聊聊 Elasticsearch 的倒排索引、「扫盲」 Elasticsearch、Elasticsearch就是这么简单
ElasticSearch Java Api(一) 这篇文章的博主关于 ElasticSearch 的内容很多,这里就不一一列举参考文章标题了
[TOC]
什么是Elasticsearch
ElasticSearch 是一个基于 Lucene 的实时的分布式存储、搜索和分析引擎。设计用于云计算中能够达到实时搜索,稳定可靠,快速,安装使用方便。基于 RESTFUL 接口
ES 使用了倒排索引( inverted index ),该结构对于全文检索非常快
倒排索引包括一个在任意文档中出现的唯一性的词语列表,对于每个词语,都有一个它出现过的文档列表
为什么要用Elasticsearch
在日常开发中,数据库也能做到(实时、存储、搜索、分析)
相对于数据库,Elasticsearch的强大之处就是可以模糊查询
类似数据库的模糊查询 name like %zx% 是不走索引的,意味着数据库针对模糊查询较慢
而且,即便从数据库根据模糊匹配查出相应的记录了,那往往会返回大量的数据给你,往往需要的数据量并没有这么多,可能 50 条记录就足够了
还有一个就是:用户输入的内容往往并没有这么的精确,比如从Google 输入 ElastcSeach(打错字),但是 Google 还是能估算用户想输入的是 Elasticsearch
而 Elasticsearch 是专门做搜索的,就是为了解决上面所讲的问题而生的,换句话说:
- Elasticsearch 对模糊搜索非常擅长(搜索速度很快)
- 从 Elasticsearch 搜索到的数据可以根据评分过滤掉大部分的,只要返回评分高的给用户就好了(原生就支持排序)
- 没有那么准确的关键字也能搜出相关的结果(能匹配有相关性的记录)
Elasticsearch的数据结构
- 树型的查找时间复杂度一般是 O(logn)
- 链表的查找时间复杂度一般是 O(n)
- 哈希表的查找时间复杂度一般是 O(1)
每种数据库都有自己要解决的问题(或者说擅长的领域),对应的就有自己的数据结构,而不同的使用场景和数据结构,需要用不同的索引,才能起到最大化加快查询的目的
对 Mysql 来说,是 B+ 树,对 Elasticsearch/Lucene 来说,是倒排索引
Elasticsearch 是建立在全文搜索引擎库 Lucene 基础上的搜索引擎,它隐藏了 Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API,不过掩盖不了它底层也是 Lucene 的事实
Elasticsearch 的倒排索引,其实就是 Lucene 的倒排索引
不同的数据结构所花的时间往往不一样,想要查找的时候要快,就需要有底层的数据结构支持
根据 完整的条件 查找一条记录叫做正向索引;比如一本书的章节目录就是正向索引,通过章节名称就找到对应的页码
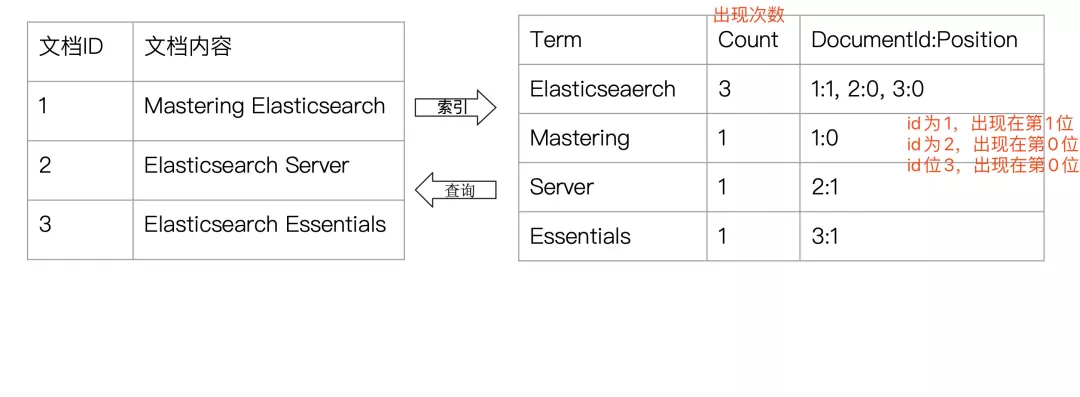
首先需要知道为什么 Elasticsearch 为什么可以实现快速的 模糊匹配/相关性查询 ,实际上是写入数据到 Elasticsearch 的时候会进行分词
比如某一本书的章节目录,有 4 条记录对应的页码都包括了 “算法” 这个词
1
2
3
4
5
6
7
8
9
10
枕边的算法 ---- 2
....
....
用谜题解开算法世界 ---- 13
....
....
设计精妙算法 ---- 42
....
....
康威的末日算法 ----56
代表 “算法” 这个词肯定在第2、13、42、56页出现过
这种根据 某个词(不完整条件) 再查找对应记录,叫做 倒排索引
在没有搜索引擎时,我们是直接输入一个网址,然后获取网站内容,这时我们的行为是:
document > to > words
通过文章,获取里面的单词,此谓正向索引:forward index
后来,我们希望能够输入一个单词,找到含有这个单词,或者和这个单词有关系的文章
word > to > documents
把这种索引称为 inverted index 反向索引,国内翻译成倒排索引
Elasticsearch 内置了一些分词器切分这些词
- Standard Analyzer:按词切分,将词小写
- Simple Analyzer:按非字母过滤(符号被过滤掉),将词小写
- WhitespaceAnalyzer:按照空格切分,不转小写
- … 等等
Elasticsearch 分词器主要由三部分组成:
- Character Filters(文本过滤器,去除 HTML)
- Tokenizer(按照规则切分,比如空格)
- TokenFilter(将切分后的词进行处理,比如转成小写)
中文分词器用得最多的就是 IK
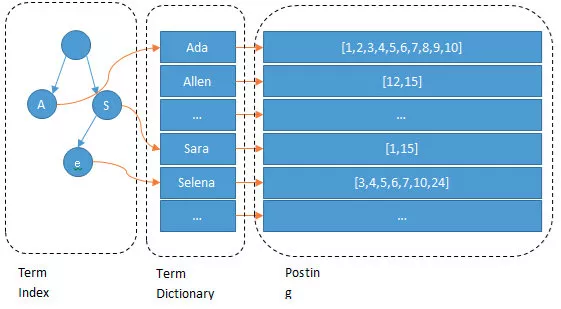
输入一段文字,Elasticsearch 会根据分词器对文字进行分词(也就是图上所看到的 Ada/Allen/Sara.. )
这些分词汇总起来叫做 Term Dictionary ,需要通过分词找到对应的记录,这些文档 ID 保存在 PostingList
在 Term Dictionary 中的词由于是非常非常多的,所以会为其进行排序,等要查找的时候就可以通过二分来查,不需要遍历整个 Term Dictionary
由于 Term Dictionary 的词实在太多了,不可能把 Term Dictionary 所有的词都放在内存中,于是 Elasticsearch 还抽了一层叫做 Term Index ,这层只存储 部分词的前缀 ,Term Index 会存在内存中(检索会特别快)
Term Index 在内存中是以 FST(Finite State Transducers)的形式保存的,其特点是节省内存。FST有两个优点:
- 空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间
- 查询速度快。O(len(str)) 的查询时间复杂度
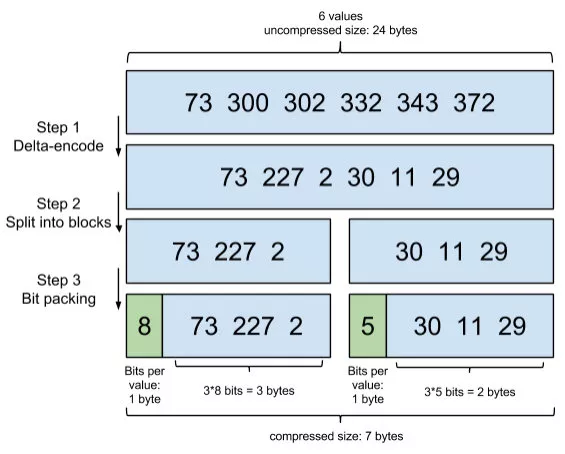
前面提到 Term Index 是存储在内存中的,且 Elasticsearch 用 FST(Finite State Transducers)的形式保存(节省内存空间)。Term Dictionary 在 Elasticsearch 也是为他进行排序(查找的时候方便),其实 PostingList 也有对应的优化。
PostingList 会使用 Frame Of Reference(FOR) 编码技术对里边的数据进行压缩,节约磁盘空间
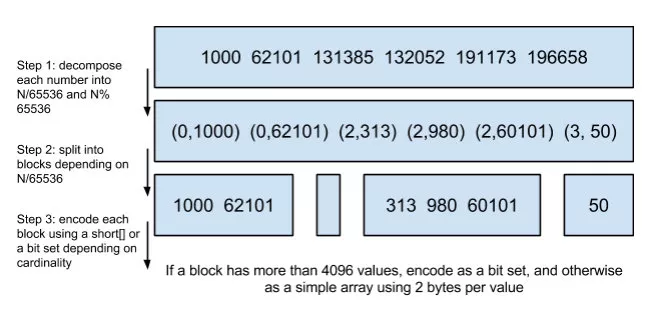
PostingList 里边存的是 文档ID,查询的时候往往需要对这些文档 ID 做交集和并集的操作(比如在多条件查询时) , PostingList 使用 Roaring Bitmaps 来对 文档ID 进行交并集操作
使用 Roaring Bitmaps 的好处就是可以节省空间和快速得出交并集的结果
Elasticsearch的术语和架构
- Index: Elasticsearch的Index相当于数据库的Table
- Type: 这个在新的Elasticsearch版本已经废除(在以前的Elasticsearch版本,一个Index下支持多个Type–有点类似于消息队列一个topic下多个group的概念)
- Document: Document相当于数据库的一行记录
- Field: 相当于数据库的Column的概念
- Mapping: 相当于数据库的Schema的概念
- DSL: 相当于数据库的SQL(读取Elasticsearch数据的API)
| RBDMS | Elasticsearch |
|---|---|
| Table | index(Type) |
| Row | Document |
| column | Field |
| Schema | Mapping |
| SQL | DSL |
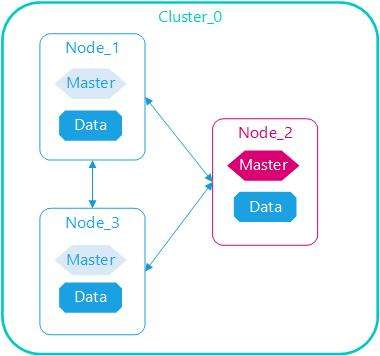
一个 Elasticsearch 集群会有多个 Elasticsearch 节点,所谓节点实际上就是运行着 Elasticsearch 进程的机器
在众多的节点中,其中会有一个 Master Node ,它主要负责维护索引元数据、负责切换主分片和副本分片身份等工作(后面会讲到分片的概念),如果主节点挂了,会选举出一个新的主节点
分片: Elasticsearch 最外层的是 Index(相当于数据库 表的概念);一个 Index 的数据可以分发到不同的 Node 节点上进行存储,这个操作就叫做分片
比如现在集群里边有 4 个节点,现在有一个 Index(表),想将这个 Index 在 4 个节点上存储,可以设置为 4 个分片。这 4 个分片的数据合起来就是 Index 的数据
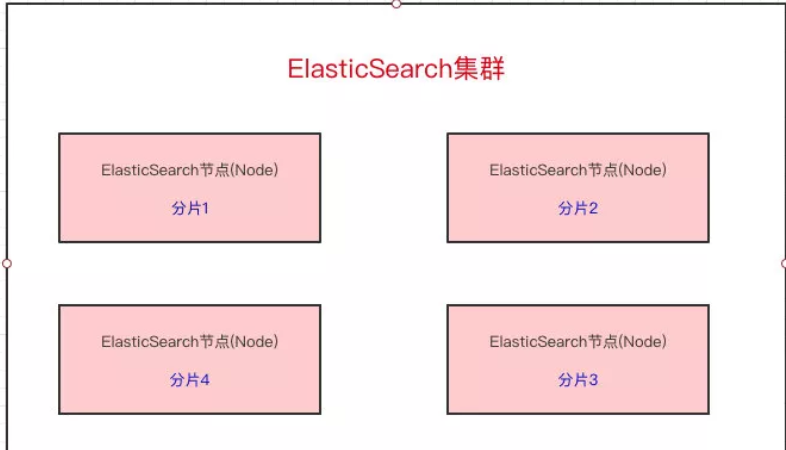
分片的原因:
- 如果一个 Index 的数据量太大,只有一个分片,那只会在一个节点上存储,随着数据量的增长,一个节点未必能把一个 Index 存储下来
- 多个分片,在写入或查询的时候就可以并行操作(从各个节点中读写数据,提高吞吐量)
如果某个节点挂了,部分数据是否会丢失呢?针对这个问题,Elasticsearch 的分片有了主分片和副本分片的区别(同样为了实现高可用)
数据写入的时候 写到主分区 , 副本分片会 复制主分片 的数据,读取的时候 主分片和副本分片都可以读取
这里主副本和很多分布式框架的原理几乎都是一致的
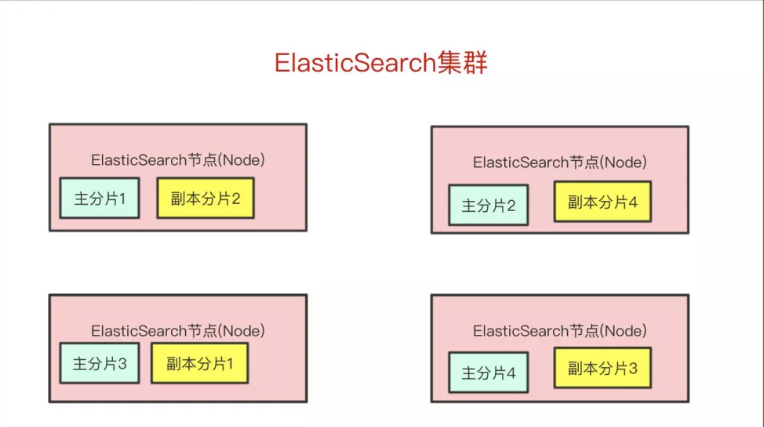
如果某个节点挂了,前面所提高的 Master Node 就会把对应的副本分片提拔为主分片,这样即便节点挂了,数据就不会丢
问题一:分片和水平扩展的理解
和redis集群的插槽类似,通过分片的方式,将大数据做拆分
索引在创建的时候,设置固定的分片(单个分片20G-50G合理)
假设:一个index,3个分片,总量30G。每个分片承担10G
现在只有一个es节点,那么3个分片都在一台机器上
水平扩展:新增2个es节点,那么3个分片散落在3个节点上
问题二:ES需要预留50%内存给文件系统缓存
核心原因:确保ES的热点索引数据不会被其他应用程序或系统压力”挤出去”
1
2
3
4
5
6
7
# 糟糕的场景:内存竞争
总内存: 64GB
ES JVM堆: 48GB (75%)
其他应用: 10GB
系统/缓存: 只剩6GB
结果:ES的索引数据频繁被挤出缓存 → 搜索性能急剧下降
1
2
3
4
5
# 理想的场景:专用缓存
总内存: 64GB
ES JVM堆: 31GB (~48%)
文件系统缓存: ~33GB (专用于缓存ES索引文件)
其他应用: 在单独的服务器上运行
问题三:结合内存,ES的搜索流程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
用户搜索请求
↓
ES协调节点接收请求
↓
查询被发送到各个分片
↓
每个分片在本地执行搜索:
↓
1. 检查JVM堆内存中的字段数据缓存
2. 通过Page Cache访问倒排索引、文档值等Lucene数据结构
3. 如果Page Cache未命中,从磁盘读取并填充缓存
↓
各分片返回结果给协调节点
↓
协调节点合并、排序结果
↓
返回最终结果给用户
Elasticsearch 写入的流程
上面已经知道当我们向 Elasticsearch 写入数据的时候,是写到主分片上的
客户端写入一条数据,到 Elasticsearch 集群里边就是由节点来处理这次请求:
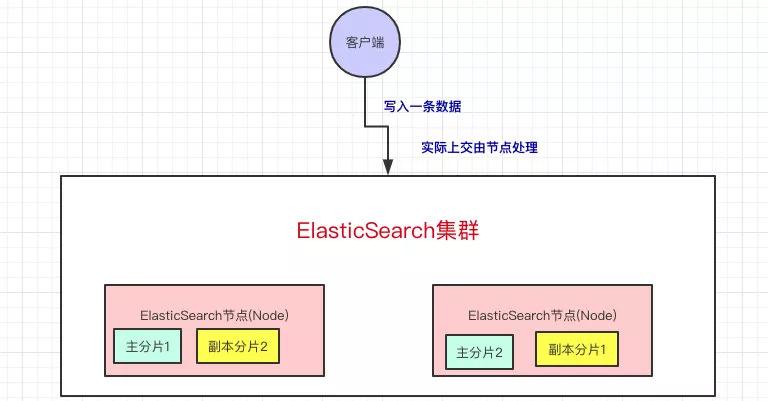
集群上的每个节点都是 coordinating node(协调节点),协调节点表明这个节点可以做路由。比如 节点1 接收到了请求,但发现这个请求的数据应该是由 节点2 处理(因为主分片在 节点2 上),所以会把请求转发到节点2上
- coodinate(协调)节点通过 hash 算法可以计算出是在哪个主分片上,然后路由到对应的节点
- shard = hash(document_id) % (num_of_primary_shards)
路由到对应的节点以及对应的主分片时,会做以下的事:
- 将数据写到内存缓存区
- 然后将数据写到 translog 缓存区
- 每隔 1s 数据从 buffer 中 refresh 到 FileSystemCache 中,生成 segment 文件,一旦生成 segment 文件,就能通过索引查询到了
- refresh 完,memory buffer 就清空了
- 每隔 5s 中,translog 从 buffer flush 到磁盘中
- 定期/定量从 FileSystemCache 中,结合 translog 内容 flush index 到磁盘中
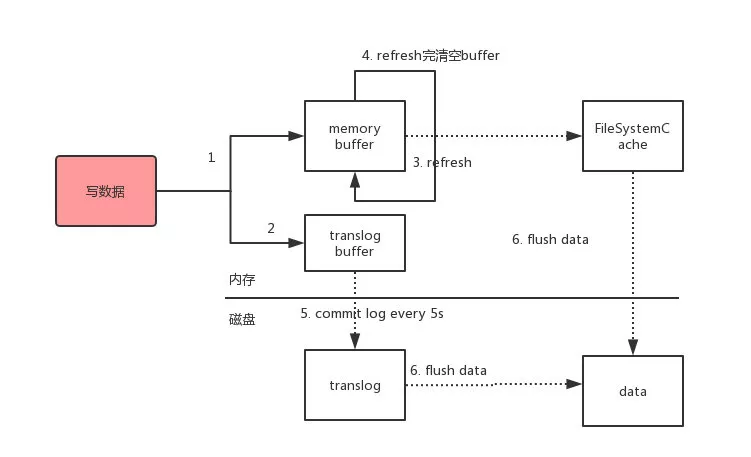
- Elasticsearch 会把数据先写入内存缓冲区,然后每隔 1s 刷新到文件系统缓存区(当数据被刷新到文件系统缓冲区以后,数据才可以被检索到)。所以:Elasticsearch 写入的数据需要 1s 才能查询到
- 为了防止节点宕机,内存中的数据丢失,Elasticsearch 会另写一份数据到日志文件上,但最开始的还是写到内存缓冲区,每隔 5s 才会将缓冲区的刷到磁盘中。所以:Elasticsearch 某个节点如果挂了,可能会造成有 5s 的数据丢失
- 等到磁盘上的 translog 文件大到一定程度或者超过了 30 分钟,会触发 commit 操作,将内存中的 segment 文件异步刷到磁盘中,完成持久化操作
段( segment )是一种在数据库中消耗物理存储空间的任何实体(一个段可能存在于多个数据文件中,因为物理的数据文件 是组成逻辑表空间的基本物理存储单位)
写内存缓冲区(定时去生成 segment,生成 translog ),能够让数据能被索引、被持久化。最后通过 commit 完成一次的持久化

等主分片写完了以后,会将数据并行发送到副本集节点上,等到所有的节点写入成功就返回 ack 给协调节点,协调节点返回 ack 给客户端,完成一次的写入
Elasticsearch更新和删除
Elasticsearch 的更新和删除操作流程:
给对应的 doc 记录打上 .del 标识,如果是删除操作就打上 delete 状态,如果是更新操作就把原来的 doc 标志为 delete,然后重新新写入一条数据
前面提到了,每隔 1s 会生成一个 segment 文件,那 segment 文件会越来越多越来越多。Elasticsearch 会有一个 merge 任务,会将多个 segment 文件合并成一个 segment 文件
在合并的过程中,会把带有 delete 状态的 doc 给物理删除掉

Elasticsearch查询
查询最简单的方式可以分为两种:
- 根据 ID 查询 doc
- 根据 query(搜索词)去查询匹配的 doc
1
2
public TopDocs search(Query query, int n);
public Document doc(int docID);
根据 ID 去查询具体的 doc 的流程是:
- 检索内存的 Translog 文件
- 检索硬盘的 Translog 文件
- 检索硬盘的 Segement 文件
根据 query 去匹配 doc 的流程是:
- 同时去查询内存和硬盘的 Segement 文件
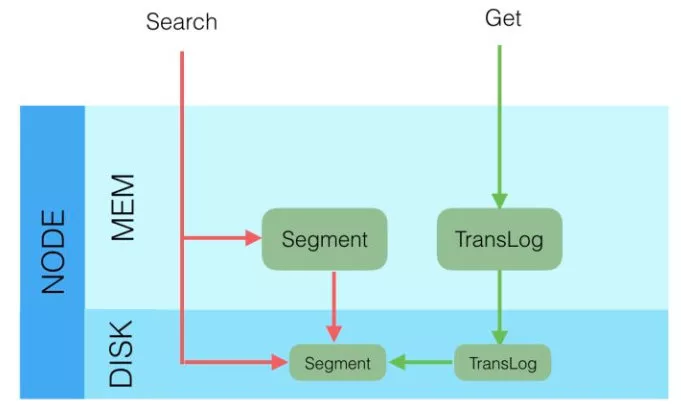
从上面所讲的写入流程可以知道:Get(通过 ID 去查 Doc 是实时的),Query(通过 query 去匹配 Doc 是近实时的)
- 因为 segement 文件是每隔一秒才生成一次的
Elasticsearch 查询又分可以为三个阶段
- QUERY_AND_FETCH(查询完就返回整个 Doc 内容)
- QUERY_THEN_FETCH(先查询出对应的 Doc id ,然后再根据 Doc id 匹配去对应的文档)
- DFS_QUERY_THEN_FETCH(先算分,再查询)
这里的 分 指的是词频率和文档的频率(Term Frequency、Document Frequency)众所周知,出现频率越高,相关性就更强
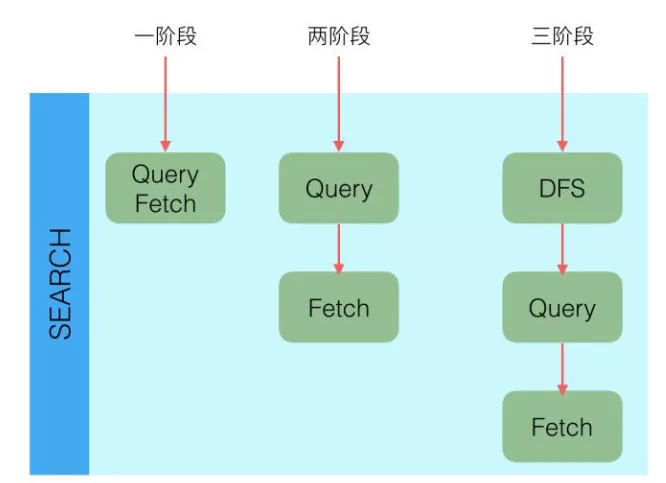
一般用得最多的就是 QUERY_THEN_FETCH (按分算),第一种查询完就返回整个 Doc 内容(QUERY_AND_FETCH)只适合于只需要查一个分片的请求
QUERY_THEN_FETCH 总体的流程流程大概是:
- 客户端请求发送到集群的某个节点上。集群上的每个节点都是coordinate node(协调节点)
- 然后协调节点将搜索的请求转发到所有分片上(主分片和副本分片都行)
- 每个分片将自己搜索出的结果(doc id)返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果
- 接着由协调节点根据 doc id 去各个节点上拉取实际的 document 数据,最终返回给客户端
1. Query Phase 阶段时节点做的事:
- 协调节点向目标分片发送查询的命令(转发请求到主分片或者副本分片上)
- 数据节点(在每个分片内做过滤、排序等等操作),返回 doc id 给协调节点
2. Fetch Phase 阶段时节点做的是:
- 协调节点得到数据节点返回的 doc id,对这些 doc id 做聚合,然后将目标数据分片发送抓取命令(希望拿到整个 Doc 记录)
- 数据节点按协调节点发送的 doc id,拉取实际需要的数据返回给协调节点
由于 Elasticsearch 是分布式的,所以需要从各个节点都拉取对应的数据,然后最终统一合成给客户端,只是 Elasticsearch 把这些活都干了,我们在使用的时候无感知而已

Java API - 创建索引
1. 生成JSON
创建索引的第一步是要把对象转换成 JSON 字符串,官网给出四种创建 JSON 文档的方法: 官网文档
- 手写方式
1
2
3
4
5
String json = "{" +
"\"user\":\"kimchy\"," +
"\"postDate\":\"2013-01-30\"," +
"\"message\":\"trying out Elasticsearch\"" +
"}";
- 集合
1
2
3
4
Map<String, Object> json = new HashMap<String, Object>();
json.put("user","kimchy");
json.put("postDate","2013-01-30");
json.put("message","trying out Elasticsearch");
- jackson 序列化
1
2
3
4
5
// instance a json mapper
ObjectMapper mapper = new ObjectMapper(); // create once, reuse
// generate json
byte[] json = mapper.writeValueAsBytes(yourbeaninstance);
- ElasticSearch 帮助类
1
2
3
4
5
6
7
8
9
10
import static org.elasticsearch.common.xcontent.XContentFactory.*;
XContentBuilder builder = jsonBuilder()
.startObject()
.field("user", "kimchy")
.field("postDate", new Date())
.field("message", "trying out Elasticsearch")
.endObject()
String json = builder.string();
2. 创建索引
- 使用 ElasticSearch 帮助类生成 JSON 创建索引,索引库名 twitter 、 类型 tweet 、 id 为 1
1
2
3
4
5
6
7
8
9
10
11
import static org.elasticsearch.common.xcontent.XContentFactory.*;
IndexResponse response = client.prepareIndex("twitter", "tweet", "1")
.setSource(jsonBuilder()
.startObject()
.field("user", "kimchy")
.field("postDate", new Date())
.field("message", "trying out Elasticsearch")
.endObject()
)
.get();
- 直接写入 JSON 字符串
1
2
3
4
5
6
7
8
9
String json = "{" +
"\"user\":\"kimchy\"," +
"\"postDate\":\"2013-01-30\"," +
"\"message\":\"trying out Elasticsearch\"" +
"}";
IndexResponse response = client.prepareIndex("twitter", "tweet")
.setSource(json)
.get();
使用 client 返回的 IndexResponse 对象的方法获取返回信息
1
2
3
4
5
6
7
8
9
10
// 索引名称
String _index = response.getIndex();
// 类型名称
String _type = response.getType();
// 文档id
String _id = response.getId();
// 版本(if it's the first time you index this document, you will get: 1)
long _version = response.getVersion();
// 是否被创建is true if the document is a new one, false if it has been updated
boolean created = response.isCreated();
Java 创建索引、插入数据完整版
新建一个 java 项目,导入 elasticsearch-2.3.3/lib 目录下的 jar 文件.新建一个 Blog 类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public class Blog {
private Integer id;
private String title;
private String posttime;
private String content;
public Blog() {
}
public Blog(Integer id, String title, String posttime, String content) {
this.id = id;
this.title = title;
this.posttime = posttime;
this.content = content;
}
//setter and getter
}
创建 java 实体类转 json 工具类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
import java.io.IOException;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
public class JsonUtil {
// Java实体对象转json对象
public static String model2Json(Blog blog) {
String jsonData = null;
try {
XContentBuilder jsonBuild = XContentFactory.jsonBuilder();
jsonBuild.startObject().field("id", blog.getId())
.field("title", blog.getTitle())
.field("posttime", blog.getPosttime())
.field("content",blog.getContent())
.endObject();
jsonData = jsonBuild.string();
//System.out.println(jsonData);
} catch (IOException e) {
e.printStackTrace();
}
return jsonData;
}
}
添加数据,返回一个 list:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
public class DataFactory {
public static DataFactory dataFactory = new DataFactory();
private DataFactory() {
}
public DataFactory getInstance() {
return dataFactory;
}
public static List<String> getInitJsonData() {
List<String> list = new ArrayList<String>();
String data1 = JsonUtil.model2Json(new Blog(1, "git简介", "2016-06-19", "SVN与Git最主要的区别..."));
String data2 = JsonUtil.model2Json(new Blog(2, "Java中泛型的介绍与简单使用", "2016-06-19", "学习目标 掌握泛型的产生意义..."));
String data3 = JsonUtil.model2Json(new Blog(3, "SQL基本操作", "2016-06-19", "基本操作:CRUD ..."));
String data4 = JsonUtil.model2Json(new Blog(4, "Hibernate框架基础", "2016-06-19", "Hibernate框架基础..."));
String data5 = JsonUtil.model2Json(new Blog(5, "Shell基本知识", "2016-06-19", "Shell是什么..."));
list.add(data1);
list.add(data2);
list.add(data3);
list.add(data4);
list.add(data5);
return list;
}
}
创建索引、添加数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
import java.io.IOException;
import java.net.InetAddress;
import java.net.UnknownHostException;
import java.util.Date;
import java.util.List;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.Client;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.common.xcontent.XContentBuilder;
import static org.elasticsearch.common.xcontent.XContentFactory.*;
public class ElasticSearchHandler {
public static void main(String[] args) {
try {
/* 创建客户端 */
// client startup
Client client = TransportClient.builder().build()
.addTransportAddress(
new InetSocketTransportAddres(
InetAddress.getByName("127.0.0.1"),
9300
)
);
List<String> jsonData = DataFactory.getInitJsonData();
for (int i = 0; i < jsonData.size(); i++) {
IndexResponse response = client.prepareIndex("blog", "article").setSource(jsonData.get(i)).get();
if (response.isCreated()) {
System.out.println("创建成功!");
}
}
client.close();
} catch (UnknownHostException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Java API - 检索索引库
一次查询可分为四个步骤:
1. 创建连接 ElasticSearch 服务的 client
1
2
3
4
5
6
7
Client client = TransportClient.builder().build()
.addTransportAddress(
new InetSocketTransportAddress(
InetAddress.getByName("127.0.0.1"),
9300
)
);
2. 创建 QueryBuilder
QueryBuilder 可以设置单个字段的查询,也可以设置多个字段的查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public class Blog {
private Integer id;
private String title;
private String posttime;
private String content;
public Blog() {
}
public Blog(Integer id, String title, String posttime, String content) {
this.id = id;
this.title = title;
this.posttime = posttime;
this.content = content;
}
//setter and getter
}
- 查询 title 字段中包含 hibernate 关键字的文档:
1
QueryBuilder qb1 = QueryBuilders.termQuery("title", "hibernate")
- 查询 title 字段或 content 字段中包含 git 关键字的文档:
1
QueryBuilder qb2 = QueryBuilders.multiMatchQuery("git", "title","content");
- termsQuery 多 term 查询,查询 title 包含 hibernate 或 myBatis 中的任何一个或多个的文档
1
QueryBuilders.termsQuery("title","hibernate","myBatis")
- range query 范围查询 查询 hotelNo
1
2
3
4
5
QueryBuilders.rangeQuery("hotelNo")
.gt("10143262306") //大于 10143262306
.lt("101432623062055348221") //小于 101432623062055348221
.includeLower(true) //包括下界
.includeUpper(false); //包括上界
- exist query 查询字段不为 null 的文档 查询字段 address 不为 null 的数据
1
QueryBuilders.existsQuery("address")
- prefix query 匹配分词前缀 如果字段没分词,就匹配整个字段前缀
1
QueryBuilders.prefixQuery("hotelName","花园")
- wildcard query 通配符查询,支持* 任意字符串;?任意一个字符
1
2
QueryBuilders.wildcardQuery("channelCode","ctr*")
QueryBuilders.wildcardQuery("channelCode","ctr?")
-
regexp query 正则表达式匹配分词
-
fuzzy query 分词模糊查询,通过增加 fuzziness 模糊属性,来查询term 如下能够匹配 hotelName 为 te el tel前或后加一个字母的 term的 文档 fuzziness 的含义是检索的 term 前后增加或减少 n 个单词的匹配查询
1
QueryBuilders.fuzzyQuery("hotelName", "tel").fuzziness(Fuzziness.ONE)
3. 执行查询
通过 client 设置查询的 index、type、query 返回一个 SearchResponse 对象:
1
2
3
4
5
SearchResponse response = client.prepareSearch("blog")
.setTypes("article")
.setQuery(qb2)
.execute()
.actionGet();
4. 处理查询结果
SearchResponse 对象的 getHits() 方法获取查询结果 ,返回一个 SearchHits 的集合,遍历集合获取查询的文档信息
1
SearchHits hits = response.getHits();
Java 检索索引库完整版
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
import java.net.InetAddress;
import java.net.UnknownHostException;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.Client;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.index.query.MultiMatchQueryBuilder;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import static org.elasticsearch.index.query.QueryBuilders.*;
public class ElasticSearchGet {
public static void main(String[] args) {
// client startup
try {
Client client = TransportClient.builder().build()
.addTransportAddress(
new InetSocketTransportAddress(
InetAddress.getByName("127.0.0.1"),
9300
));
QueryBuilder qb1 = termQuery("title", "hibernate");
QueryBuilder qb2= QueryBuilders.multiMatchQuery("git", "title","content");
SearchResponse response = client.prepareSearch("blog").setTypes("article")
.setQuery(qb2)
.execute()
.actionGet();
SearchHits hits = response.getHits();
if (hits.totalHits() > 0) {
for (SearchHit hit : hits) {
System.out.println("score:" + hit.getScore()+":\t"+hit.getSource());// .get("title")
}
} else {
System.out.println("搜到0条结果");
}
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
}
查询结果:
1
2
3
4
5
6
log4j:WARN No appenders could be found for logger (org.elasticsearch.plugins).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
score:0.5: {posttime=2016-06-19, id=1, title=git简介, content=SVN与Git最主要的区别...}
score:0.17673586: {posttime=2016-06-19, id=7, title=Mysql基本知识, content=git是什么...}
score:0.049935166: {posttime=2016-06-19, id=5, title=Git基本知识git, content=Shell是什么...}
Java API - 更新索引库
1. 创建要给 UpdateRequest , 将其发送给 client
1
2
3
4
5
6
7
UpdateRequest uRequest = new UpdateRequest();
uRequest.index("blog");
uRequest.type("article");
uRequest.id("2");
uRequest.doc(jsonBuilder().startObject().field("content", "学习目标 掌握java泛型的产生意义ssss").endObject()
);
client.update(uRequest).get();
2. prepareUpdate()
使用脚本方式
打开 elasticsearch-2.3.3/config/elasticsearch.yml ,新增一行:
1
script.engine.groovy.inline.update: on
之后重启 elasticsearch
使用 script 方式
1
2
3
4
5
6
client.prepareUpdate("blog", "article", "1")
.setScript(new Script("ctx._source.title = \"git入门\""
, ScriptService.ScriptType.INLINE
, null
, null)
).get();
使用 doc 方式
1
2
3
4
5
6
client.prepareUpdate("blog", "article", "1")
.setDoc(
jsonBuilder().startObject()
.field("content", "SVN与Git对比。。。")
.endObject()
).get();
3. updateRequest()
使用 script 方式
1
2
3
UpdateRequest updateRequest = new UpdateRequest("ttl", "doc", "1")
.script(new Script("ctx._source.gender = \"male\""));
client.update(updateRequest).get();
使用 doc 方式
1
2
3
4
5
6
UpdateRequest updateRequest = new UpdateRequest("index", "type", "1")
.doc(jsonBuilder()
.startObject()
.field("gender", "male")
.endObject());
client.update(updateRequest).get();
4. upsert()
如果文档不存在则创建新的索引
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
IndexRequest indexRequest = new IndexRequest("index", "type", "1")
.source(jsonBuilder()
.startObject()
.field("name", "Joe Smith")
.field("gender", "male")
.endObject());
UpdateRequest updateRequest = new UpdateRequest("index", "type", "1")
.doc(jsonBuilder()
.startObject()
.field("name", "Joe Dalton")
.endObject())
.upsert(indexRequest);
client.update(updateRequest).get();
Java 更新索引库完整版
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
import java.io.IOException;
import java.net.InetAddress;
import java.net.UnknownHostException;
import java.util.concurrent.ExecutionException;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.client.Client;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.script.Script;
import org.elasticsearch.script.ScriptService;
import static org.elasticsearch.common.xcontent.XContentFactory.*;
public class ElasticSearchUpdate {
private static Client client;
public static void main(String[] args) {
try {
// client startup
client = TransportClient.builder().build()
.addTransportAddress(
new InetSocketTransportAddress(
InetAddress.getByName("127.0.0.1")
, 9300)
);
} catch (UnknownHostException e) {
e.printStackTrace();
}
upMethod1();
}
/**
*方法一:创建一个UpdateRequest,然后将其发送给client.
*/
public static void upMethod1() {
try {
UpdateRequest uRequest = new UpdateRequest();
uRequest.index("blog");
uRequest.type("article");
uRequest.id("22");
uRequest.doc(jsonBuilder().startObject().field("content", "学习目标 掌握java泛型的产生意义ssss").endObject());
client.update(uRequest).get();
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
/**
*方法二:prepareUpdate() 使用脚本更新索引.
*/
public static void upMethod2() {
client.prepareUpdate("blog", "article", "1")
.setScript(
new Script("ctx._source.title = \"git入门\""
, ScriptService.ScriptType.INLINE
, null
, null)
).get();
}
/**
*方法三:prepareUpdate() 使用doc更新索引.
*/
public static void upMethod3() {
try {
client.prepareUpdate("blog", "article", "1")
.setDoc(
jsonBuilder().startObject()
.field("content", "SVN与Git对比。。。").endObject()
).get();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
*方法四: 增加新的字段.
*/
public static void upMethod4() {
try {
UpdateRequest updateRequest = new UpdateRequest("blog", "article", "1")
.doc(jsonBuilder().startObject()
.field("commet", "0")
.endObject()
);
client.update(updateRequest).get();
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
/**
*方法五:upsert 如果文档不存在则创建新的索引.
*/
public static void upMethod5() {
try {
IndexRequest indexRequest = new IndexRequest("blog", "article", "10")
.source(
jsonBuilder().startObject()
.field("title", "Git安装10")
.field("content", "学习目标 git。。。10")
.endObject()
);
UpdateRequest uRequest2 = new UpdateRequest("blog", "article", "10").doc(
jsonBuilder().startObject()
.field("title", "Git安装")
.field("content", "学习目标 git。。。")
.endObject()
)
.upsert(indexRequest);
client.update(uRequest2).get();
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
Java API - 删除索引
删除可以是删除整个索引库,也可以根据文档 id 删除索引库下的文档 ,还可以通过 query 查询条件删除所有符合条件的数据
1. 删除整个索引库
1
2
3
4
DeleteIndexResponse dResponse = client.admin().indices()
.prepareDelete("indexName")
.execute()
.actionGet();
可以根据 DeleteIndexResponse 对象的 isAcknowledged() 方法判断删除是否成功,返回值为 boolean 类型
如果传入的 indexName 不存在会出现异常.可以先判断索引是否存在
1
2
3
4
IndicesExistsRequest inExistsRequest = new IndicesExistsRequest(indexName);
IndicesExistsResponse inExistsResponse = client.admin().indices()
.exists(inExistsRequest).actionGet();
根据 IndicesExistsResponse 对象的 isExists() 方法的 boolean 返回值可以判断索引库是否存在
2. 通过 ID 删除
删除索引名为 blog ,类型为 article ,id 为 1 的文档:
1
2
3
4
DeleteResponse dResponse = client.prepareDelete("blog"
, "article"
, "1"
).execute().actionGet();
通过 DeleteResponse 对象的 isFound() 方法,可以得到删除是否成功,返回值为 boolean 类型
3. Delete By Query
要删除某个索引的一个 type 下的所有文档,相当于关系型数据库中的清空表操作。查阅了一些资料可以通过 Delete-by-Query 插件删除,首先使用插件管理器安装 Delete-by-Query 插件
sudo bin/plugin install delete-by-query
集群有多个节点的情况下,每个节点都需要安装并重启
如果想要移除插件,可以执行以下命令:
sudo bin/plugin remove delete-by-query
Doc 命令方式:
删除索引名为twitter,类型为tweet,user字段中含有kimchy的所有文档:
DELETE /twitter/tweet/_query?q=user:kimchy
删除一个 type 下的所有文档:命令行方式
1
2
3
4
5
6
CURL -XDELETE "http://192.168.0.224:9200/blog/article/_query" -d '{
"query": {
"match_all": {}
}
}
'
Java API 方式:
导包:
elasticsearch-2.3.3/plugins/delete-by-query/delete-by-query-2.3.3.jar 加到工程路径中
修改 client 的创建方式,添加 addPlugin
1
2
3
4
5
6
7
8
9
10
Client client = TransportClient.builder()
.settings(settings)
.addPlugin(DeleteByQueryPlugin.class)
.build()
.addTransportAddress(
new InetSocketTransportAddress(
InetAddress.getByName("192.168.0.224")
, 9300
)
);
Java API 删除
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import org.elasticsearch.action.deletebyquery.DeleteByQueryAction;
import org.elasticsearch.action.deletebyquery.DeleteByQueryRequestBuilder;
import org.elasticsearch.action.deletebyquery.DeleteByQueryResponse;
import org.elasticsearch.plugin.deletebyquery.DeleteByQueryPlugin;
String deletebyquery = "{\"query\": {\"match_all\": {}}}";
DeleteByQueryResponse response = new DeleteByQueryRequestBuilder(client,
DeleteByQueryAction.INSTANCE)
.setIndices("blog")
.setTypes("article")
.setSource(deletebyquery)
.execute()
.actionGet();
Java API - 删除索引库完整版
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
import static org.elasticsearch.index.query.QueryBuilders.termQuery;
import java.net.InetAddress;
import java.net.UnknownHostException;
import org.elasticsearch.action.admin.indices.create.CreateIndexRequest;
import org.elasticsearch.action.admin.indices.create.CreateIndexResponse;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexResponse;
import org.elasticsearch.action.admin.indices.exists.indices.IndicesExistsRequest;
import org.elasticsearch.action.admin.indices.exists.indices.IndicesExistsResponse;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.client.Client;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.index.query.QueryBuilder;
public class ElasticSearchCreate {
// ElasticSearch server ip
private static String ServerIP = "127.0.0.1";
// port
private static int ServerPort = 9300;
private Client client;
public static void main(String[] args) {
try {
Client client = TransportClient.builder().build().addTransportAddress(
new InetSocketTransportAddress(
InetAddress.getByName("127.0.0.1")
, 9300
)
);
DeleteResponse dResponse = client.prepareDelete("blog", "article", "11").execute()
.actionGet();
if (dResponse.isFound()) {
System.out.println("删除成功");
} else {
System.out.println("删除失败");
}
QueryBuilder qb1 = termQuery("title", "hibernate");
} catch (UnknownHostException e) {
e.printStackTrace();
}
//删除名为test的索引库
deleteIndex("test");
}
/*
* 删除索引库
*/
public static void deleteIndex(String indexName) {
try {
if (!isIndexExists(indexName)) {
System.out.println(indexName + " not exists");
} else {
Client client = TransportClient.builder().build().addTransportAddress(
new InetSocketTransportAddress(
InetAddress.getByName(ServerIP)
,ServerPort
)
);
DeleteIndexResponse dResponse = client.admin(). indices()
.prepareDelete(indexName)
.execute()
.actionGet();
if (dResponse.isAcknowledged()) {
System.out.println("delete index "+indexName+" successfully!");
}else{
System.out.println("Fail to delete index "+indexName);
}
}
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
/*
* 创建索引库
*/
public static void createIndex(String indexName) {
try {
Client client = TransportClient.builder().build().addTransportAddress(
new InetSocketTransportAddress(
InetAddress.getByName(ServerIP)
, ServerPort
)
);
// 创建索引库
if (isIndexExists("indexName")) {
System.out.println("Index " + indexName + " already exits!");
} else {
CreateIndexRequest cIndexRequest = new CreateIndexRequest("indexName");
CreateIndexResponse cIndexResponse = client.admin().indices().create(cIndexRequest)
.actionGet();
if (cIndexResponse.isAcknowledged()) {
System.out.println("create index successfully!");
} else {
System.out.println("Fail to create index!");
}
}
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
/*
* 判断索引是否存在 传入参数为索引库名称
*/
public static boolean isIndexExists(String indexName) {
boolean flag = false;
try {
Client client = TransportClient.builder().build().addTransportAddress(
new InetSocketTransportAddress(InetAddress.getByName(ServerIP), ServerPort));
IndicesExistsRequest inExistsRequest = new IndicesExistsRequest(indexName);
IndicesExistsResponse inExistsResponse = client.admin().indices()
.exists(inExistsRequest).actionGet();
if (inExistsResponse.isExists()) {
flag = true;
} else {
flag = false;
}
} catch (UnknownHostException e) {
e.printStackTrace();
}
return flag;
}
}
Java API - Bulk 批量操作
每一个操作都有 2 行数据组成,末尾要回车换行。第一行用来说明操作命令和元数据、第二行是自定义的选(有效载体(非必选),例如 Index 操作,其有效载荷为 IndexRequest#source 字段) ,举个例子 ,同时执行插入2条数据、删除一条数据 , 新建 bulkdata.json , 写入如下内容:
1
2
3
4
5
6
7
{ "create" : { "_index" : "blog", "_type" : "article", "_id" : "3" }}
{ "title":"title1","posttime":"2016-07-02","content":"内容一" }
{ "create" : { "_index" : "blog", "_type" : "article", "_id" : "4" }}
{ "title":"title2","posttime":"2016-07-03","content":"内容2" }
{ "delete":{"_index" : "blog", "_type" : "article", "_id" : "1" }}
注意:行末要回车换行,不然会因为命令不能识别而出现错误.
Bulk 格式:
1
2
3
POST _bulk
{action:{metadata}}\n
{requestbody}\n
action:行为
- create:文档不存在时创建
- update:更新文档
- index:创建新文档或替换已有文档
- delete:删除一个文档
create和index的区别:如果数据存在,使用create操作失败,会提示文档已经存在,使用index可以成功执行
metadata:公用元数据
- _index :索引名
- _type:类型名
- _id:文档ID
- routing:路由值
- parent
- version:数据版本号
- version_type:版本类型
各操作特有元数据
-
index create
pipeline
- update
retry_on_conflict:更新冲突时重试次数 _source:字段过滤
有效载荷说明
| index | create:有效载荷为_source字段 |
update:有效载荷为:partial doc、upsert and script
delete:没有有效载荷
对请求格式为什么要设计成 metdata+ 有效载体的方式,主要是为了在接受端节点(所谓的接受端节点是指收到命令的第一节点),只需解析 metadata ,然后将请求直接转发给对应的数据节点
Java API - Bulk批量操作完整版
批量导出
例子是把索引库中的文档以json格式批量导出到文件中,其中集群名称为”bropen”,索引库名为”blog”,type为”article”,项目根目录下新建files/bulk.txt,索引内容写入bulk.txt中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.net.InetAddress;
import java.net.UnknownHostException;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.Client;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHits;
public class ElasticSearchBulkOut {
public static void main(String[] args) {
try {
Settings settings = Settings.settingsBuilder()
.put("cluster.name", "bropen").build();// cluster.name在elasticsearch.yml
Client client = TransportClient.builder().settings(settings).build()
.addTransportAddress(new InetSocketTransportAddress(
InetAddress.getByName("127.0.0.1"), 9300));
QueryBuilder qb = QueryBuilders.matchAllQuery();
SearchResponse response = client.prepareSearch("blog")
.setTypes("article").setQuery(QueryBuilders.matchAllQuery())
.execute().actionGet();
SearchHits resultHits = response.getHits();
File article = new File("files/bulk.txt");
FileWriter fw = new FileWriter(article);
BufferedWriter bfw = new BufferedWriter(fw);
if (resultHits.getHits().length == 0) {
System.out.println("查到0条数据!");
} else {
for (int i = 0; i < resultHits.getHits().length; i++) {
String jsonStr = resultHits.getHits()[i]
.getSourceAsString();
System.out.println(jsonStr);
bfw.write(jsonStr);
bfw.write("\n");
}
}
bfw.close();
fw.close();
} catch (UnknownHostException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
批量导入
从刚才导出的 bulk.txt 文件中按行读取,然后 bulk 导入。首先通过调用 client.prepareBulk() 实例化一个 BulkRequestBuilder 对象,调用 BulkRequestBuilder 对象的 add 方法添加数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
import java.io.BufferedReader;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.net.InetAddress;
import java.net.UnknownHostException;
import org.elasticsearch.action.bulk.BulkRequestBuilder;
import org.elasticsearch.client.Client;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
public class ElasticSearchBulkIn {
public static void main(String[] args) {
try {
Settings settings = Settings.settingsBuilder()
.put("cluster.name", "bropen").build();// cluster.name在elasticsearch.yml中配置
Client client = TransportClient.builder().settings(settings).build()
.addTransportAddress(new InetSocketTransportAddress(
InetAddress.getByName("127.0.0.1"), 9300));
File article = new File("files/bulk.txt");
FileReader fr=new FileReader(article);
BufferedReader bfr=new BufferedReader(fr);
String line=null;
BulkRequestBuilder bulkRequest = client.prepareBulk();
int count=0;
while((line=bfr.readLine()) != null){
bulkRequest.add(client.prepareIndex("test","article").setSource(line));
if (count%10 == 0) {
bulkRequest.execute().actionGet();
}
count++;
//System.out.println(line);
}
bulkRequest.execute().actionGet();
bfr.close();
fr.close();
} catch (UnknownHostException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Java API - 多级嵌套搜索
要在 java 中实现一个有三级父子关系的嵌套搜索 ,相关资料较少,google + stackoverflow 很好使,对应的命令行query:
1
2
3
4
5
6
7
8
9
10
11
12
{
"query": {
"has_child": {
"type": "instance",
"query": {
"has_child": {
"type": "instance_permission",
"query": { "terms": { "uuid": { "index": "user", "type": "user", "id": "5", "path": "uuids" } } } }
}
}
}
}
Java API
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
TermsLookupQueryBuilder terms = QueryBuilders
.termsLookupQuery("uuid")
.lookupIndex("user")
.lookupType("user")
.lookupId("5")
.lookupPath("uuids");
HasChildQueryBuilder hQuery = QueryBuilders
.hasChildQuery("instance", QueryBuilders
.hasChildQuery("instance_permission", terms));
System.out.println("Exectuing Query 1");
System.out.println(hQuery.toString());
SearchResponse searchResponse1 = client
.prepareSearch("foo_oa_hr_askforleave")
.setQuery(hQuery).execute().actionGet();
System.out.println("There were "
+ searchResponse1.getHits().getTotalHits()
+ " results found for Query 1."
);
System.out.println(searchResponse1.toString());
System.out.println();
Java API - Multi Get API
1
2
3
4
5
6
7
8
9
10
11
12
MultiGetResponse multiGetItemResponses = client.prepareMultiGet()
.add("twitter", "tweet", "1") //注释1
.add("twitter", "tweet", "2", "3", "4") //注释2
.add("another", "type", "foo") //注释3
.get();
for (MultiGetItemResponse itemResponse : multiGetItemResponses) { //注释4
GetResponse response = itemResponse.getResponse();
if (response.isExists()) { //注释5
String json = response.getSourceAsString(); //注释6
}
}
注释1: 通过单一的ID获取一个文档 注释2:传入多个id,从相同的索引名/类型名中获取多个文档 注释3:可以同时获取不同索引中的文档 注释4:遍历结果集 注释5:检验文档是否存在 注释6:获取文档源
Java API - 分析聚合
Elasticsearch 不仅仅适合做全文检索,分析聚合功能也同样支持
准备数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
{"index":{ "_index": "books", "_type": "IT", "_id": "1" }}
{"id":"1","title":"Java编程思想","language":"java","author":"Bruce Eckel","price":70.20,"year": 2007,"description":"Java学习必读经典,殿堂级著作!赢得了全球程序员的广泛赞誉。"}
{"index":{ "_index": "books", "_type": "IT", "_id": "2" }}
{"id":"2","title":"Java程序性能优化","language":"java","author":"葛一鸣","price":46.50,"year": 2012,"description":"让你的Java程序更快、更稳定。深入剖析软件设计层面、代码层面、JVM虚拟机层面的优化方法"}
{"index":{ "_index": "books", "_type": "IT", "_id": "3" }}
{"id":"3","title":"Python科学计算","language":"python","author":"张若愚","price":81.40,"year": 2016,"description":"零基础学python,光盘中作者独家整合开发winPython运行环境,涵盖了Python各个扩展库"}
{"index":{ "_index": "books", "_type": "IT", "_id": "4" }}
{"id":"4","title":"Python基础教程","language":"python","author":"张若愚","price":54.50,"year": 2014,"description":"经典的Python入门教程,层次鲜明,结构严谨,内容翔实"}
{"index":{ "_index": "books", "_type": "IT", "_id": "5" }}
{"id":"5","title":"JavaScript高级程序设计","language":"javascript","author":"Nicholas C.Zakas","price":66.40,"year":2012,"description":"JavaScript技术经典名著"}
准备5条数据,保存着books.json中,批量导入:
1
curl -XPOST "http://localhost:9200/_bulk?pretty" --data-binary @books.json
Group By 分组统计
1
2
3
4
5
6
7
8
9
10
curl -XPOST "http://localhost:9200/books/_search?pretty" -d '{
"size": 0,
"aggs": {
"per_count": {
"terms": {
"field": "language"
}
}
}
}'
统计结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 5,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"per_count" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [ {
"key" : "java",
"doc_count" : 2
}, {
"key" : "python",
"doc_count" : 2
}, {
"key" : "javascript",
"doc_count" : 1
} ]
}
}
}
按编程语言分类,java 类 2 本 , python 类 1 本 , javascript 类 1 本
Max 最大值
执行命令,统计 price 最大的:
1
2
3
4
5
6
7
8
9
10
curl -XPOST "http://localhost:9200/books/_search?pretty" -d '{
"size": 0,
"aggs": {
"max_price": {
"max": {
"field": "price"
}
}
}
}'
返回结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 5,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"max_price" : {
"value" : 81.4
}
}
}
Min 最小值
求价格最便宜的那本:
1
2
3
4
5
6
7
8
9
10
curl -XPOST "http://localhost:9200/books/_search?pretty" -d '{
"size": 0,
"aggs": {
"max_price": {
"max": {
"field": "price"
}
}
}
}'
统计结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 5,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"max_price" : {
"value" : 81.4
}
}
}
Average 平均值
分组统计并求 5 本书的平均价格:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
curl -XPOST "http://localhost:9200/books/_search?pretty" -d '{
"size": 0,
"aggs": {
"per_count": {
"terms": {
"field": "language"
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
'
返回结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 5,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"per_count" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [ {
"key" : "java",
"doc_count" : 2,
"avg_price" : {
"value" : 58.35 }
}, {
"key" : "python",
"doc_count" : 2,
"avg_price" : {
"value" : 67.95 }
}, {
"key" : "javascript",
"doc_count" : 1,
"avg_price" : {
"value" : 66.4 }
} ]
}
}
}
Sum 求和
求5本书总价:
1
2
3
4
5
6
7
8
9
10
11
curl -XPOST "http://localhost:9200/books/_search?pretty" -d '
{
"size": 0,
"aggs": {
"sum_price": {
"sum": {
"field": "price"
}
}
}
}'
返回结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 5,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"sum_price" : {
"value" : 319.0
}
}
}
基本统计
基本统计会返回字段的最大值、最小值、平均值、求和:
1
2
3
4
5
6
7
8
9
10
curl -XPOST "http://localhost:9200/books/_search?pretty" -d '{
"size": 0,
"aggs": {
"grades_stats": {
"stats": {
"field": "price"
}
}
}
}'
返回结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 5,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"grades_stats" : {
"count" : 5,
"min" : 46.5,
"max" : 81.4,
"avg" : 63.8,
"sum" : 319.0
}
}
}
高级统计
高级统计还会返回方差、标准差等:
1
2
3
4
5
6
7
8
9
10
11
12
curl -XPOST "http://localhost:9200/books/_search?pretty" -d'
{
"size": 0,
"aggs": {
"grades_stats": {
"extended_stats": {
"field": "price"
}
}
}
}
'
统计结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 5,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"grades_stats" : {
"count" : 5,
"min" : 46.5,
"max" : 81.4,
"avg" : 63.8,
"sum" : 319.0,
"sum_of_squares" : 21095.46,
"variance" : 148.65199999999967,
"std_deviation" : 12.19229264740638,
"std_deviation_bounds" : {
"upper" : 88.18458529481276,
"lower" : 39.41541470518724
}
}
}
}
百分比统计
1
2
3
4
5
6
7
8
9
10
11
12
curl -XPOST "http://localhost:9200/books/_search?pretty" -d '
{
"size": 0,
"aggs": {
"load_time_outlier": {
"percentiles": {
"field": "year"
}
}
}
}
'
返回结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 5,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"load_time_outlier" : {
"values" : {
"1.0" : 2007.2,
"5.0" : 2008.0000000000002,
"25.0" : 2012.0,
"50.0" : 2012.0,
"75.0" : 2014.0,
"95.0" : 2015.6000000000001,
"99.0" : 2015.92
}
}
}
}
分段统计
统计价格小于50、50-80、大于80的百分比:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
curl -XPOST "http://localhost:9200/books/_search?pretty" -d '{
"size": 0,
"aggs": {
"price_ranges": {
"range": {
"field": "price",
"ranges": [{
"to": 50
}, {
"from": 50,
"to": 80
}, {
"from": 80
}]
}
}
}
}
'
返回结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 5,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"price_ranges" : {
"buckets" : [ {
"key" : "*-50.0",
"to" : 50.0,
"to_as_string" : "50.0",
"doc_count" : 1
}, {
"key" : "50.0-80.0",
"from" : 50.0,
"from_as_string" : "50.0",
"to" : 80.0,
"to_as_string" : "80.0",
"doc_count" : 3
}, {
"key" : "80.0-*",
"from" : 80.0,
"from_as_string" : "80.0",
"doc_count" : 1
} ]
}
}
}
聚合的 JAVA API
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
//创建TransportClient对象
client=EsUtils.getEsClient();
QueryBuilder matchQuery = QueryBuilders.matchQuery("title", "程序");
AbstractAggregationBuilder aggregation = AggregationBuilders.terms("per_count").field("language");
SearchResponse response = client.prepareSearch("books").setTypes("IT")
.setQuery(matchQuery)
.addAggregation(aggregation)
.execute()
.actionGet();
SearchHits hits = response.getHits();
for(SearchHit hit:hits){
System.out.println("id:"+hit.getId()+"\ttitle:"+hit.getSource().get("title"));
}
Terms terms = response.getAggregations().get("per_count");
List<Bucket> buckets = terms.getBuckets();
for(Bucket bucket:buckets){
System.out.println(bucket.getKey()+"----"+bucket.getDocCount());
}
client.close();
运行结果
1
2
3
4
id:2 title:Java程序性能优化
id:5 title:JavaScript高级程序设计
java----1
javascript----1
Java API - 指定分析器
分析器是写在 mapping 里面的,通过配置 analyzer 来指定。如果没有额外的配置, analyzer 中指定的分析器,既是索引期的分析器,又是搜索期的分析器。单独指定搜索期的分析器可以用 search_analyzer 覆盖
在搜索时指定分析器,只需要在构造 Query 的时候,增加一个 analyzer 配置
1
2
3
4
5
6
7
// 普通 MatchQuery
QueryBuilder matchQuery = QueryBuilders.matchQuery("title","足球")
// 指定搜索时分析器的 MatchQuery
QueryBuilder matchQuery = QueryBuilders
.matchQuery("title","足球")
.analyzer("ik_smart");
Java API - 获取分词器结果
Java API 获取 Elasticsearch 的分词结果,已安装 k中文分词器
先创建一个索引
1
curl -XPUT localhost:9200/bbb
标准分词
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public static void main(String[] args) {
TransportClient client = EsUtils.getSingleClient();
AnalyzeRequest analyzeRequest = new AnalyzeRequest("bbb")
.text("中华人民共和国国歌")
.analyzer("standard");
List<AnalyzeResponse.AnalyzeToken> tokens = client.admin().indices()
.analyze(analyzeRequest)
.actionGet()
.getTokens();
for (AnalyzeResponse.AnalyzeToken token : tokens) {
System.out.println(token.getTerm());
}
}
结果:
1
2
3
4
5
6
7
8
9
中
华
人
民
共
和
国
国
歌
ik_max_word分词
把 .analyzer("standard") 改成 .analyzer("ik_max_word") 分词结果如下:
1
2
3
4
5
6
7
8
9
10
中华人民共和国
中华人民
中华
华人
人民共和国
人民
共和国
共和
国
国歌
ik_smart分词
把 .analyzer("standard") 改成 .analyzer("ik_smart") 分词结果如下:
1
2
中华人民共和国
国歌