优点:数据一致性最好 缺点:二进制日志大,特别是批量操作时
- mixed 混合模式
大部分情况使用STATEMENT,特殊情况自动切换到ROW 比如包含UUID()、RAND()等非确定性函数时使用ROW
问题一:主从结构,从节点能不能继续挂从节点
理论上可以,但是对中间层的从节点,压力过大,所以不推荐,生产也不这么干
主库 → 从库1(也作为主库) → 从库2
原因:主节点下面直连的从节点,默认情况下是不写binlog日志的,减少磁盘I/O,如果从节点下面继续挂从节点,那么中间层必须开启 binlog 日志,不仅要写日志,还要承担 binlog 日志传输
问题二:多主多从模式下,insert 语句,怎么保证 id 自增长不冲突
核心方案:通过 auto_increment_offset 和 auto_increment_increment 控制自增序列
MySQL 提供了两个全局参数,用于定制自增 ID 的起始值和步长,从而让不同主库生成的 ID 序列完全不重叠
| 参数 | 作用 | 取值范围 |
|---|---|---|
| auto_increment_offset | 自增 ID 的起始值(偏移量) | 1 ~ 65535 |
| auto_increment_increment | 自增 ID 的步长(每次增加的值) | 1 ~ 65535 |
假设集群中有 N 个主库,通过以下配置让每个主库的自增 ID 序列独立:
步长 auto_increment_increment 设为 N(主库数量); 每个主库的 auto_increment_offset 设为唯一值(1, 2, …, N)
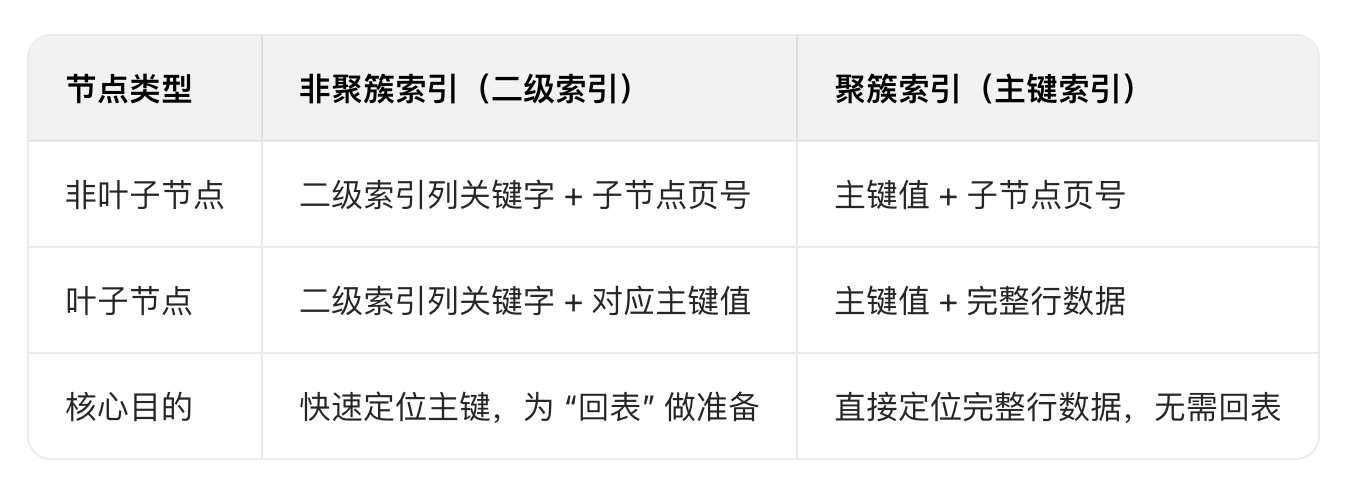
主从同步 全同步复制
要求所有的从库也都必须执行完该事务,才可以返回处理结果给客户端
性能比较低
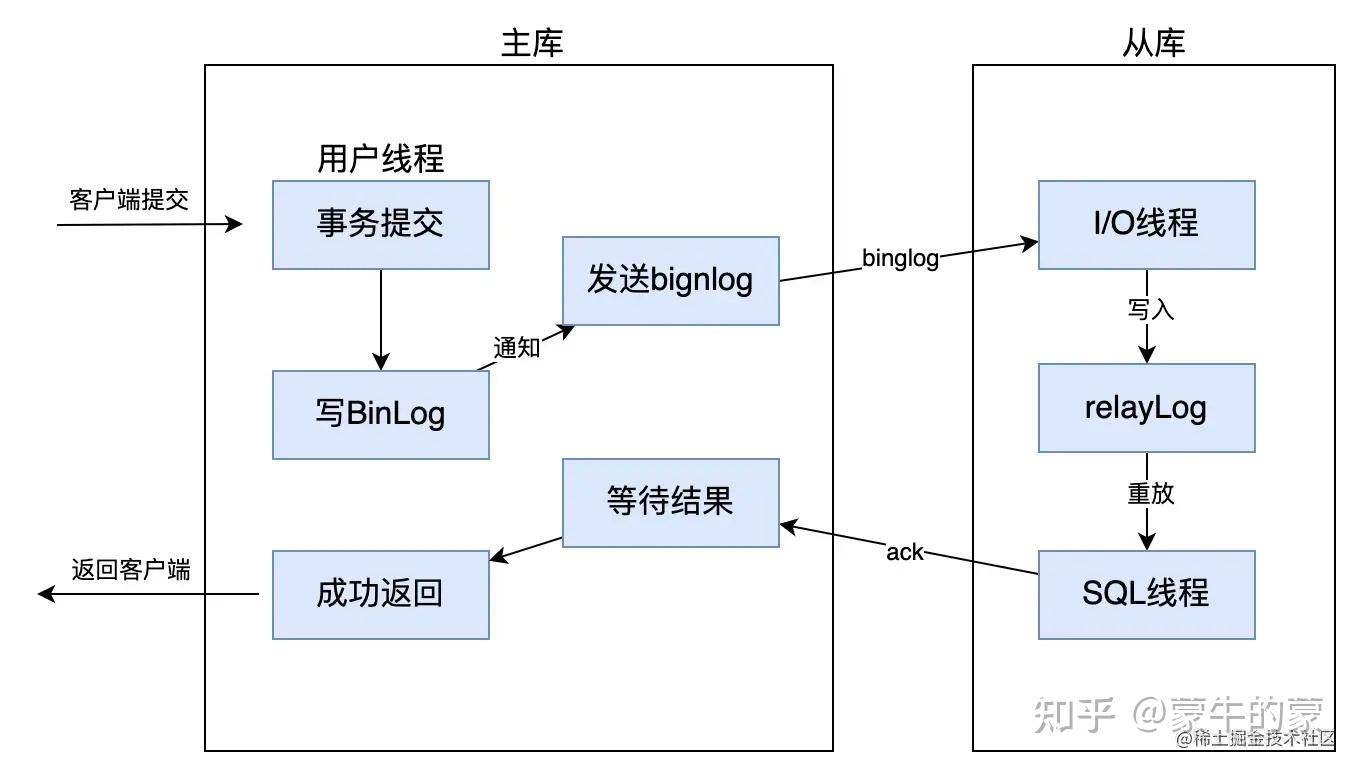
主从同步 异步复制
binlog dump 线程发送 binlog 日志给从库,一旦 binlog dump 线程将 binlog 日志发送给从库之后,不需要等到从库也同步完成事务,主库就会将处理结果返回给客户端
导致短暂的主从数据不一致的问题了,比如刚在主库插入的新数据,如果马上在从库查询,就可能查询不到
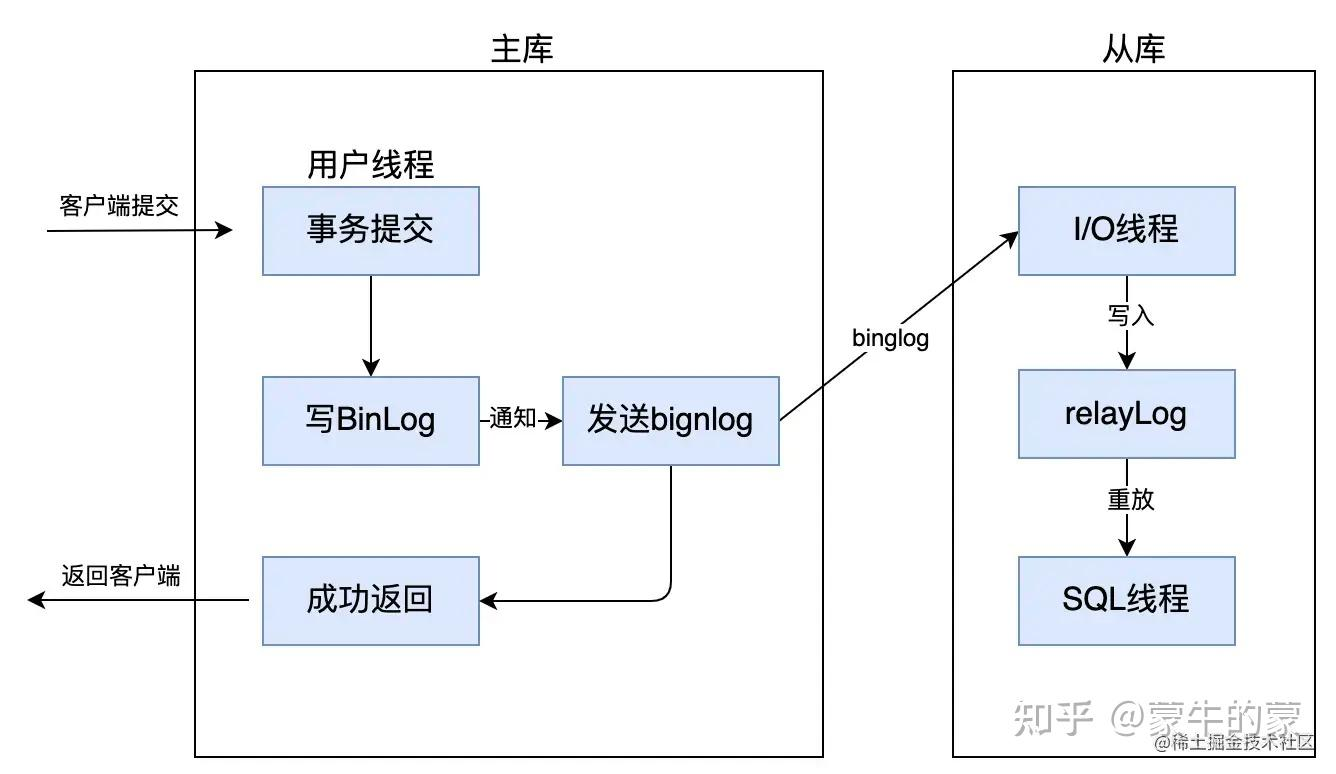
主从同步 半同步复制
客户端提交事务之后不直接将结果返回给客户端,而是等待至少有一个从库收到了 Binlog,并且写入到中继日志中,再返回给客户端
提高了数据的一致性,当然相比于异步复制来说,至少多增加了一个网络连接的延迟,降低了主库写的效率
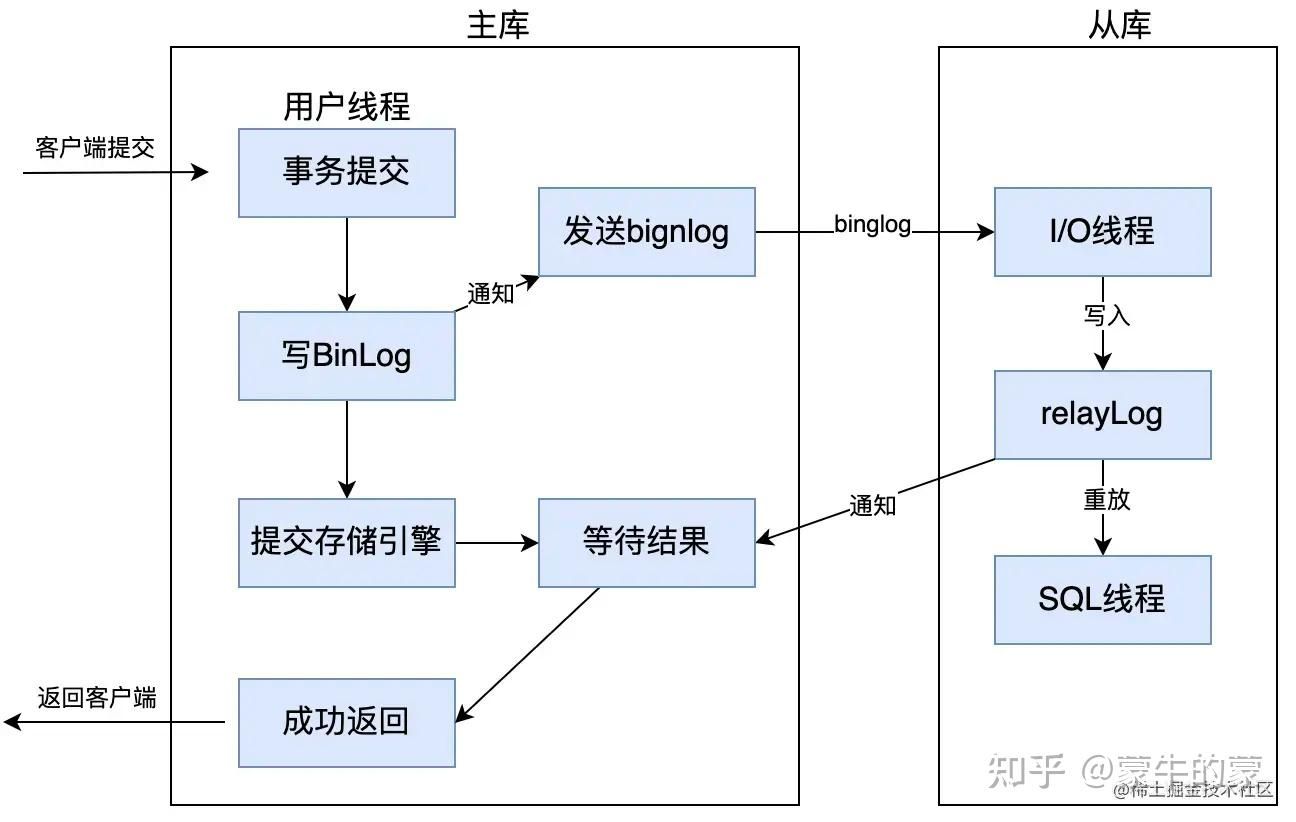
主从同步 增强半同步复制
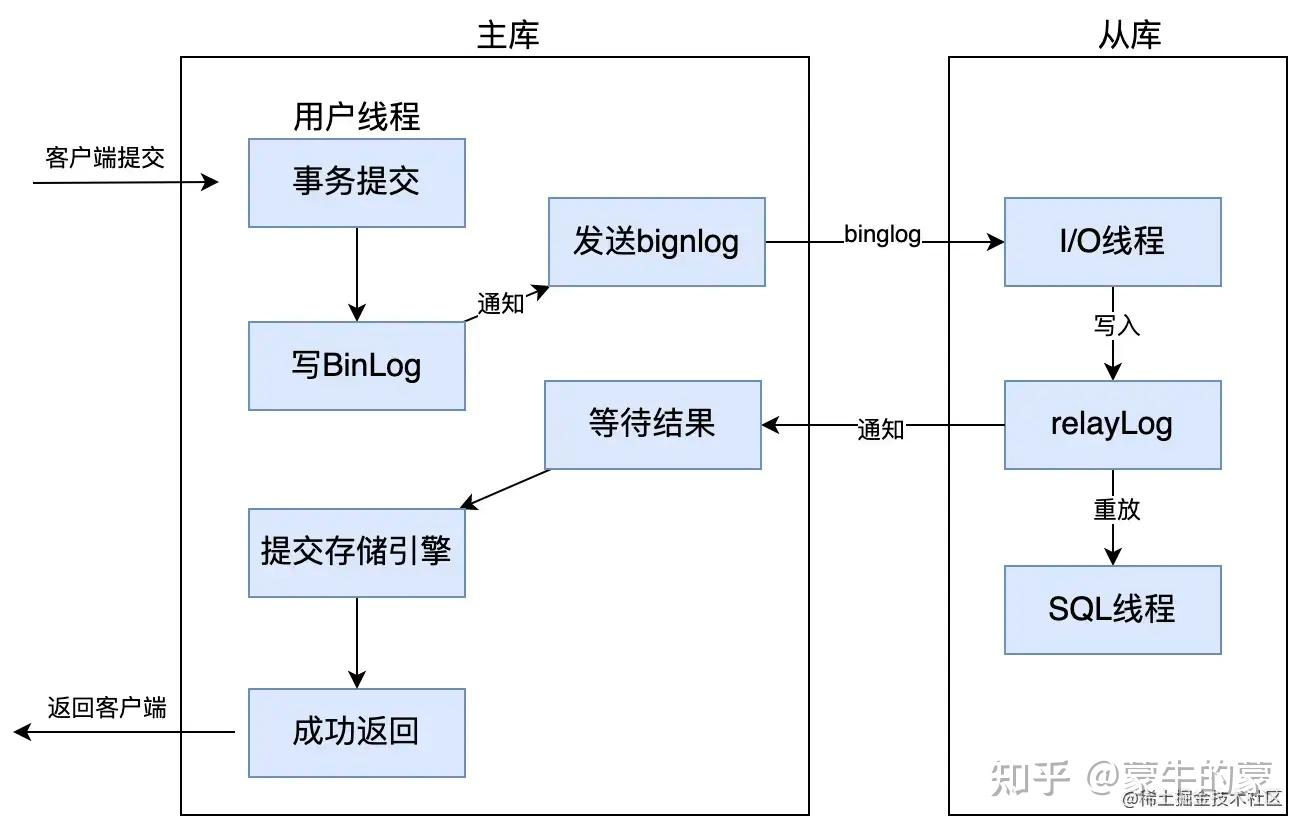
是 MySQL 5.7.2后的版本对半同步复制做的一个改进,原理上几乎是一样的,主要是解决幻读的问题
主库在存储引擎提交事务前,必须先收到从库数据同步完成的确认信息后,才能提交事务,以此来解决幻读问题
新的从节点,数据同步流程
总结:
-
mysqldump 备份主库(加 –single-transaction)
-
备份文件拷到从库并导入
-
在从库执行 CHANGE MASTER TO … MASTER_AUTO_POSITION=1;
-
在从库执行 START SLAVE;
-
执行 SHOW SLAVE STATUS\G 检查状态
flowchart TD
A[准备新从库服务器] --> B
subgraph B [第一步: 主库热备份]
B1[主库: mysqldump备份<br>(不锁表/短暂锁表)] --> B2[得到备份文件<br>master_data.sql]
end
B --> C
subgraph C [第二步: 从库恢复数据]
C1[从库: 导入备份文件] --> C2[从库数据与主库<br>备份时状态一致]
end
C --> D
subgraph D [第三步: 建立同步]
D1[从库: 配置主库信息<br>(CHANGE MASTER TO)] --> D2[从库: 启动同步<br>(START SLAVE)]
end
D --> E[监控同步状态<br>(SHOW SLAVE STATUS)]
使用 mysqldump 工具,登录主库服务器,执行以下命令进行备份:
1
mysqldump -u root -p --all-databases --single-transaction --master-data=2 > /tmp/master_data.sql
–all-databases:备份所有数据库
–single-transaction:这个参数最重要! 它会在备份开始前启动一个事务,确保拿到一个一致性的数据快照,并且不会锁表,对线上业务影响极小
–master-data=2:这个参数会在备份文件里,以注释的形式记录下备份时主库的二进制日志位置。这是从库开始同步的起点,至关重要
union 和 union all
| 特性 | union | union all |
|---|---|---|
| 重复数据 | 自动去重 | 全部保留 |
| 性能 | 较慢(需去重) | 更快 |
| 结果排序 | 默认按首列 | 原始顺序 |
| 适用场景 | 需要数据唯一 | 原始数据 |