这篇笔记的目标是从入门视角把 Elasticsearch 最常见的一组知识点串起来,包括倒排索引、分词器、分片与副本、写入与查询链路,以及使用时最容易混淆的版本差异。
正文以前半部分的现代 Elasticsearch 通用概念为主,尽量避免把 2.x、7.x、8.x 的行为混在一起;文末只保留一段旧版 Java API 附录,用来识别历史接口和兼容老项目,不作为新版本写法参考。
参考资料:
Elastic Docs - Elasticsearch Guide
[TOC]
什么是 Elasticsearch
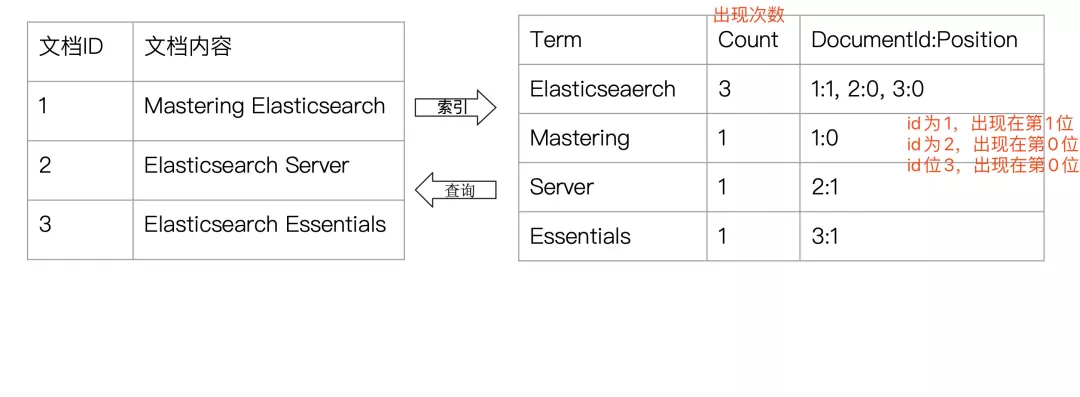
Elasticsearch 是一个基于 Lucene 的分布式搜索与分析引擎,常用于全文检索、结构化过滤、聚合分析和日志检索等场景。它对外提供 HTTP/REST API,内部依赖 Lucene 完成索引和查询。
有两个表述特别容易混淆:
- Elasticsearch 的搜索能力通常是近实时的。文档写入后,往往需要一次
refresh之后才能被普通搜索看到,默认周期通常是 1 秒左右。 - 通过文档 ID 的
GET查询通常是实时的,因为它可以直接利用更接近写入链路的数据结构,而不必等待搜索刷新。
ES 使用倒排索引来支持全文检索,这也是它相比关系型数据库更擅长处理文本搜索、相关性排序和复杂搜索语法的核心原因。
为什么要用 Elasticsearch
关系型数据库也能做检索,但它的主要优化方向并不是全文搜索。拿文本检索来说,ES 更擅长的不是一句“模糊查询很快”,而是下面这几件事组合起来的能力:
- 全文检索: 先分词再建立倒排索引,适合从词查文档,而不是从完整字段值查记录。
- 相关性排序: 搜索结果天然带
_score,可以把更相关的结果排在前面。 - 搜索容错: 通过分析器、
fuzzy query、建议器等机制,可以处理拼写错误、前缀搜索、联想搜索等需求。 - 过滤与聚合: 既能查文档,也能做分组、统计、区间分析。
- 分布式扩展: 数据天然按分片分布,可以横向扩容。
需要注意的是,ES 并不意味着“所有模糊搜索都便宜”。像 wildcard、regexp、高代价的 fuzzy 查询,如果使用不当,同样会很贵。ES 的核心优势主要来自倒排索引 + 合理 mapping + 合理查询模型。
Elasticsearch 的数据结构
如果把数据库索引类比为“为了更快查询而设计的数据组织方式”,那么:
- MySQL 常见索引底层通常可以近似理解为 B+ 树。
- Elasticsearch/Lucene 的全文检索核心则是倒排索引。
正排和倒排
这一块是理解搜索引擎的关键。很多材料会一句话带过“倒排索引就是从词找到文档”,这句话没有错,但太短了,容易让人不知道它和普通数据库索引到底差在哪。
先给一个更准确的直觉:
- 正排索引: 以文档为中心组织数据,更像
doc -> fields/terms - 倒排索引: 以词项为中心组织数据,更像
term -> docs
换句话说,正排关心“这篇文档里有什么”,倒排关心“这个词出现在哪些文档里”。
先从一个最小例子看
假设有三篇文档:
1
2
3
Doc1: Elasticsearch 入门实战
Doc2: Lucene 与倒排索引
Doc3: Elasticsearch 与 Lucene
如果按正排视角组织,数据更像这样:
1
2
3
Doc1 -> [elasticsearch, 入门, 实战]
Doc2 -> [lucene, 倒排索引]
Doc3 -> [elasticsearch, lucene]
如果按倒排视角组织,数据更像这样:
1
2
3
4
5
elasticsearch -> [Doc1, Doc3]
lucene -> [Doc2, Doc3]
入门 -> [Doc1]
实战 -> [Doc1]
倒排索引 -> [Doc2]
这两种组织方式都能回答问题,但擅长的问题不同:
- 如果问题是“Doc1 里有哪些词”,正排更直接
- 如果问题是“哪些文档包含
elasticsearch”,倒排更直接
而搜索引擎最常见的问题,恰恰是第二种。
为什么全文搜索天然更偏向倒排
假设用户搜索“elasticsearch”,如果系统只有正排结构,那么最朴素的做法是:
- 扫描 Doc1,看有没有这个词
- 扫描 Doc2,看有没有这个词
- 扫描 Doc3,看有没有这个词
- 把命中的文档收集起来
文档少的时候没问题,但一旦有百万、千万甚至更多文档,这种“逐篇扫描”的代价就太高了。
倒排索引的思路正好反过来:
- 先定位词项
elasticsearch - 直接拿到它对应的文档列表
[Doc1, Doc3] - 再在这些候选文档上做打分、排序、过滤
核心收益就在这里:把“扫描全部文档”变成“直接定位候选文档集合”。
写入时,正排和倒排分别是怎么来的
Elasticsearch 写入一篇文档时,并不是只保存 _source 原文,然后查询时临时拆词。真正发生的过程更像这样:
- 文档先以 JSON 形式写入
- 文本字段按 mapping 指定的分析器做分析
- 文本被切成一个个 term
- 每个 term 被写入对应的倒排结构
- 文档本身也会保留取回原文所需的数据结构
以这条文档为例:
1
2
3
{
"title": "Elasticsearch 入门实战"
}
如果 title 是 text 字段,写入后大致会发生两件事:
- 从文档视角,系统知道
Doc1.title = "Elasticsearch 入门实战" - 从词项视角,系统也知道
elasticsearch、入门、实战分别出现在哪篇文档里
因此可以把它理解成:写入一篇文档时,搜索引擎会把“文档视角”和“词项视角”都准备好,但全文检索主要依赖的是词项视角。
查询时,倒排索引是怎么工作的
再看一次用户输入关键词时的链路。以查询“算法”为例,实际过程可以粗略拆成下面几步:
- 用户输入查询词
"算法" - 查询词先经过搜索期分析器,被切成一个或多个 term
- Lucene 到
Term Dictionary里查找这些 term - 找到 term 对应的
Posting List - 如果是多个词,就对多个 posting list 做交集、并集或更复杂的布尔运算
- 根据词频、位置、BM25 等规则计算相关性分数
- 再去取回文档内容,返回最终结果
这一过程真正快的地方,不在于“算分”本身,而在于前面几步已经把候选集快速缩小了。
倒排索引里到底存了什么
很多入门材料会说“倒排索引就是 term 对应 docId 列表”,这只说对了一半。更完整地看,一个 term 对应的 posting list 往往不只包含文档编号,还可能包含:
- docID: 这个词出现在哪些文档里
- term frequency: 在单篇文档里出现了多少次
- position: 出现在文档中的什么位置
- offset: 在原文本里的字符偏移
这些额外信息非常重要:
- 有了
term frequency,才能参与相关性打分 - 有了
position,才能支持短语查询,例如match_phrase - 有了
offset,才能更好地支持高亮
所以可以把倒排索引理解成:不是简单的“词 -> 文档列表”,而是一套围绕词项检索设计的文档命中与定位结构。
正排是不是就没用了
也不能这么理解。搜索系统并不是“只有倒排索引”。
至少从使用效果上看,系统还需要解决这些问题:
- 命中文档之后,怎么把
_source原文返回给用户 - 排序和聚合时,怎么高效读取某个字段的值
- 高亮时,怎么知道原文片段在哪
因此 Elasticsearch/Lucene 内部除了倒排结构,还会维护面向文档取回、字段读取和列式访问的其他结构。严格说来,它不是“只靠倒排活着”,而是:全文检索的主入口依赖倒排,结果取回和部分排序聚合则依赖其他辅助结构。
这也是为什么在 ES 里会同时看到:
inverted index:解决全文检索doc values:常用于排序、聚合、脚本访问_source/ stored fields:用于返回原文
所以“正排”和“倒排”更适合看成两种观察数据的视角,而不是非此即彼的二选一。
倒排索引、doc values、_source 各自负责什么
如果只把 ES 理解成“倒排索引很快”,通常还是会在排序、聚合和取回原文这些地方犯糊涂。更准确的理解方式是:一篇文档写入后,ES 会为不同用途准备不同结构。
这三者可以先用一句话区分:
- 倒排索引: 负责“从词找到文档”,服务全文检索
doc values: 负责“按字段读取值”,服务排序、聚合、脚本和部分过滤_source: 负责“把原始文档取回来”,服务结果展示和回显
1. 倒排索引负责“查谁命中”
倒排索引最核心的任务是回答这类问题:
- 哪些文档包含
elasticsearch - 哪些文档同时包含
java和lucene - 哪些文档里这个短语是连续出现的
它的工作重点是:
- 快速定位候选文档集合
- 为相关性打分提供词频、位置等信息
- 支撑
match、match_phrase、multi_match这类全文查询
可以把它理解成搜索阶段的“候选集入口”。搜索词先变成 term,再通过倒排找到可能命中的文档。
2. doc values 负责“按列取值”
doc values 常常最容易被忽略,但它对现代 Elasticsearch 很重要。它不是用来做全文检索的,而是更像一种面向字段的列式存储视图。
如果倒排索引更像:
1
term -> docs
那么 doc values 更像:
1
field -> docID -> value
它特别适合回答下面这些问题:
- 把结果按
created_at排序 - 统计每个
status各有多少条 - 计算
price的最大值、平均值、分组统计 - 在脚本里读取某个字段值
也就是说,doc values 的重点不是“谁命中”,而是“命中之后,怎么高效拿字段值来排序、聚合和计算”。
这也是为什么:
text字段通常不适合直接排序或聚合keyword、数值、日期、布尔类型更适合做过滤、排序和聚合
因为后者更容易走 doc values 这类结构,而不是把全文检索结构硬拿来做列式计算。
3. _source 负责“把原文还原回来”
_source 保存的是文档写入时的原始 JSON。它最重要的价值不是搜索,而是“返回结果时还能把原文取回来”。
例如这条文档:
1
2
3
4
5
{
"title": "Elasticsearch 入门实战",
"author": "Ekko",
"status": "published"
}
当查询命中它之后,接口响应里之所以还能看到完整字段,核心原因就是 ES 保留了 _source。
所以 _source 更像:
- 搜索命中后的结果载体
- 文档详情页的数据来源
- 更新、重建、重放时的重要基础数据
它不是主要用来做全文匹配的,也不是主要用来做高性能排序聚合的。
4. 三者分别处在查询链路的哪一步
把一次常见查询拆开,就更容易看出它们的分工:
- 用户输入关键词
- 查询词被分析成 term
- 倒排索引 找到候选文档
- 过滤、布尔组合、相关性打分继续收敛结果
- 如果需要排序或聚合,读取
doc values - 最终返回命中文档时,再取
_source
所以它们并不是彼此替代,而是分工协作:
- 倒排索引决定“查到谁”
doc values帮助“怎么排、怎么统、怎么算”_source负责“最后把什么返回给用户”
5. 一个最容易混淆的误区
很多初学者会把“搜索快”理解成所有字段访问都靠倒排索引,这其实不准确。
更接近真实情况的是:
- 全文查询主要依赖倒排索引
- 排序和聚合主要依赖
doc values - 返回原文主要依赖
_source
这也是为什么一个字段的 mapping 设计,会直接影响它到底适合做什么。
写入一篇文档后,ES 内部大致生成了哪些结构
把写入过程具体展开后,就更容易把这些结构连起来看。假设写入下面这篇文档:
1
2
3
4
5
6
7
{
"title": "Elasticsearch 入门实战",
"tags": ["搜索", "Lucene"],
"status": "published",
"price": 99.0,
"created_at": "2026-06-10T10:00:00Z"
}
如果 mapping 大致是:
title:text,并带一个keyword子字段tags:keywordstatus:keywordprice:doublecreated_at:date
那么写入后,可以粗略理解为 ES 内部会准备下面几类结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
写入一篇 JSON 文档
|
v
+------------------------------+
| 1. 保留原始文档 `_source` |
| title, tags, status, price...|
+------------------------------+
|
+------------------------------+
| |
v v
+------------------------------+ +------------------------------+
| 2. 文本字段走 analyzer | | 3. 结构化字段直接编码存储 |
| title -> terms | | status / price / created_at |
+------------------------------+ +------------------------------+
| |
v v
+------------------------------+ +------------------------------+
| 4. 写入倒排索引 | | 5. 写入 doc values |
| term -> posting lists | | docID -> field value |
+------------------------------+ +------------------------------+
| |
+---------------+--------------+
|
v
+------------------+
| 6. refresh 后可搜 |
+------------------+
如果把这张图再翻译成“字段 -> 结构”的视角,大致会是:
title这个text字段:- 会先被分析成多个 term
- term 会进入倒排索引
- 如果有
title.keyword子字段,还会额外保留一个可用于精确匹配、排序、聚合的keyword视图
status这类keyword字段:- 不做全文分词
- 适合精确过滤
- 通常也适合排序和聚合
price、created_at这类原生结构化字段:- 不走全文分词
- 更适合范围查询、排序和统计
- 整篇文档:
- 原始 JSON 会保留在
_source - 便于查询命中后直接返回给用户
- 原始 JSON 会保留在
从“字段用途”再看一次
写入后内部结构大致可以对照成下面这样:
| 字段/结构 | 主要用途 |
|---|---|
| 倒排索引 | 全文检索、相关性匹配、短语查询 |
doc values |
排序、聚合、脚本取值、部分过滤 |
_source |
返回原文、查看详情、回显完整文档 |
为什么同一篇文档会生成多套视图
原因并不复杂:搜索、统计和回显,本来就是三类不同问题。
如果只保留 _source 原文:
- 能把文档存下来
- 但全文检索会很慢
- 排序和聚合也不高效
如果只保留倒排索引:
- 能快速找命中文档
- 但不适合直接做列式统计
- 返回原始 JSON 也不方便
如果只保留 doc values:
- 适合排序和聚合
- 但不适合做全文检索
所以 ES 实际做的是:同一份业务数据,为不同查询目标准备不同存储视图。
一个更贴近流程的类比
如果把一本书类比成搜索系统里的文档集合:
- 正排索引 更像“正文内容本身”或“按章节查看整本书”
- 倒排索引 更像“书后面的关键词索引”
读正文时,是从书到词;查关键词索引时,是从词到页码。
例如一本书里很多页都包含“算法”这个词:
1
2
3
4
枕边的算法 ---- 2
用谜题解开算法世界 ---- 13
设计精妙算法 ---- 42
康威的末日算法 ---- 56
如果以“算法”作为 key,能够直接找到它出现过的页码或文档列表,这种从词到文档集合的结构就是倒排索引。
这一节最值得记住的结论
可以把正排和倒排压缩成下面三句话:
- 正排更适合“从文档看内容”
- 倒排更适合“从词找文档”
- Elasticsearch 做全文搜索快,核心就在于查询路径主要走倒排,而不是逐文档扫描
分词器是倒排索引的入口
写入文本字段时,Elasticsearch 会先经过分析过程,把文本拆成一个个 term,再写入倒排索引。分析器通常由三部分组成:
Character Filters:先做字符级预处理,例如去 HTML 标签。Tokenizer:按规则切分文本。Token Filters:对切出来的 term 再加工,例如转小写、去停用词。
常见内置分析器包括:
standard:通用默认分析器。simple:按非字母字符切分并转小写。whitespace:按空白字符切分。
中文场景里,IK 之类的中文分析器会更常见。
Term Dictionary、Posting List 和 FST
Lucene 在倒排索引内部会维护词典和倒排列表。可以粗略理解为:
Term Dictionary:保存所有 term。Posting List:保存每个 term 对应出现在哪些文档中。Term Index / FST:为了更快定位 term,Lucene 会对词典做额外的紧凑索引结构优化,常见实现会用到 FST。
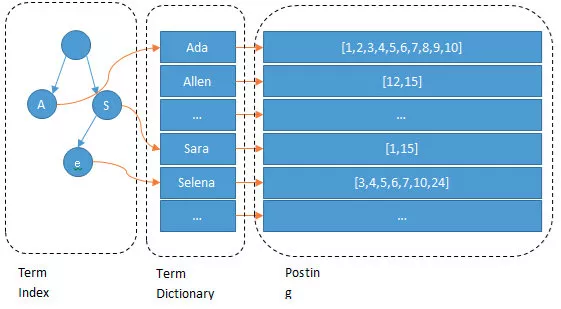
Posting List 不只是“有哪些文档 ID”,通常还会包含词频、位置、偏移量等信息,便于做相关性打分、短语查询、高亮等能力。
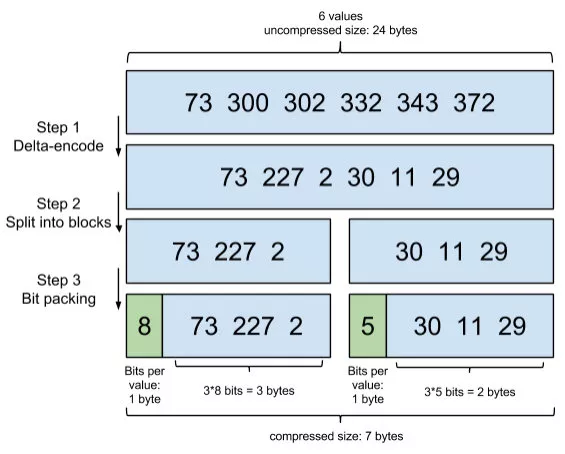
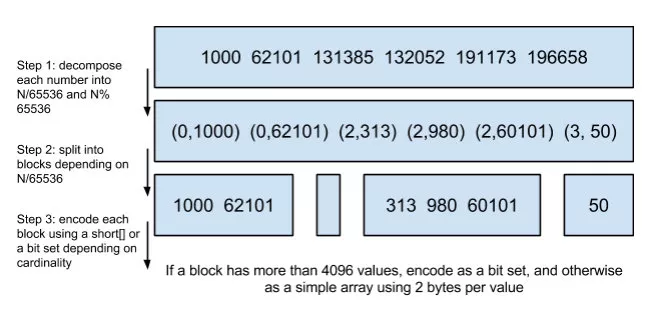
多个条件一起查询时,本质上还要对不同 term 对应的结果集做交并集、跳表遍历或位图计算,所以倒排结构除了快,还要尽量节省空间并支持高效合并。
Elasticsearch 的术语和架构
先说明一个边界:把 ES 和关系型数据库逐项类比,只能帮助入门,不是完全等价。
- Index: 一组相关文档的集合,常被类比为数据库里的表或集合。
- Document: 一条 JSON 文档。
- Field: 文档中的字段。
- Mapping: 字段类型、分析方式等索引结构定义。
- DSL: 查询表达方式,不完全等价于 SQL,但可以类比成 ES 的查询语言。
- Type: 历史概念。7.x 之后逐步退出,8.x 已不再支持 mapping types。
| RDBMS | Elasticsearch |
|---|---|
| Table / Collection 的近似类比 | Index |
| Row | Document |
| Column | Field |
| Schema | Mapping |
| SQL | Query DSL |
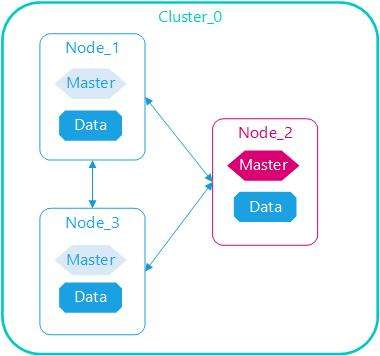
一个 Elasticsearch 集群由多个节点组成。节点可以承担不同角色,例如:
data node:负责存储分片和执行数据相关操作。coordinating node:负责接收请求、路由请求、汇总结果。cluster-manager node:负责维护集群元数据和分片分配。旧资料里常写作master node,现代文档已经改称cluster-manager node。
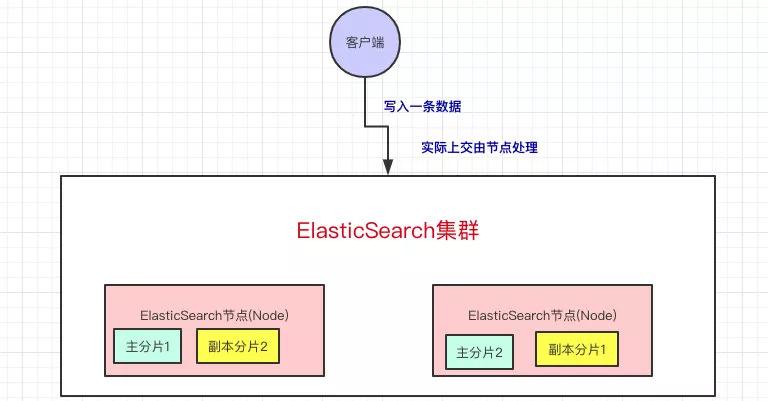
分片和副本
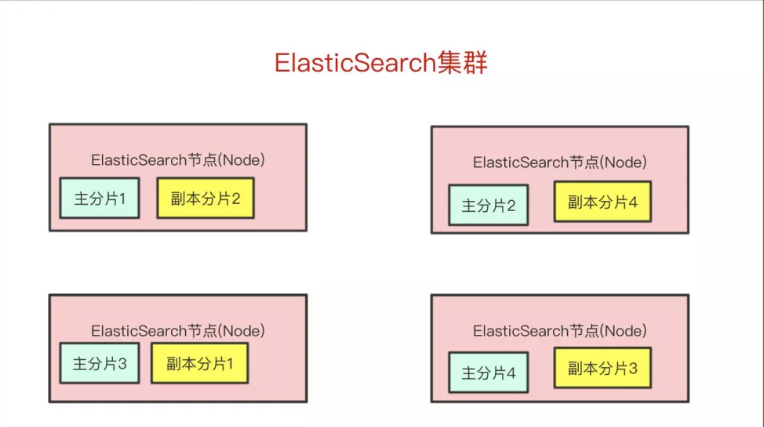
一个 index 会被拆成多个主分片 primary shard。这样做的目的主要有两个:
- 单个分片放不下全部数据时,可以横向拆分存储。
- 查询和写入可以并行落到多个分片上,提高吞吐。
副本分片 replica shard 则用于高可用和读扩展:
- 写入先落到主分片,再复制到副本分片。
- 查询既可以打到主分片,也可以打到副本分片。
- 当主分片所在节点故障时,副本分片可以被提升为新的主分片。
问题一:分片和水平扩展怎么理解
可以把分片理解成“先把一个大索引拆成多个逻辑块,再把这些块分布到不同节点上”。
例如一个 index 有 3 个主分片,总数据量约 30GB,那么可以粗略理解为每个主分片承载约 10GB 数据。最开始如果只有 1 个节点,3 个分片都可能落在同一台机器;后续增加节点后,分片就能重新均衡到更多机器上。
单分片大小没有绝对标准,很多经验文章会给出 10GB 到 50GB 的建议范围,但真正是否合适还要结合查询模式、恢复时间、硬件和总分片数一起看。
问题二:为什么通常建议至少留一半内存给文件系统缓存
Elasticsearch 非常依赖操作系统的文件系统缓存来加速 Lucene 索引文件访问,所以常见经验是:
Xms和Xmx设置成不超过节点可用内存的 50%。- 剩余内存尽量留给操作系统做 filesystem cache。
这个“50%”更适合理解成安全上限和经验值,而不是机械地“必须精确预留一半”。现代 ES 也会按节点角色自动设置堆大小。
另外,堆并不是越大越好。过大的堆会带来更重的 GC 压力,还可能跨过 compressed oops 的阈值。保守做法通常会把堆控制在 26GB 左右,具体上限要以实际 JVM 日志和版本为准。
问题三:结合内存看搜索流程
可以把搜索请求粗略理解为下面的链路:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
用户发起搜索
↓
协调节点接收请求
↓
请求被分发到目标分片
↓
每个分片在本地执行查询:
1. 读取 Lucene 倒排索引、doc values 等结构
2. 尽量命中文件系统缓存(page cache)
3. 未命中时再从磁盘读取
↓
各分片返回局部结果
↓
协调节点合并、排序、分页
↓
返回最终结果
并不是每次查询都会先去检查某种“JVM 堆里的字段缓存”。现代 ES 的查询性能更常依赖 mapping 设计、doc values、query cache / request cache 是否命中,以及操作系统缓存是否足够稳定。
Elasticsearch 写入的流程
写入请求进入集群后,任何一个能够接收请求的节点都可以先充当协调节点,再把请求路由到目标主分片。
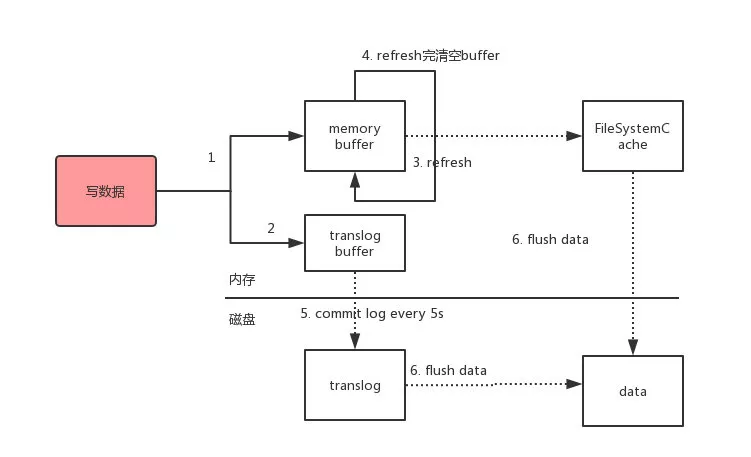
如果没有指定自定义 routing,路由通常会根据文档 _id 和主分片数量计算,核心目的就是确定“这条文档应该落到哪个主分片”。
常见写入链路可以概括为:
- 协调节点接收请求并定位目标主分片。
- 主分片先执行写入,再把操作复制到副本分片。
- 写入会进入 Lucene 的内存缓冲区,同时追加到
translog。 refresh发生后,新的 segment 对搜索可见,因此文档可以被普通搜索命中。flush会把 Lucene 提交点推进,并开启新的 translog generation,主要目标是持久化与恢复控制,而不是“让文档可搜索”。
这里最容易混淆的是 refresh、translog 和 flush:
refresh解决的是可搜索性,不是最终持久化。translog解决的是崩溃恢复和写入确认。flush解决的是Lucene commit 与 translog 截断,通常由系统按启发式条件自动触发,不是固定每 5 秒一次。
在现代版本里,index.translog.durability 默认是 request。这意味着一个写请求在返回成功前,主分片和已分配副本分片上的 translog 都已经完成 fsync 并提交。因此,不能简单地把 ES 概括成“节点宕机会丢 5 秒数据”。
不过,普通搜索仍然通常要等到下一次 refresh 才能看到新文档,所以 ES 经常被描述为 near real-time search。

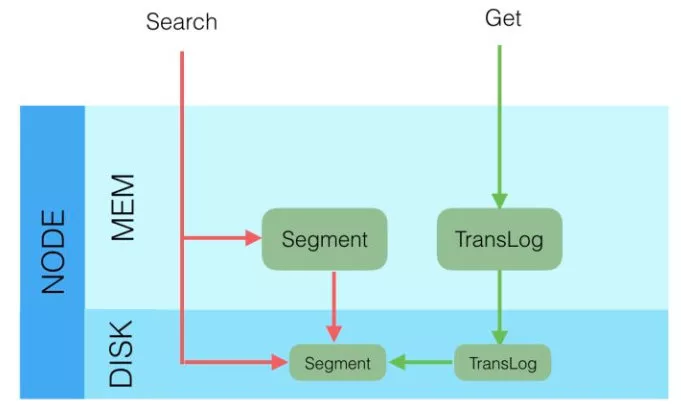
Elasticsearch 更新和删除
从 Lucene 的段文件视角看,更新和删除都不是“原地改写”旧文档,而更像:
- 删除:先把文档标记为已删除。
- 更新:本质上等于“旧文档标记删除 + 新文档重新写入”。
随着时间推移,segment 会越来越多,后台会通过 merge 任务把多个 segment 合并。在 merge 过程中,已经被删除的文档才会真正从新的段文件里消失。

Elasticsearch 查询
查询可以先分成两类来看:
- GET by ID: 更偏实时读取。
- Search by Query: 更偏近实时搜索。
1
2
public TopDocs search(Query query, int n);
public Document doc(int docID);
之所以说 GET 更实时,是因为它不必严格等待搜索刷新;而普通搜索依赖当前可见的 searcher 视图,所以通常要等下一次 refresh。
分布式搜索的两个常见 search type
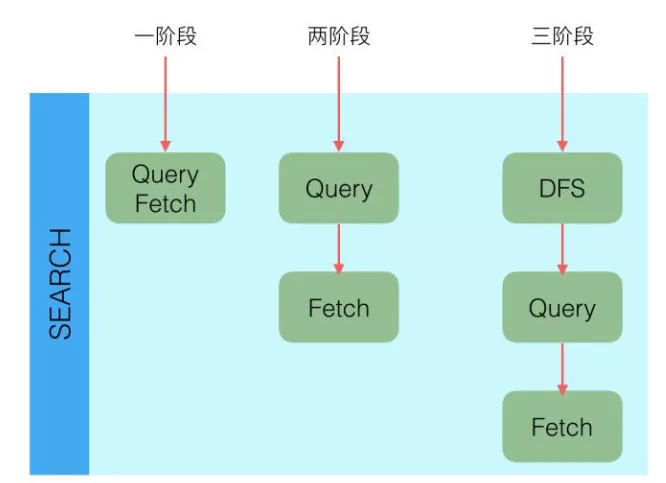
现代版本常见的是这两个:
query_then_fetch:默认方式。先在各分片本地算分并返回候选结果,再统一抓取文档内容。dfs_query_then_fetch:先额外收集全局词频信息,再做查询和抓取,算分更一致,但开销更大。
旧资料里常见的 QUERY_AND_FETCH 已经不再是现代 ES 里常用的搜索类型,不适合继续当作主流机制理解。
query_then_fetch 的整体流程
- 客户端把请求发给某个节点。
- 协调节点把查询转发到相关分片。
- 每个分片先返回局部 Top N 结果和打分信息。
- 协调节点做全局排序、分页,确定最终需要抓取的文档。
- 协调节点再去对应分片拉取
_source或其他字段,组装最终返回值。

现代版本快速上手
如果只是想先建立现代 Elasticsearch 的基本使用直觉,下面这组 REST 示例比旧版 Java API 更值得优先看。
创建索引和 mapping
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
PUT /books
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "standard"
},
"author": {
"type": "keyword"
},
"price": {
"type": "double"
},
"publish_time": {
"type": "date"
}
}
}
}
这里没有 type。在现代 Elasticsearch 里,mapping 直接从 properties 开始定义。
写入文档
1
2
3
4
5
6
7
POST /books/_doc/1
{
"title": "Elasticsearch 实战",
"author": "ekko",
"price": 88.0,
"publish_time": "2026-06-10"
}
搜索文档
1
2
3
4
5
6
7
8
9
10
11
12
13
GET /books/_search
{
"query": {
"match": {
"title": "elasticsearch"
}
},
"sort": [
{
"_score": "desc"
}
]
}
过滤与聚合
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
GET /books/_search
{
"size": 0,
"query": {
"range": {
"price": {
"gte": 50,
"lte": 100
}
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
一张总表先建立直觉
如果只想先抓住这篇文章里最重要的一条主线,可以先看下面这张表。它把字段类型、常用查询和典型场景放在了一起,后面的各节基本都在围绕这张表展开。
| 字段类型 | 常用查询 DSL | 常见场景 |
|---|---|---|
text |
match、match_phrase、multi_match |
文章标题、正文、商品名称、描述信息 |
keyword |
term、terms、bool.filter |
状态、标签、ID、编码、枚举值 |
date |
range、sort |
创建时间、更新时间、时间范围筛选 |
integer / long / double |
range、term、聚合 |
金额、计数、分值、区间统计 |
boolean |
term、bool.filter |
删除标记、启用状态、开关字段 |
text + keyword 多字段 |
全文查询 + 精确过滤 / 排序 / 聚合 | 既要搜内容,又要排序或聚合的标题类字段 |
可以先把它理解成三条最重要的规则:
- 要搜内容,先看字段是不是
text - 要做精确过滤、排序、聚合,先看字段是不是
keyword或原生结构化类型 - 如果一个字段既要搜内容又要做排序聚合,优先考虑
text + keyword
text vs keyword、mapping 设计与常见查询误区
真正开始用 Elasticsearch 时,最容易踩坑的往往不是分片和集群,而是字段类型和查询方式没有配套。很多“为什么搜不到”“为什么聚合报错”“为什么排序结果不对”的问题,最后都能追到 mapping 设计上。
text 和 keyword 到底有什么区别
最核心的区别可以概括成一句话:
text用来做全文检索,会先分析再建立倒排索引。keyword用来做精确匹配、过滤、排序和聚合,通常不会分词。
例如下面这个字段定义:
1
2
3
4
5
6
"title": {
"type": "text"
},
"status": {
"type": "keyword"
}
如果文档里有:
1
2
3
4
{
"title": "Elasticsearch 实战入门",
"status": "published"
}
那么:
title适合用match、match_phrase之类全文查询。status适合用term、terms、聚合和排序。
这也是为什么很多人第一次用 term query 查 text 字段会发现结果“不对劲”。因为 text 字段写入时已经被分析过,索引里的 term 往往不是原始字符串了。
最常见的设计方式:multi-fields
很多业务字段既想支持全文搜索,又想支持精确过滤或排序,这时更常见的做法不是二选一,而是使用多字段:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
PUT /articles
{
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
这样一来:
title用于全文检索。title.keyword用于精确过滤、排序和聚合。
例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
GET /articles/_search
{
"query": {
"match": {
"title": "elasticsearch"
}
},
"sort": [
{
"title.keyword": "asc"
}
],
"aggs": {
"by_title": {
"terms": {
"field": "title.keyword"
}
}
}
}
mapping 设计时优先想清楚什么
一个字段在建 mapping 之前,最好先回答这几个问题:
- 这个字段是拿来“搜内容”还是“做过滤”?
- 这个字段需不需要排序?
- 这个字段需不需要聚合?
- 这个字段是否需要保留原值做精确匹配?
- 这个字段有没有明显的取值边界,例如日期、数字、布尔值、枚举值?
如果这些问题没先想清楚,常见结果就是:
- 明明是状态字段,却建成了
text - 明明是金额、时间,却先当字符串存进去
- 明明只是筛选条件,却用了全文查询
- 明明需要排序和聚合,却没有提供
keyword子字段
一个更接近真实业务的 mapping 例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
PUT /orders
{
"mappings": {
"properties": {
"order_id": {
"type": "keyword"
},
"user_id": {
"type": "keyword"
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"status": {
"type": "keyword"
},
"amount": {
"type": "double"
},
"created_at": {
"type": "date"
},
"is_deleted": {
"type": "boolean"
}
}
}
}
这里的思路是:
order_id、user_id、status这类标识和枚举值,用keywordtitle这类要搜内容的字段,用text,并额外补一个keyword子字段amount用数值类型,便于范围过滤和统计created_at用日期类型,便于时间范围查询is_deleted用布尔类型,避免把逻辑状态写成字符串
常见查询误区一:term 查 text
这是最常见的误区之一。
错误思路:
1
2
3
4
5
6
7
8
GET /articles/_search
{
"query": {
"term": {
"title": "Elasticsearch 实战"
}
}
}
如果 title 是 text 字段,这个查询往往不会按“整句原样匹配”工作。
更合适的思路通常是:
- 查全文内容,用
match - 查精确值,用
term/terms - 如果字段是
text + keyword,要精确匹配就查title.keyword
例如:
1
2
3
4
5
6
7
8
GET /articles/_search
{
"query": {
"term": {
"title.keyword": "Elasticsearch 实战"
}
}
}
常见查询误区二:在 text 字段上直接排序或聚合
很多人第一次写这种请求时会报错:
1
2
3
4
5
6
7
8
GET /articles/_search
{
"sort": [
{
"title": "asc"
}
]
}
原因通常不是“ES 不支持排序”,而是 text 字段默认不适合直接拿来排序和聚合。更常见的做法是:
- 排序用
title.keyword terms aggregation也用title.keyword
如果为了让 text 支持聚合而强行打开 fielddata,往往会带来额外内存开销,不适合作为默认方案。多数业务场景下,直接设计 keyword 子字段更稳妥。
常见查询误区三:把过滤条件写成全文查询
例如 status = published、user_id = 1001、order_id = A001 这类条件,本质是精确过滤,更适合 term 查询或放到 bool.filter 中,而不是写成 match。
更合理的写法通常像这样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
GET /orders/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "退款"
}
}
],
"filter": [
{
"term": {
"status": "paid"
}
},
{
"range": {
"created_at": {
"gte": "2026-01-01",
"lt": "2027-01-01"
}
}
}
]
}
}
}
这里可以把思路简单记成:
must更适合参与相关性评分的全文条件filter更适合不需要评分的精确筛选条件
常见查询误区四:让动态 mapping 决定一切
动态 mapping 很方便,但它更适合快速试验,不适合长期依赖。因为一旦字段类型被自动推断错了,后面通常不能直接原地修改,只能重建索引再迁移数据。
因此更稳妥的做法通常是:
- 核心索引提前写好 mapping
- 对标识、状态、时间、金额这类关键字段明确指定类型
- 中文检索场景提前确定分析器
- 在上线前用真实数据做一轮查询、排序和聚合验证
一个实用判断方法
如果一个字段满足下面任意一种情况,优先考虑 keyword:
- 需要精确匹配
- 需要排序
- 需要聚合
- 本身就是 ID、状态、标签、枚举值
如果一个字段主要用于“按内容搜索”,优先考虑 text:
- 需要分词
- 需要相关性评分
- 需要支持全文检索或短语检索
如果两者都要,就优先考虑 text + keyword 多字段设计。
match、term、range、bool 该怎么选
把查询 DSL 看复杂了,往往是因为同时在记“语法”和“场景”。如果先按用途拆开,这四类查询其实可以收拢成一套很实用的判断逻辑:
- 要搜“文本内容”,优先想
match - 要做“精确匹配”,优先想
term - 要做“区间筛选”,优先想
range - 要把多个条件组合起来,优先想
bool
先记一条主线
可以先把这几个查询和字段类型对应起来:
| 查询类型 | 更常配合的字段 | 典型用途 |
|---|---|---|
match |
text |
全文检索 |
term / terms |
keyword、boolean、部分精确值字段 |
精确过滤 |
range |
date、long、double 等 |
时间区间、数值区间 |
bool |
组合查询 | 把全文条件和过滤条件拼起来 |
如果只记一句话,可以记成:字段类型先决定大方向,查询 DSL 再去匹配字段语义。
match:适合全文检索
match 更适合查“内容里有没有这个意思”,而不是“字段值是否严格等于某个字符串”。
例如:
1
2
3
4
5
6
7
8
GET /articles/_search
{
"query": {
"match": {
"title": "elasticsearch 入门"
}
}
}
这个查询适合 title 这种 text 字段,因为它会结合分析器对查询词做处理,再去倒排索引里找相关文档。
更适合 match 的场景包括:
- 文章标题搜索
- 商品名称搜索
- 正文内容搜索
- 用户输入一句自然语言去查相关内容
不太适合 match 的场景包括:
status = paiduser_id = 1001order_id = A20260610
这类条件不是“搜内容”,而是“查精确值”。
term:适合精确匹配
term 的重点不是“搜索”,而是“字段里就等于这个值”。
例如:
1
2
3
4
5
6
7
8
GET /orders/_search
{
"query": {
"term": {
"status": "paid"
}
}
}
它通常更适合这些字段:
keywordboolean- 不需要分析的标识字段
常见场景包括:
- 状态筛选
- 用户 ID、订单 ID、分类编码筛选
- 标签、枚举值过滤
如果要一次匹配多个候选值,通常就从 term 切到 terms:
1
2
3
4
5
6
7
8
GET /orders/_search
{
"query": {
"terms": {
"status": ["paid", "shipped"]
}
}
}
range:适合时间和数值区间
只要需求里出现“大于、小于、介于之间、最近 7 天、价格区间”这类词,第一反应通常就应该是 range。
例如:
1
2
3
4
5
6
7
8
9
10
11
GET /orders/_search
{
"query": {
"range": {
"amount": {
"gte": 100,
"lt": 500
}
}
}
}
或者:
1
2
3
4
5
6
7
8
9
10
11
GET /orders/_search
{
"query": {
"range": {
"created_at": {
"gte": "2026-01-01",
"lt": "2027-01-01"
}
}
}
}
它通常适合:
dateinteger/longfloat/double
如果字段本来是字符串,却想拿来做区间判断,往往说明 mapping 一开始就设计错了。
bool:适合把多个条件拼起来
实际业务里很少只写一个条件。更常见的情况是:
- 既要按标题搜关键词
- 又要过滤状态
- 还要限制时间范围
这时最常见的入口就是 bool。
例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
GET /orders/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "退款"
}
}
],
"filter": [
{
"term": {
"status": "paid"
}
},
{
"range": {
"created_at": {
"gte": "2026-01-01",
"lt": "2027-01-01"
}
}
}
]
}
}
}
可以把 bool 看成一个“查询容器”,常用子句大致这样理解:
must:必须满足,通常用于全文检索或需要参与评分的条件filter:必须满足,但不参与评分,适合精确过滤should:可选匹配,适合提升相关性或表达“满足其一更好”must_not:必须不满足
入门阶段最常用、也最稳的组合通常是:must + filter。
一个简单的决策表
如果需求是下面这些,可以直接这样选:
| 需求描述 | 优先查询 |
|---|---|
| 搜文章标题里和“elasticsearch”相关的内容 | match |
查状态等于 paid 的订单 |
term |
查状态属于 paid、shipped 的订单 |
terms |
| 查金额在 100 到 500 之间的订单 | range |
| 查 2026 年创建的订单 | range |
查标题里有“退款”,且状态是 paid |
bool + match + term |
查标题里有“退款”,且状态是 paid,且时间在一年内 |
bool + match + term + range |
一个更顺手的判断顺序
写查询时,如果不想一上来就在 DSL 上打结,可以按这个顺序想:
- 这是搜文本内容,还是筛选精确值?
- 如果是搜文本内容,用
match - 如果是精确值过滤,用
term/terms - 如果是时间或数值边界,用
range - 如果条件不止一个,用
bool把它们拼起来
新手最容易混淆的两组关系
第一组是 match 和 term:
match更像“查相关内容”term更像“查这个值本身”
第二组是 must 和 filter:
must更适合全文条件filter更适合状态、ID、时间、金额这类筛选条件
如果把 status = paid 这种条件写进 must.match,通常也不是完全不能跑,但表达上不够准确,查询语义也不如 filter.term 清晰。
入门阶段最推荐的写法
对于大多数后台检索场景,一个很稳的起手式是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
GET /your_index/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "关键词"
}
}
],
"filter": [
{
"term": {
"status": "online"
}
},
{
"range": {
"created_at": {
"gte": "2026-01-01"
}
}
}
]
}
}
}
这套组合之所以常见,是因为它同时兼顾了:
- 全文搜索
- 精确过滤
- 区间筛选
- 查询结构清晰
match_phrase、multi_match、must / should / must_not 的区别
前面那一节解决的是“基础查询该怎么选”,这一节继续回答“全文查询再往前走一步该怎么选”。很多时候并不是不会写 DSL,而是不确定自己要的到底是:
- 只要相关就行
- 必须按短语顺序出现
- 需要跨多个字段一起搜
- 需要一个条件必须满足,另一些条件满足越多越好
match 和 match_phrase 的区别
可以先把这两个查询理解成:
match:只要分词后能匹配到相关内容即可,更偏“相关性搜索”match_phrase:更强调词项顺序和相邻关系,更偏“短语匹配”
例如字段 title 是:
1
Elasticsearch 入门实战
用 match:
1
2
3
4
5
6
7
8
GET /articles/_search
{
"query": {
"match": {
"title": "elasticsearch 实战"
}
}
}
它关注的是分词后的相关性,词之间不一定要严格连续。
而 match_phrase:
1
2
3
4
5
6
7
8
GET /articles/_search
{
"query": {
"match_phrase": {
"title": "elasticsearch 实战"
}
}
}
它更强调“这些词按接近原顺序出现”。因此:
- 搜文章标题、商品名称里的固定短语时,
match_phrase更常见 - 做普通全文搜索、希望召回更宽一些时,
match更常见
如果希望短语里允许少量间隔,还可以用 slop:
1
2
3
4
5
6
7
8
9
10
11
GET /articles/_search
{
"query": {
"match_phrase": {
"title": {
"query": "elasticsearch 实战",
"slop": 1
}
}
}
}
入门阶段可以先这样判断:
- 想查“相关内容”,优先
match - 想查“这几个词基本连在一起出现”,优先
match_phrase
multi_match:适合跨多个字段一起搜
如果查询条件要同时在多个字段上搜索,最直接的入口通常就是 multi_match。
例如一篇文章既希望按标题搜,也希望按摘要搜:
1
2
3
4
5
6
7
8
9
GET /articles/_search
{
"query": {
"multi_match": {
"query": "elasticsearch 入门",
"fields": ["title", "summary"]
}
}
}
它的价值在于,不需要手动拼多个 match,就可以把“同一个搜索词”同时打到多个文本字段上。
最常见的场景包括:
- 同时搜标题和正文摘要
- 同时搜商品名、品牌文案、类目描述
- 同时搜姓名、昵称、简介等多个用户资料字段
如果只是单字段搜索,优先还是直接用 match;只有在“一个查询词要打多个字段”时,再切到 multi_match。
must、should、must_not 分别表达什么
bool 的几个子句里,最容易混的是这三个:
must:必须满足should:可选满足,通常用来提升相关性,或者表达“满足其一即可”must_not:必须不满足
先看一个例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
GET /articles/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "elasticsearch"
}
}
],
"should": [
{
"match": {
"summary": "lucene"
}
}
],
"must_not": [
{
"term": {
"status": "deleted"
}
}
]
}
}
}
这个查询可以理解成:
- 标题里必须和
elasticsearch相关 - 摘要里如果还能匹配到
lucene会更好,分数通常更高 - 但状态不能是
deleted
must 和 should 最容易混淆的地方
新手最常见的疑问是:为什么 should 有时像“可选”,有时又像“至少满足一个”?
可以先用一个简单规则理解:
- 如果
bool里已经有must或filter,那should通常更像“加分项” - 如果
bool里没有must/filter,只有一堆should,那它更像“这些条件至少命中一些”
例如下面这个查询:
1
2
3
4
5
6
7
8
9
10
11
12
GET /articles/_search
{
"query": {
"bool": {
"should": [
{ "match": { "title": "elasticsearch" } },
{ "match": { "summary": "elasticsearch" } }
],
"minimum_should_match": 1
}
}
}
它表达的是:标题或摘要至少要命中一个字段。
因此可以把 should 粗略分成两种用法:
- 加分型 should: 在已有
must/filter的前提下,让匹配更多条件的文档得分更高 - 候选型 should: 用
minimum_should_match表达“这些条件至少满足几个”
must_not 适合排除条件
凡是业务语义里出现:
- 不包含
- 不等于
- 排除某类数据
通常都可以往 must_not 上想。
例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
GET /orders/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"status": "paid"
}
}
],
"must_not": [
{
"term": {
"is_deleted": true
}
}
]
}
}
}
这个写法比把“排除逻辑”塞进业务代码里后处理更清晰。
一个实用决策表
下面这张表可以直接拿来做查询选型:
| 需求描述 | 更适合的查询 |
|---|---|
| 搜和“elasticsearch 入门”相关的标题 | match |
| 搜标题里基本连续出现“elasticsearch 入门”的内容 | match_phrase |
| 同时搜标题、摘要、正文前言 | multi_match |
| 某个条件必须满足 | must |
| 某个条件命中后更好,但不是硬性要求 | should |
| 需要排除某类数据 | must_not |
多个 should 条件里至少满足一个 |
should + minimum_should_match |
入门阶段一个很好用的组合
很多后台搜索需求,最后都会落到下面这种结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
GET /articles/_search
{
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "elasticsearch 入门",
"fields": ["title", "summary"]
}
}
],
"filter": [
{
"term": {
"status": "published"
}
}
],
"should": [
{
"match_phrase": {
"title": "elasticsearch 入门"
}
}
],
"must_not": [
{
"term": {
"is_deleted": true
}
}
]
}
}
}
这套写法的思路可以概括为:
- 用
must放主搜索条件 - 用
filter放精确筛选条件 - 用
should做结果加权 - 用
must_not排除脏数据或无效数据
中文检索里 IK 分词器、analyzer / search_analyzer 该怎么配
中文检索和英文检索最大的不同之一,在于“词边界”不是天然靠空格分开的,因此分词器配置会直接影响召回率和准确率。很多中文搜索效果不好,并不是 Elasticsearch 不行,而是:
- mapping 没提前设计
- 分词器没选对
- 索引期和搜索期分析方式没有分开
为什么中文检索需要单独关注分析器
对英文来说,standard analyzer 往往已经能覆盖很多基础场景;但中文如果继续沿用默认分析器,通常会得到很粗糙的分词结果,搜索体验也会明显变差。
中文场景里最常见的选择之一就是 IK 分词器,尤其是:
ik_max_wordik_smart
可以把它们先粗略理解为:
ik_max_word:切得更细,召回更宽ik_smart:切得更稳,词粒度更粗
ik_max_word 和 ik_smart 怎么选
一个很常见的经验组合是:
- 索引期: 用
ik_max_word - 搜索期: 用
ik_smart
原因在于:
- 索引期切得更细,有助于把更多可能的词项写进倒排索引,提升召回能力
- 搜索期切得稍微稳一些,可以减少过度拆词带来的噪声
这不是绝对规则,但对大多数中文站内搜索、文章搜索、商品搜索场景来说,是一个很常见的起点。
analyzer 和 search_analyzer 的区别
这两个字段非常容易混淆,但其实职责很清楚:
analyzer:索引期分析器,决定文档写入时如何分词search_analyzer:搜索期分析器,决定查询词如何分词
如果只配置了 analyzer,通常搜索期会沿用同一个分析器;而单独配置 search_analyzer,就是为了让“写入时怎么切”和“查询时怎么切”可以分开。
一个常见的中文字段配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
PUT /articles
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"status": {
"type": "keyword"
},
"publish_time": {
"type": "date"
}
}
}
}
这个配置背后的意图是:
title、content用中文全文检索方案- 索引时尽量多切一些词,提高召回
- 查询时适当收敛,避免查询词过度拆分
title.keyword保留排序和精确匹配能力
一个很容易踩坑的点
很多人第一次配中文检索时,会把所有字符串字段都配成 IK 分词器。这通常不是一个好主意。
例如下面这些字段,往往就不应该做中文分词:
user_idorder_idstatuscategory_codephone
这些字段本质上是标识、枚举值或结构化数据,更适合 keyword。如果错误地配成 text + IK,常见后果是:
- 精确过滤变得别扭
- 聚合和排序不好做
- 查询语义变得混乱
一个更贴近业务的中文搜索例子
假设有下面这条文档:
1
2
3
4
5
{
"title": "中华人民共和国国歌解读",
"content": "这是一篇关于中华人民共和国国歌背景的文章",
"status": "published"
}
如果 title 使用:
- 索引期
ik_max_word - 搜索期
ik_smart
那么用户输入“中华人民共和国国歌”时,通常既能保证召回,又不会像过度拆词那样把噪声放得太大。这也是中文搜索里为什么经常把索引期和搜索期分开配置。
查询时怎么写
只要 mapping 上已经配好了 analyzer / search_analyzer,多数情况下查询时直接用 match 或 multi_match 就够了,不需要每次手动指定分析器。
例如:
1
2
3
4
5
6
7
8
9
GET /articles/_search
{
"query": {
"multi_match": {
"query": "中华人民共和国国歌",
"fields": ["title", "content"]
}
}
}
只有在少数需要临时覆盖分析器的场景下,才会在查询侧显式指定 analyzer。
中文检索配置的入门建议
如果是站内中文搜索,入门阶段可以先按下面这套思路做:
- 中文正文类字段用
text - 索引期先试
ik_max_word - 搜索期先试
ik_smart - 需要排序、聚合、精确匹配的同名字段补一个
keyword子字段 - ID、状态、枚举值、编码类字段仍然坚持用
keyword
上线前最好做的验证
中文检索很依赖真实语料,因此上线前最好至少做下面几件事:
- 用真实业务词测试
_analyze结果 - 用真实搜索词测试召回数量和排序效果
- 检查短词、长词、同义词、品牌词是否被过度拆分
- 检查常用过滤字段是不是仍然保持
keyword
一个简单的 _analyze 示例:
1
2
3
4
5
POST /articles/_analyze
{
"analyzer": "ik_max_word",
"text": "中华人民共和国国歌"
}
这个接口非常适合在设计 mapping 之前先验证分词效果。
一句话总结这部分
中文搜索里,真正关键的不是“有没有装 IK”,而是:
- 哪些字段应该分词
- 索引期和搜索期是否需要分开
- 哪些字段必须保留
keyword
把这三件事想清楚,中文检索的效果通常就能先达到一个比较稳的起点。
现代 ES 入门学习路径与上线前检查清单
把 Elasticsearch 学到能稳定落地,通常不需要一开始就追求“全会”,而是先把一条最短闭环走通。更实用的顺序通常是:先理解索引和查询,再理解字段设计,最后再处理分词、性能和运维问题。
一条够用的学习路径
可以把现代 Elasticsearch 的入门路径拆成下面五步:
- 先理解数据模型: 搞清楚
index、document、field、mapping、分片、副本分别是什么。 - 再理解字段设计: 先把
text、keyword、date、数值类型、布尔类型分清楚。 - 再掌握基础查询: 至少熟悉
match、term、range、bool这几类最常用查询。 - 再处理全文搜索细节: 根据业务决定是否需要
match_phrase、multi_match、中文分词器、search_analyzer。 - 最后再进入上线细节: 包括 mapping 固化、真实语料验证、分片规划、排序聚合验证和监控告警。
如果是业务开发视角,真正最值得优先掌握的是下面这一组能力:
- 能把字段类型设计对
- 能把全文条件和过滤条件拆对
- 能写出结构清晰的
bool查询 - 能判断中文字段是否该用 IK
- 能在上线前用真实搜索词验证效果
一个更贴近实战的学习顺序
如果想把这篇笔记当成实际落地的路线图,可以按下面顺序回看:
- 看“什么是 Elasticsearch”和“术语和架构”,建立整体概念。
- 看“写入流程”和“查询流程”,理解近实时搜索和分布式查询是怎么来的。
- 看
text/keyword和 mapping 设计,把字段建模问题想清楚。 - 看
match/term/range/bool,学会最基础的一组 DSL。 - 看
match_phrase/multi_match/should/must_not,补足搜索表达能力。 - 看中文检索和 IK 分词器配置,把中文业务里最常见的坑提前避开。
这条路线的核心在于:先把查询语义和字段语义对齐,再追求更多高级能力。
上线前检查清单
如果准备把一个现代 ES 索引正式用于业务,至少值得检查下面这些点:
- 字段类型:
ID、状态、标签、编码是否都还是keyword,没有误建成text - 全文字段: 需要全文检索的字段是否明确使用了
text - 多字段设计: 既要搜内容又要排序/聚合的字段,是否补了
keyword子字段 - 日期与数值: 时间、金额、计数类字段是否使用了正确的原生类型
- 查询结构: 全文条件是否放在
must,过滤条件是否尽量放在filter - 排序与聚合: 是否仍有直接对
text字段排序或聚合的风险 - 中文检索: 中文字段是否明确配置了合适的
analyzer/search_analyzer - 真实语料验证: 是否用真实搜索词测试过召回、排序和误召回情况
- 分片规划: 主分片数量是否结合数据量和扩容预期做过基本规划
- 版本边界: 是否还残留
type、TransportClient等旧版本设计
一组最值得优先验证的接口
在真正上线之前,下面这几类接口通常最值得先跑通:
- 建索引与 mapping
- 单条写入和批量写入
- 典型
bool查询 - 常用过滤条件和时间范围查询
- 聚合与排序
_analyze验证分词效果
如果这些都已经能结合真实数据稳定工作,说明这个索引已经具备进入业务使用的基础条件。
旧版附录:ES 2.x Java API 速览
前面的正文已经尽量统一到现代 Elasticsearch 的概念和写法。这里保留一个简短附录,只是为了说明老项目里常见的 ES 2.x Java API 长什么样,以及它和现代 Elasticsearch 最大的差异在哪里。
这部分内容为什么不再放在正文展开
早期 Elasticsearch Java 示例普遍建立在下面这些前提上:
- 使用
TransportClient - API 中大量出现
type - 部分能力依赖旧插件或旧脚本配置
- 与 7.x、8.x 的接口模型差异明显
如果把这些内容继续和现代 Elasticsearch 混在一起讲,最容易造成两个问题:
- 初学者会误以为
TransportClient仍然是主流写法 - 会把
type、旧版插件机制、旧版删除接口误带进新项目
因此更合适的做法是:正文讲现代 ES,旧版接口只保留为历史附录。
ES 2.x 和现代 Elasticsearch 的核心差异
可以把最关键的差异先收成这张表:
| 主题 | ES 2.x 常见写法 | 现代 Elasticsearch |
|---|---|---|
| Java 客户端 | TransportClient |
官方 REST / Java API Client |
| 文档类型 | 强依赖 type |
不再使用 type |
| 删除按条件 | 旧插件或旧接口 | 现代 _delete_by_query |
| 建模方式 | 常见多 type 思路 |
直接围绕 index + properties 建模 |
| 教程重点 | 客户端调用细节 | mapping、查询 DSL、分词和数据建模 |
如果你维护的是老项目,最值得关注什么
如果当前项目仍然停留在 ES 2.x 或其附近版本,最值得优先确认的不是“能不能继续跑”,而是下面这些问题:
- 是否还依赖
TransportClient - 是否大量依赖
type - 是否有旧版
delete-by-query插件依赖 - 是否存在只能跑在旧集群上的脚本配置
- 是否已经有迁移到 REST API 或新客户端的计划
一个典型的 ES 2.x Java 写法
下面这段代码只是为了帮助识别历史风格,不建议在现代项目里继续照搬:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Client client = TransportClient.builder().build()
.addTransportAddress(
new InetSocketTransportAddress(
InetAddress.getByName("127.0.0.1"),
9300
)
);
IndexResponse response = client.prepareIndex("twitter", "tweet", "1")
.setSource(jsonBuilder()
.startObject()
.field("user", "kimchy")
.field("message", "trying out Elasticsearch")
.endObject())
.get();
这段代码里最明显的历史痕迹有两个:
TransportClientprepareIndex(index, type, id)里的type
只要在新文章、新项目或新索引设计里看到类似模式,就应该先警惕是不是把旧版本写法带进来了。
如何看待旧版示例的学习价值
这些旧版代码并不是完全没有价值,它们仍然可以帮助理解一些长期稳定存在的概念,例如:
- 文档写入、更新、删除、批量操作的基本意图
- 查询 DSL 的大体结构
- 聚合、分词、分析器这些能力在老版本里也已经存在
真正过时的主要是客户端入口、类型模型和部分接口细节,而不是 Elasticsearch 作为搜索引擎的核心思想本身。
旧版附录的使用方式
如果只是现代 ES 入门,到这里就可以收住,不需要继续往旧版 API 深挖。
如果后续确实要处理老项目,可以再单独整理一篇:
TransportClient历史接口梳理- ES 2.x 到 7.x / 8.x 的迁移差异
type移除的影响- 老索引重建与数据迁移方案
这样拆开后,正文会更聚焦,旧版兼容问题也更容易独立维护。