这篇笔记主要整理 Java 面试里经常出现的几类问题,包括 Spring AOP、Bean 生命周期、并发基础、数据库索引与事务隔离。内容以概念辨析和常见追问为主,适合在面试前快速回顾。
参考资料:
[TOC]
Spring的两种动态代理
- JDK 动态代理
- CGLib 动态代理
参考资料 博客、知乎AlanShelby、知乎
方法一:JDK动态代理
基于接口的 JDK 动态代理,针对目标对象的接口进行代理 ,动态生成接口的实现类 (必须有接口)
要点:
- 必须对接口生成代理
- 采用 Proxy 对象,通过 newProxyInstance 方法为目标创建代理对象
该方法接收三个参数 :
- 目标对象类加载器
- 目标对象实现的接口
- 代理对象的执行处理器 InvocationHandler
service层
1
2
3
4
5
6
7
//接口(表示代理的目标接口)
public interface ICustomerService {
//保存
void save();
//查询
int find();
}
实现层
1
2
3
4
5
6
7
8
9
10
11
12
13
//实现层
public class CustomerServiceImpl implements ICustomerService{
@Override
public void save() {
System.out.println("客户保存了。。。。。");
}
@Override
public int find() {
System.out.println("客户查询数量了。。。。。");
return 100;
}
}
JDK动态代理工厂
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
//专门用来生成jdk的动态代理对象的-通用
public class JdkProxyFactory{
//target目标对象
private Object target;
//注入target目标对象
public JdkProxyFactory(Object target) {
this.target = target;
}
public Object getProxyObject(){
/**
* 参数1:目标对象的类加载器
* 参数2:目标对象实现的接口
* 参数3:回调方法对象
*/
return Proxy.newProxyInstance(target.getClass().getClassLoader(), target.getClass().getInterfaces(),
new InvocationHandler(){
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//如果是保存的方法,执行记录日志操作
if(method.getName().equals("save")){
System.out.println("增强代码:写日志了。。。");
}
//目标对象原来的方法执行
Object object = method.invoke(target, args);//调用目标对象的某个方法,并且返回目标对象
return object;
}
});
}
}
测试方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
//目标:使用动态代理,对原来的方法进行功能增强,而无需更改原来的代码。
//JDK动态代理:基于接口的(对象的类型,必须实现接口!)
@Test
public void testJdkProxy(){
//target(目标对象)
ICustomerService target = new CustomerServiceImpl();
//实例化注入目标对象
JdkProxyFactory jdkProxyFactory = new JdkProxyFactory(target);
//获取 Object代理对象:基于目标对象类型的接口的类型的子类型的对象
//必需使用接口对象去强转
ICustomerService proxy = (ICustomerService)jdkProxyFactory.getProxyObject();
//调用目标对象的方法
proxy.save();
System.out.println("————————————————————");
proxy.find();
}
输出结果
1
2
3
4
增强代码:写日志了。。。
客户保存了。。。。。
————————————————————
客户查询数量了。。。。。
方式二:Cglib动态代理
CGLIB 动态代理通过生成目标类的子类来完成增强,因此目标对象不必实现接口。Spring 在目标类没有接口,或者显式开启 proxyTargetClass=true 时,通常会采用这种方式。
需要注意的是,final 类无法被继承,final 方法也无法被覆盖,因此这两类场景不适合用基于子类的代理。
1
2
3
4
5
6
7
8
9
10
11
//没有接口的类
public class ProductService {
public void save() {
System.out.println("商品保存了。。。。。");
}
public int find() {
System.out.println("商品查询数量了。。。。。");
return 99;
}
}
使用 cglib 代理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
//cglib动态代理工厂:用来生成cglib代理对象
public class CglibProxyFactory implements MethodInterceptor{
private Object target;
//注入代理对象
public CglibProxyFactory(Object target) {
this.target = target;
}
//获取代理对象
public Object getProxyObject(){
//1.代理对象生成器(工厂思想)
Enhancer enhancer = new Enhancer();
// 类加载器
enhancer.setClassLoader(target.getClass().getClassLoader());
//2.在增强器上设置两个属性
//设置要生成代理对象的目标对象:生成的目标对象类型的子类型
enhancer.setSuperclass(target.getClass());
//设置回调方法
enhancer.setCallback(this);
//3.创建获取对象
return enhancer.create();
}
//回调方法(代理对象的方法)
/**
* 参数1:代理对象
* 参数2:目标对象的方法对象
* 参数3:目标对象的方法的参数的值
* 参数4:代理对象的方法对象
*/
public Object intercept(Object proxy, Method method, Object[] args, MethodProxy methodProxy) throws Throwable {
//如果是保存的方法,执行记录日志操作
if(method.getName().equals("save")){
System.out.println("增强代码:写日志了。。。");
}
//目标对象原来的方法执行
//调用目标对象的某个方法,并且返回目标对象
Object object = method.invoke(target, args);
return object;
}
}
测试方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
//cglib动态代理:可以基于类(无需实现接口)生成代理对象
@Test
public void testCglibProxy(){
//target目标:
ProductService target = new ProductService();
//代理工厂对象,注入目标
CglibProxyFactory cglibProxyFactory = new CglibProxyFactory(target);
//获取proxy
//代理对象,其实是目标对象类型的子类型
ProductService proxy = (ProductService)cglibProxyFactory.getProxyObject();
//调用代理对象的方法
proxy.save();
System.out.println("—————————————————————");
proxy.find();
}
测试结果
1
2
3
4
增强代码:写日志了。。。
商品保存了。。。。。
————————————————————
商品查询数量了。。。。。
Spring 在运行期生成代理对象,不需要额外编译步骤。默认情况下,如果目标对象实现了接口,Spring AOP 更倾向于使用 JDK 动态代理;如果目标对象没有实现接口,或者配置了
proxyTargetClass=true,则会使用 CGLIB。
- 对接口创建代理通常比对类创建代理更松耦合,所以 Spring 默认优先选择 JDK 动态代理
final方法不能被增强,因为基于子类的代理本质上依赖方法重写- Spring AOP 的连接点主要是方法执行,不提供字段级别的拦截
Spring Bean 作用域
常见的 Spring Bean 作用域包括:
singleton:默认作用域,容器中只有一个共享实例prototype:每次获取都会创建一个新的实例request:每次 HTTP 请求创建一个实例,仅在当前请求内有效session:每个 HTTP Session 创建一个实例application:在ServletContext范围内共享一个实例globalSession:仅在 Portlet 环境下有意义,现代 Spring MVC 项目里基本不会使用
其中最常问的是 singleton 和 prototype。singleton 在 IoC 容器中只保留一份,适合无状态 Bean;prototype 每次获取都会新建对象,适合有状态或短生命周期 Bean。
singleton 是 Spring 的默认作用域,可以这样配置:
<bean id="ServiceImpl" class="cn.csdn.service.ServiceImpl" scope="singleton">
@Scope 注解(它可以显示指定 Bean 的作用范围)的方式:
1
2
3
4
5
@Service
@Scope("singleton")
public class ServiceImpl {
}
prototype 示例:
1
2
3
<bean id="account" class="com.foo.DefaultAccount" scope="prototype"/>
或者
<bean id="account" class="com.foo.DefaultAccount" singleton="false"/>
request 和 session 只适用于 Web 应用:
<bean id="loginAction" class="cn.csdn.LoginAction" scope="request"/>
<bean id="userPreferences" class="com.foo.UserPreferences" scope="session"/>
application 示例:
<bean id="appConfig" class="com.foo.AppConfig" scope="application"/>
globalSession 类似标准的 HTTP session,但只在 Portlet Web 应用中有意义:
<bean id="user" class="com.foo.Preferences" scope="globalSession"/>
Spring bean 的生命周期
可以把 Spring Bean 的生命周期概括为下面几个阶段:
- 容器读取 BeanDefinition,确定 Bean 的元数据
- 通过反射或工厂方法实例化 Bean
- 完成属性填充和依赖注入
- 如果实现了
BeanNameAware、BeanClassLoaderAware、BeanFactoryAware、ApplicationContextAware等接口,会回调对应方法 - 执行
BeanPostProcessor#postProcessBeforeInitialization() - 执行初始化逻辑,比如
InitializingBean#afterPropertiesSet()或自定义init-method - 执行
BeanPostProcessor#postProcessAfterInitialization(),AOP 代理通常也发生在这一阶段附近 - Bean 进入可用状态
- 容器关闭时,执行销毁逻辑,比如
DisposableBean#destroy()或自定义destroy-method
-
实例化Bean
对于BeanFactory容器,当客户向容器请求一个尚未初始化的bean时,或初始化bean的时候需要注入,另一个尚未初始化的依赖时,容器就会调用createBean进行实例化。对于ApplicationContext容器,当容器启动结束后,通过获取BeanDefinition对象中的信息,实例化所有的bean
-
设置对象属性(依赖注入)
实例化后的对象被封装在 BeanWrapper 对象中,紧接着,Spring 根据 BeanDefinition 中的信息 以及通过 BeanWrapper 提供的设置属性的接口完成依赖注入
-
处理Aware接口
接着,Spring 会检测该对象是否实现了 xxxAware 接口,并将相关的 xxxAware 实例注入给 Bean,(1)如果这个 Bean 已经实现了 BeanNameAware 接口,会调用它实现的 setBeanName(String beanId)方法,此处传递的就是 Spring 配置文件中 Bean 的 id 值 (2)如果这个 Bean 已经实现了 BeanFactoryAware 接口,会调用它实现的 setBeanFactory() 方法,传递的是 Spring 工厂自身 (3)如果这个 Bean 已经实现了 ApplicationContextAware 接口,会调用 setApplicationContext(ApplicationContext) 方法,传入 Spring 上下文
-
BeanPostProcessor:
BeanPostProcessor通常不是让业务 Bean 自己去实现,而是由容器中的后置处理器 Bean 统一拦截其他 Bean,在初始化前后做增强、包装或检查。 -
InitializingBean 与 init-method
如果 Bean 实现了
InitializingBean,会执行afterPropertiesSet();如果又配置了init-method,对应的初始化方法也会被调用。 -
初始化后的后置处理
所有匹配的
BeanPostProcessor都会在初始化完成后执行postProcessAfterInitialization();如果 Bean 需要被代理,这一步非常关键。
以上几个步骤完成后,Bean就已经被正确创建了,之后就可以使用这个Bean了
-
DisposableBean
当 Bean 不再需要时,会经过清理阶段,如果 Bean 实现了 DisposableBean 这个接口,会调用其实现的 destroy() 方法
-
destroy-method
最后,如果这个 Bean 的 Spring 配置中配置了 destroy-method 属性,会自动调用其配置的销毁方法
多线程输出问题
两个线程交替输出 0-100
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
public class 面试题多线程输出 {
private static volatile int num = 0; // 交替执行,一个输出偶数,一个输出奇数
private static volatile boolean flag = false;
public static void main(String[] args) {
// 交替输出 0-100
Thread_A a = new Thread_A();
Thread_B b = new Thread_B();
a.start();
b.start();
}
/**
* 交替输出 0-100
*/
static class Thread_A extends Thread {
@Override
public void run() {
for (; 100 > num; ) {
if (!flag && (num == 0 || ++num % 2 == 0)) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
}
System.out.println(this.getName() + " " + num);
flag = true;
}
}
}
}
/**
* 交替输出 0-100
*/
static class Thread_B extends Thread {
@Override
public void run() {
for (; 100 > num; ) {
if (flag && (++num % 2 != 0)) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
}
System.out.println(this.getName() + " " + num);
flag = false;
}
}
}
}
}
两个线程输出 A1B2C3…Y25Z26
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
public class 面试题多线程输出 {
static volatile int a = 1;
public static void main(String[] args) {
// 交替输出 数字 和 字母
Thread_C c = new Thread_C();
Thread_D d = new Thread_D();
c.start();
d.start();
}
static class Thread_C extends Thread {
@Override
public void run() {
for (int i = 0; i < 26; i++) {
while (a % 2 == 1) {
try {
Thread.currentThread().interrupt();
} catch (Exception e) {
e.printStackTrace();
}
}
System.out.print(a / 2);
a = a + 1;
}
}
}
static class Thread_D extends Thread {
@Override
public void run() {
for (int i = 0; i < 26; i++) {
while (a % 2 == 0) {
try {
Thread.currentThread().interrupt();
} catch (Exception e) {
e.printStackTrace();
}
}
System.out.print((char) ((a / 2) + 'A'));
a = a + 1;
}
}
}
B+ 树
参考资料 知乎什么是B+树
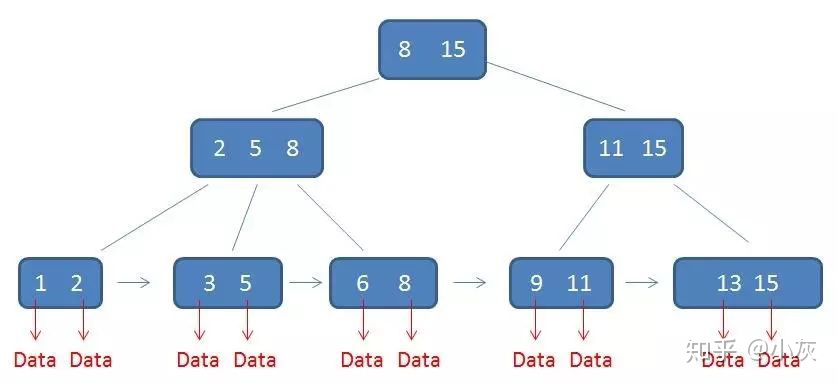
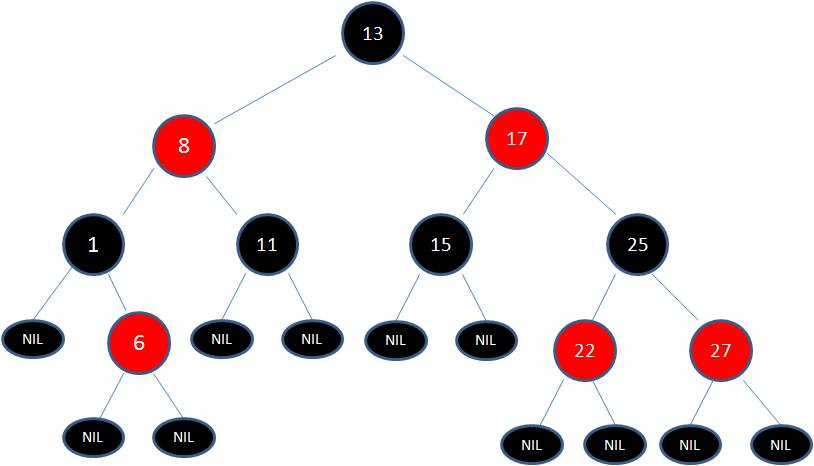
B+ 树是基于 B 树的一种变体,在数据库索引场景里非常常见。不同教材对“节点里有几个关键字、几个孩子”的定义略有差异,本文配图采用的是“父节点保存子节点最大关键字”的画法。
一个 m 阶的 B+ 树具有如下特征:
- 非叶子节点只保存用于导航的关键字,不保存实际数据记录;数据都保存在叶子节点
- 所有叶子节点按关键字大小顺序链接,天然适合范围查询
- 查询最终都会落到叶子节点,所以查询路径更稳定
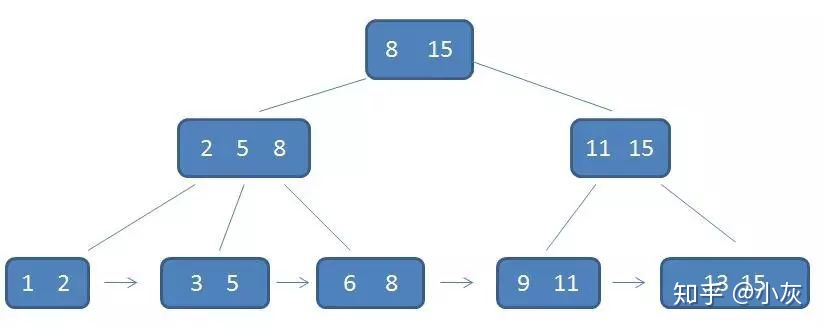
通过图可以看出满足上面所说的第3点特征,每一个父节点的元素都出现在子节点中,是子节点的最大或最小元素
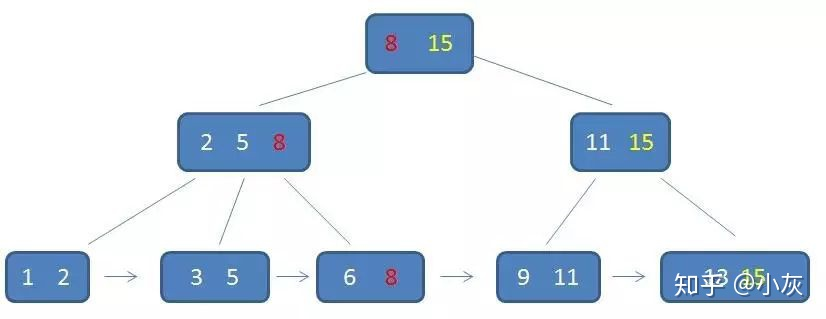
在上面这棵树中,根节点元素 8 是子节点 2,5,8 的最大元素,也是叶子节点 6,8 的最大元素
根节点元素 15 是子节点 11,15 的最大元素,也是叶子节点 13,15 的最大元素
需要注意的是,根节点的最大元素(这里是 15 ),也就等同于整个 B+ 树的最大元素,以后无论插入删除多少元素,始终要保持最大元素在根节点当中
至于叶子节点,由于父节点的元素都出现在子节点中,因此所有子节点包含了全量元素信息
并且每一个叶子节点都带有指向下一个节点的指针,形成了一个有序链表
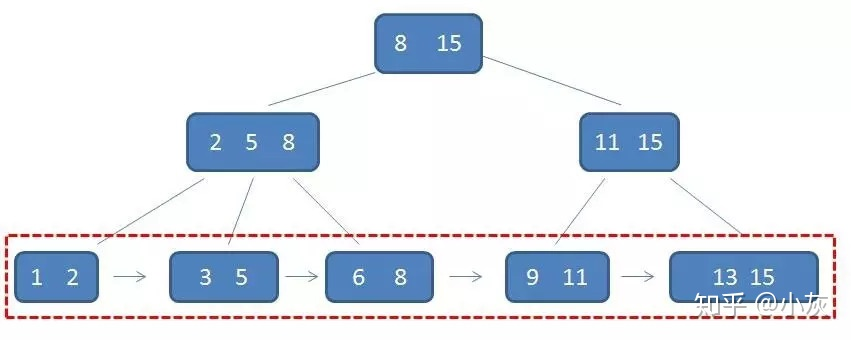
B+ 树还具有一个特点,这个特点是在索引之外,确是至关重要的特点 —— 卫星数据 的位置
卫星数据,指的是索引元素所指向的数据记录,比如数据库中的某一行,在 B- 树中,无论中间节点还是叶子节点都带有卫星数据
B-树中的卫星数据
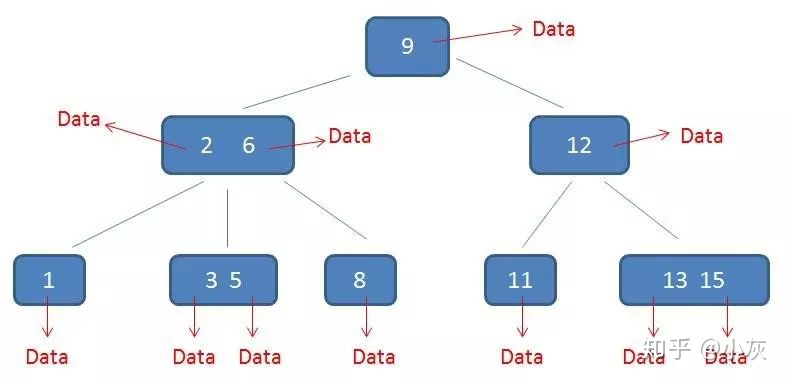
而在 B+ 树当中,只有叶子节点带有卫星数据,其余中间节点仅仅是索引,没有任何数据关联
B+树的卫星数据
在数据库的聚集索引(Clustered Index)中,叶子节点直接包含卫星数据,在非聚集索引(NonClustered Index)中,叶子节点带有指向卫星数据的指针
B+ 树的好处主要体现在查询性能上
分别通过单行查询和范围查询来做分析
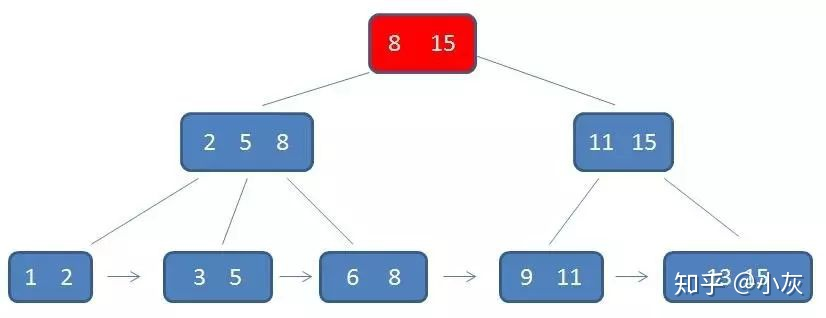
单行查询:
单元素查询的时候,B+ 树会自顶向下逐层查找节点,最终找到匹配的叶子节点,比如现在要查找的是 元素3
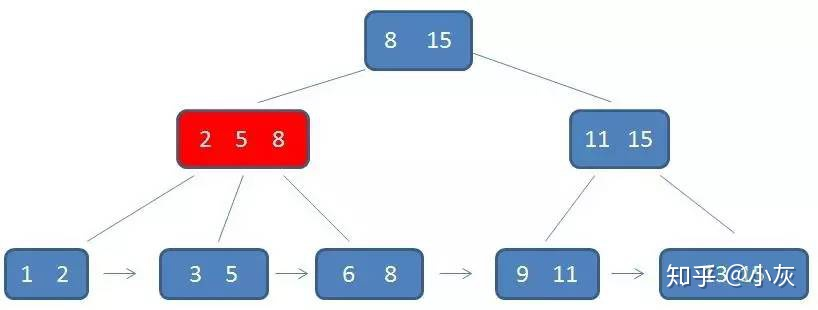
第一次磁盘 IO
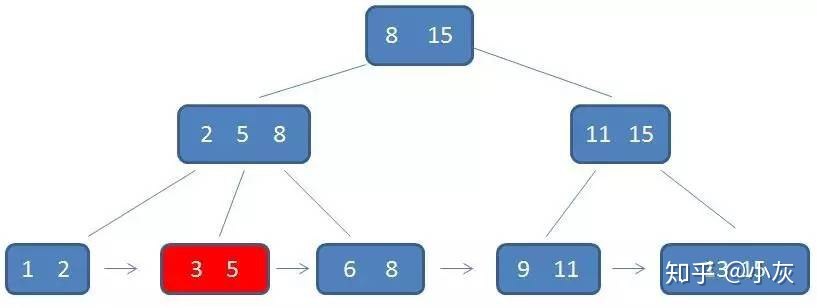
第二次磁盘 IO
第三次磁盘 IO
B+ 树的中间节点没有卫星数据,所以同样大小的磁盘页可以容纳更多的节点元素,数据量相同的情况下,B+ 树的结构比 B- 树更加 矮胖,因此查询时 IO 次数也更少
其次,B+ 树的查询必须最终查找到叶子节点,而 B- 树只要找到匹配元素即可,无论匹配元素处于中间节点还是叶子节点,因此 B- 树的查找性能不稳定(最好情况是只查找根节点,最坏情况是查到叶子节点),而 B+ 树的每一次查找都是稳定的
范围查找:
B+ 树的范围查询,只需要在链表上做遍历即可,比如现在需要查询范围 3 到 11 的元素
自顶向下,查找到范围的下界(3)
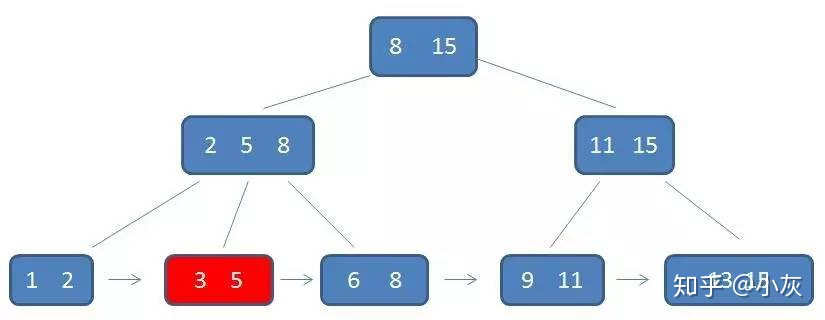
通过链表指针,遍历到元素 6,8
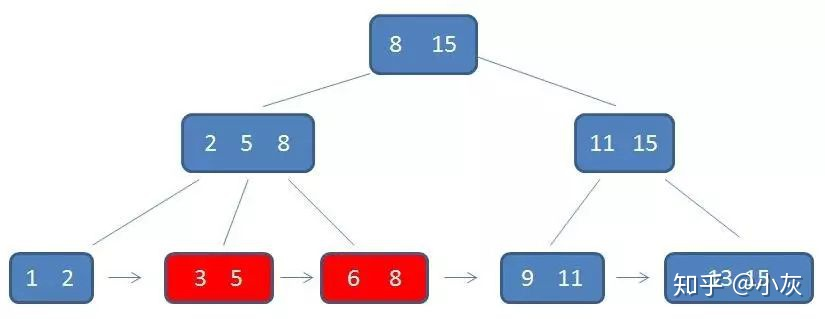
通过链表指针,遍历到元素 9,11,遍历结束
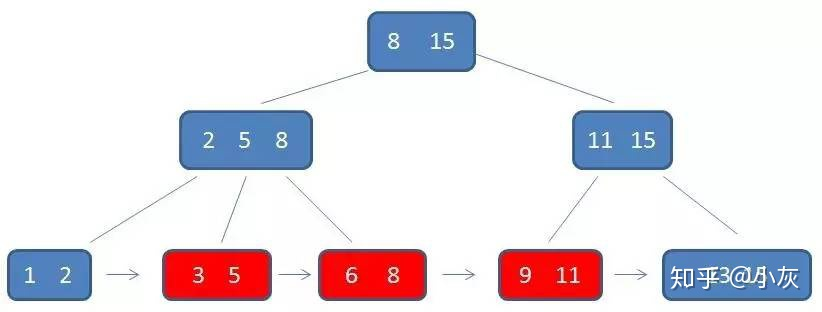
综合起来,B+ 树相比 B- 树的优势有三个:
- IO 次数更少
- 查询性能稳定
- 范围查询简便
B+ 树的插入和删除,过程与 B- 树大同小异
总结 B+ 树的优势:
- 单一节点存储更多的元素,使得查询的 IO 次数更少
- 所有查询都要查找到叶子节点,查询性能稳定
- 所有叶子节点形成有序链表,便于范围查询
B- 树(B 树)
参考资料 知乎什么是B-树
B- 树就是 B 树,不能读成 B减 树
从算法逻辑上来讲,二叉查找树的查找速度和比较次数都是最小的,但是不得不考虑一个问题:磁盘IO
数据库索引是存储在磁盘上的,当数据量比较大的时候,索引的大小可能有几个 G 甚至更多。当我们利用索引查询时,通常不能把整个索引全部加载到内存,能做的只有逐一加载磁盘页,这里的磁盘页对应着索引树的节点。
索引树
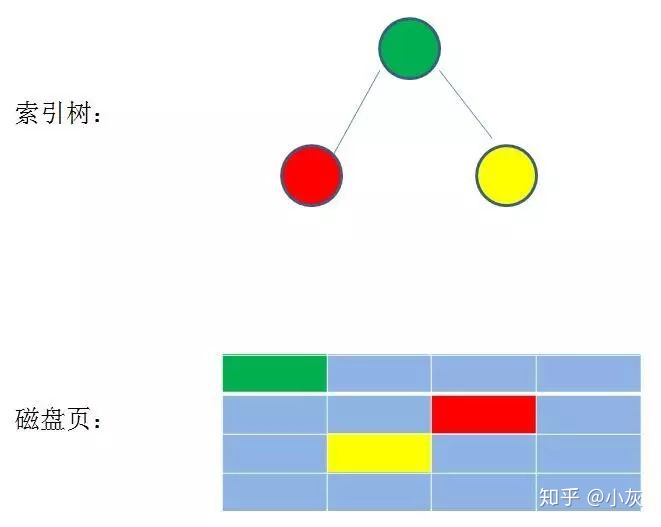
如果使用二叉查找树作为索引结构,假设树的高度是 4 ,查找的值是 10 ,那么流程如下:
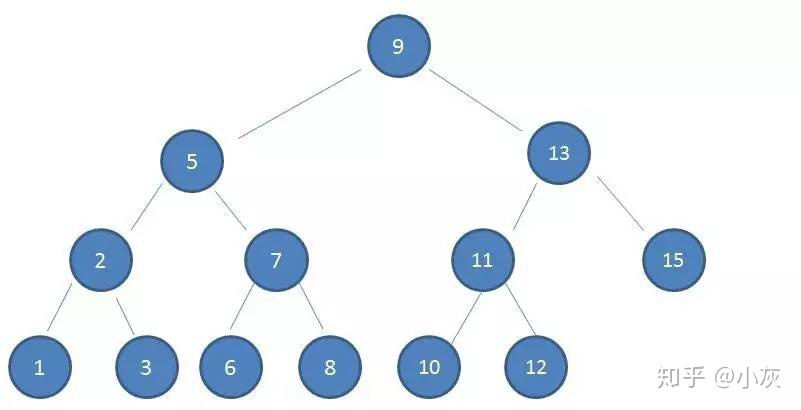
二叉查找树第一次磁盘 IO
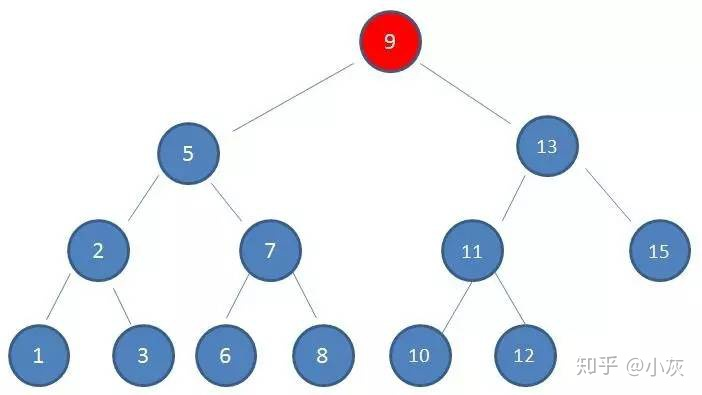
二叉查找树第二次磁盘 IO
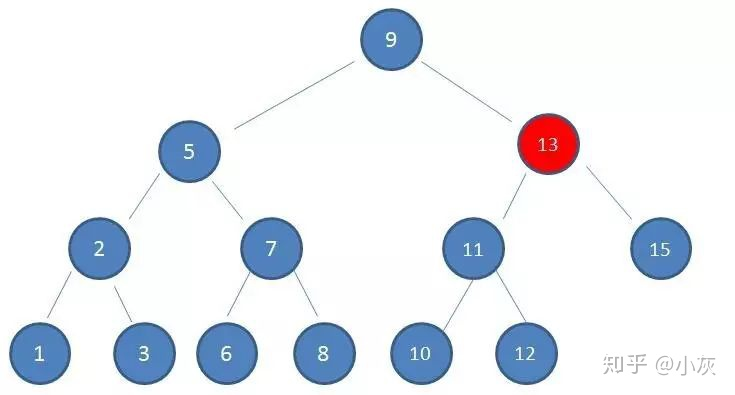
二叉查找树第三次磁盘 IO
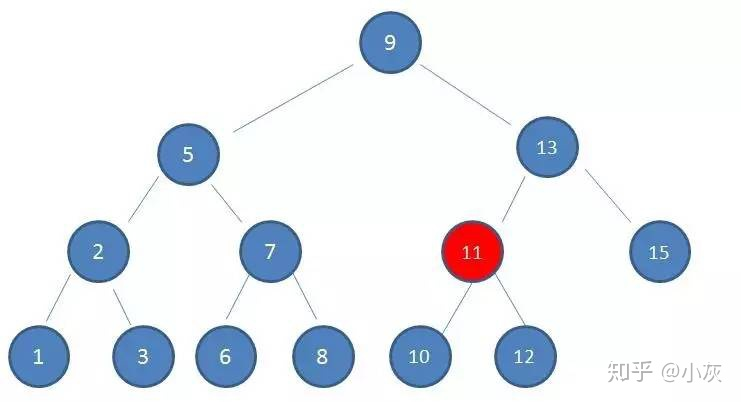
二叉查找树第四次磁盘 IO
使用二叉查找树作为索引结构,磁盘 IO 的次数是 4 次,索引树的高度也是 4 ,所以出现了最坏的情况,磁盘 IO 次数等于索引树的高度,所以为了减少磁盘 IO 次数,需要把原本 瘦高 的树结构变得 矮胖,这是 B- 树的特征之一
B 树是一种多路平衡查找树,它的每一个节点最多包含 K 个孩子,K 被称为 B 树的阶,k 的大小取决于磁盘页的大小
一个 m 阶的 B 树具有如下几个特征:
- 根结点至少有两个子女
- 每个中间节点都包含 k-1 个元素和k个孩子,其中 m/2 <= k <= m
- 每一个叶子节点都包含 k-1 个元素,其中 m/2 <= k <= m
- 所有的叶子结点都位于同一层
- 每个节点中的元素从小到大排列,节点当中 k-1 个元素正好是 k 个孩子包含的元素的值域分划
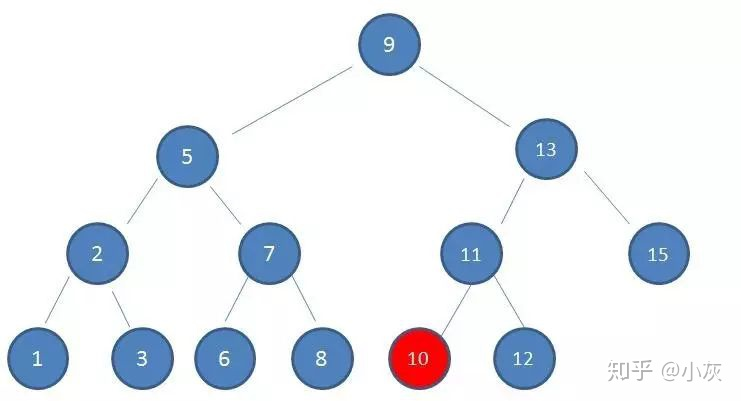
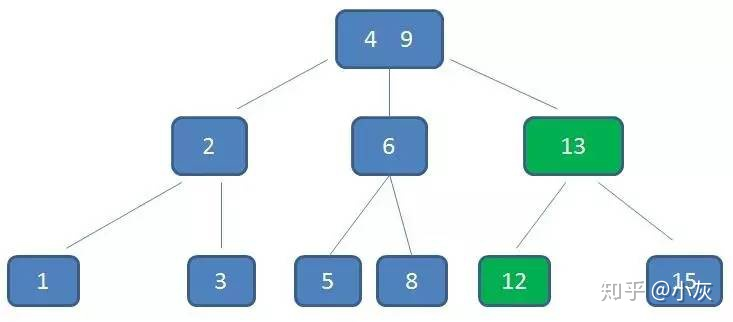
以一个 3 阶 B- 树为例
3 阶 B- 树结构
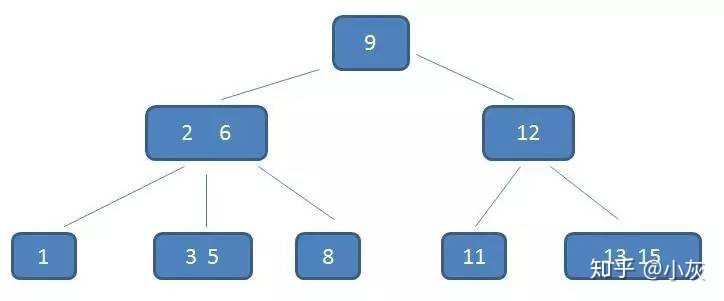
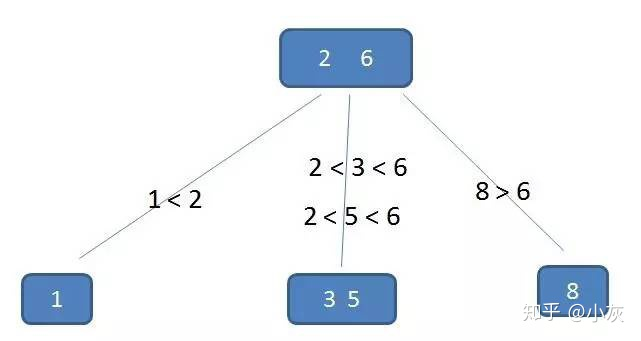
这棵树中,(2,6)节点,该节点有两个元素 2 和 6,又有三个孩子 1,(3,5),8,其中 1 小于元素 2 ,(3,5) 在元素 2,6 之间,8 大于 (3,5),正好符合上述几条特征
B- 树的查询过程,假如现在要查询的数值是 5
第一次磁盘 IO
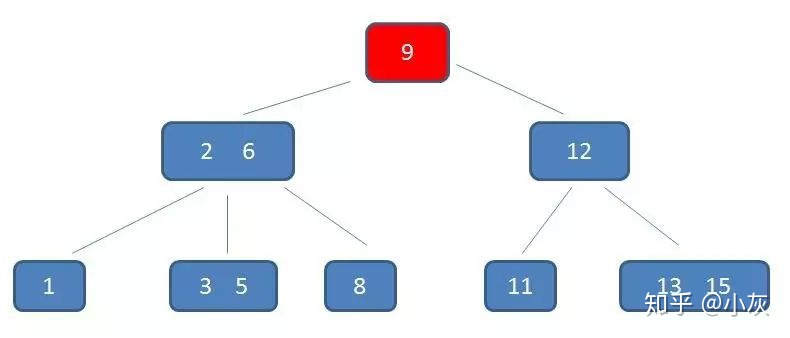
在内存中定位(和9比较)

第二次磁盘 IO
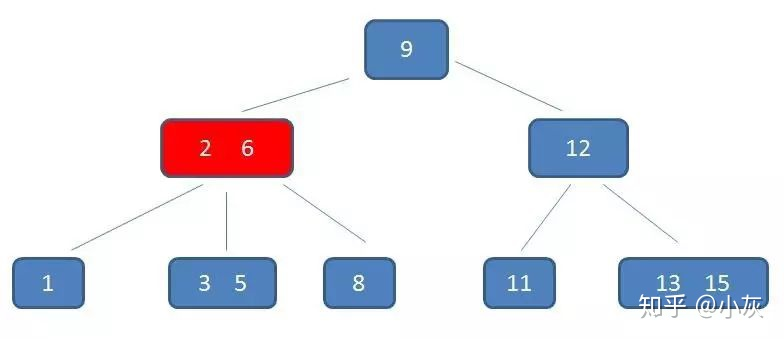
在内存中定位(和2,6比较)
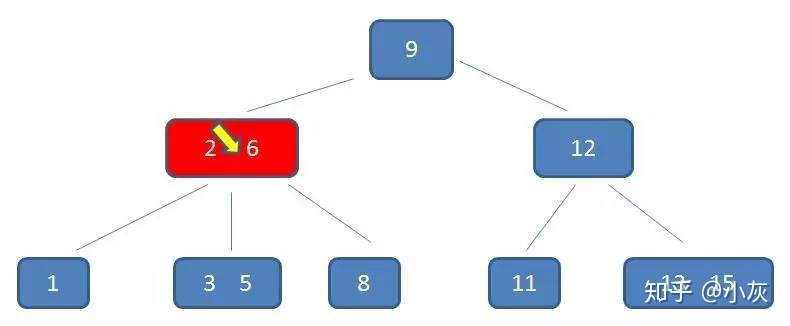
第三次磁盘 IO
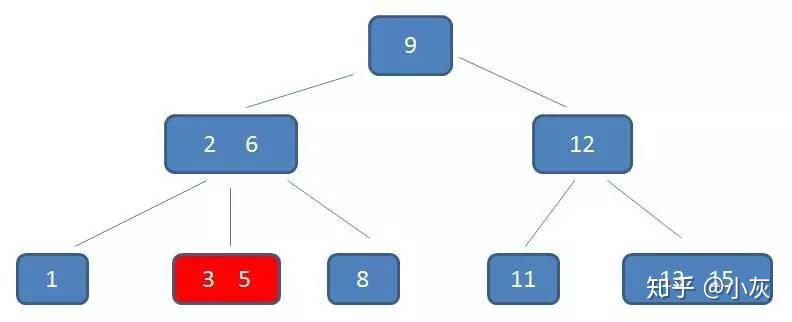
在内存中定位(和3,5比较)
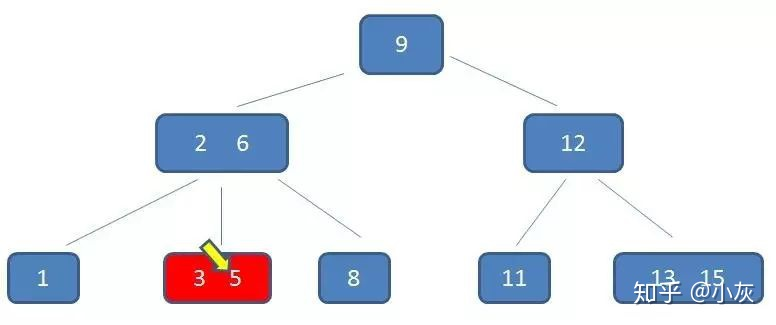
整个流程中可以看出,B- 树在查询中的比较次数其实不比二叉查找树少,尤其当单一节点中的元素数量很多时。可是相比磁盘 IO 的速度,内存中的比较耗时几乎可以忽略,所以只要树的高度足够低,IO 次数足够少,就可以提升查找性能
相比之下节点内部元素多一些也没有关系,仅仅是多了几次内存交互,只要不超过磁盘页的大小即可,这就是 B- 树的优势之一
B- 树插入新节点的过程,比如现在要插入的值是 4
自顶向下查找 4 的节点位置,发现 4 应当插入到节点元素 3,5 之间
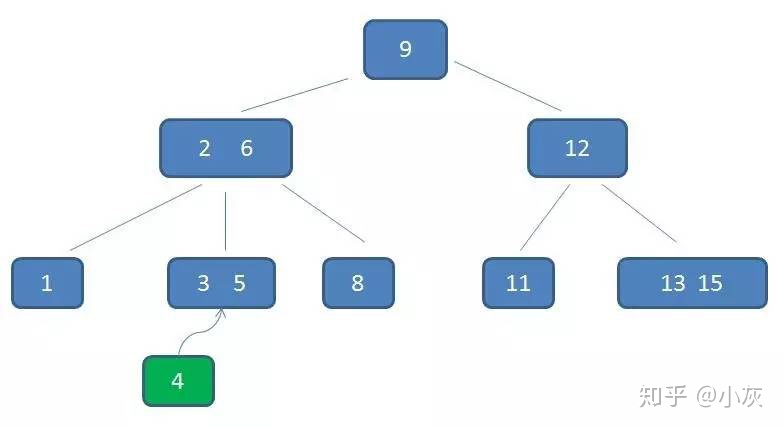
节点 3,5 已经是两元素节点,无法再增加。父亲节点 2, 6 也是两元素节点,也无法再增加。根节点 9 是单元素节点,可以升级为两元素节点。于是拆分节点 3,5 与节点 2,6,让根节点 9 升级为两元素节点4,9。节点 6 独立为根节点的第二个孩子
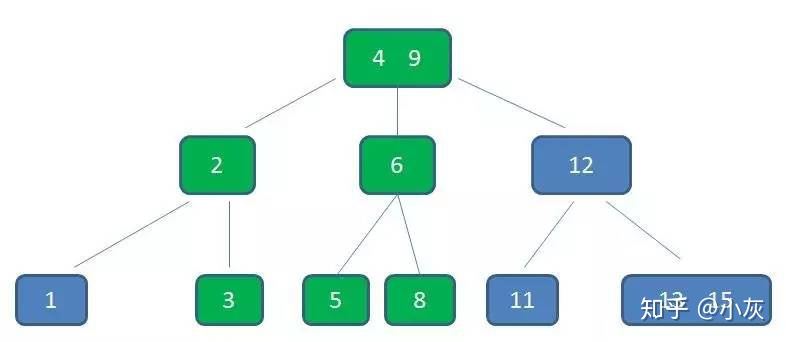
虽然插入的过程会让整个 B 树的相关节点都发生连锁改变,但也正因为如此,B 树才能始终维持多路平衡,这也是 B 树的一大优势:自平衡
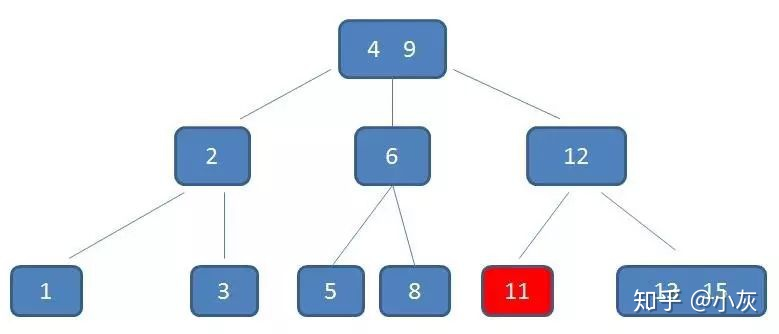
B- 树删除的过程,比如现在要删除元素 11
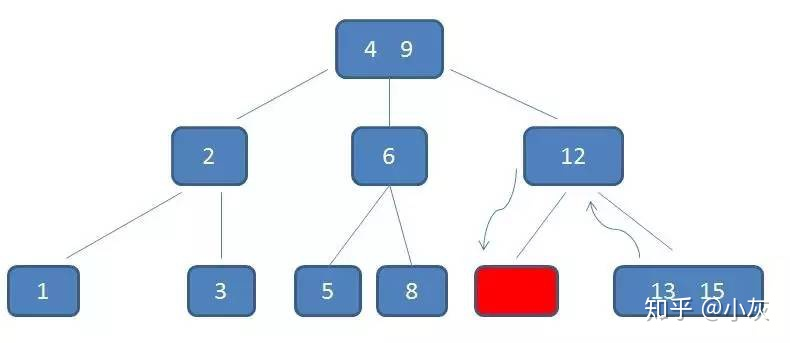
自顶向下查找元素11的节点位置
删除11后,节点12只有一个孩子,不符合B树规范。因此找出12,13,15三个节点的中位数13,取代节点12,而节点12自身下移成为第一个孩子。(这个过程称为左旋)
B- 树主要应用于文件系统以及部分数据库索引,比如非关系型数据库 MongoDB,而大部分关系型数据库,比如 MySql,则使用 B+ 树作为索引
红黑树
参考资料 漫画:什么是红黑树
先回忆下二叉查找树,二叉查找树(BST)特性:
- 左子树上所有结点的值均小于或等于它的根结点的值
- 右子树上所有结点的值均大于或等于它的根结点的值
- 左、右子树也分别为二叉排序树
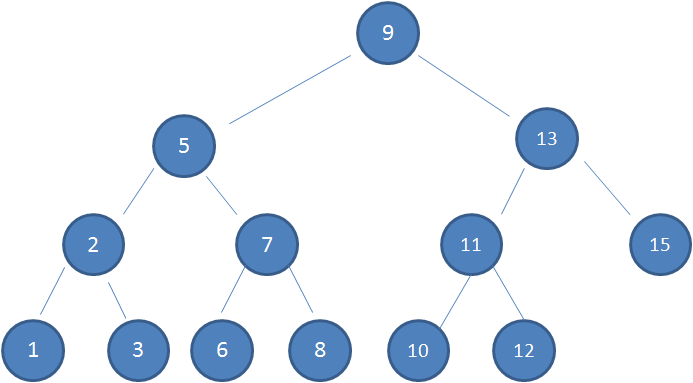
比如需要查找值为 10 的节点
- 查看根节点 9:
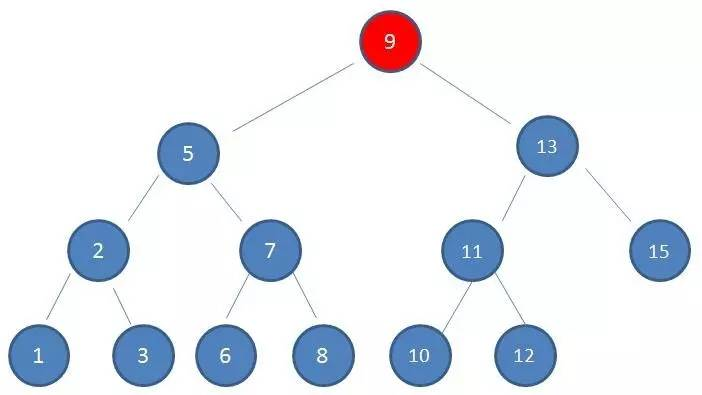
- 由于10 > 9,因此查看右孩子13:
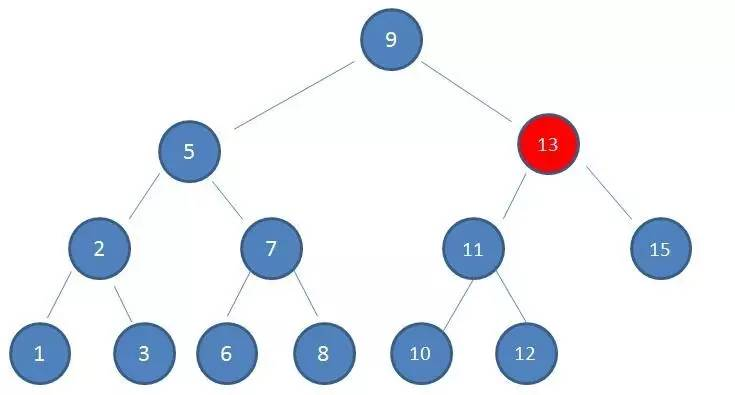
- 由于10 < 13,因此查看左孩子11:
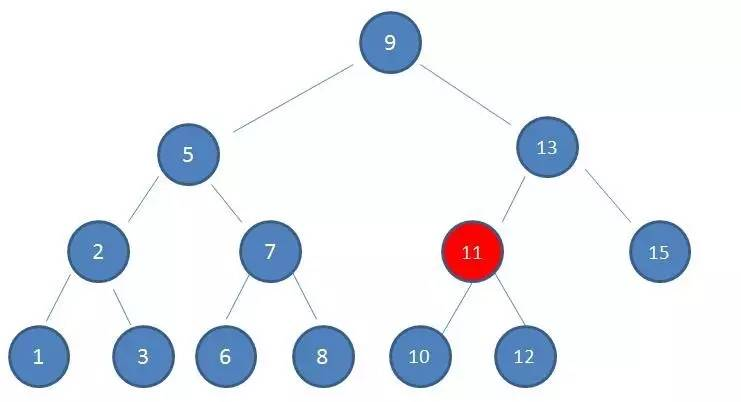
- 由于10 < 11,因此查看左孩子10,发现10正是要查找的节点:
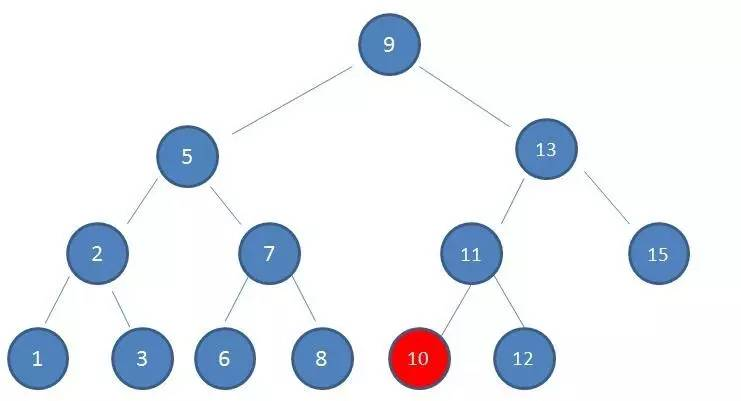
这种方式正是二分查找的思想,查找所需的最大次数等同于二叉查找树的高度
在插入节点的时候也是利用类似的方法,通过一层一层比较大小,找到新节点适合插入的位置
缺陷是导致不平衡
假设初始的二叉查找树只有三个节点,根节点值为9,左孩子值为8,右孩子值为12
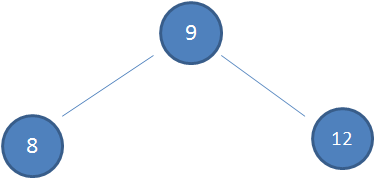
接下来我们依次插入如下五个节点:7,6,5,4,3。依照二叉查找树的特性
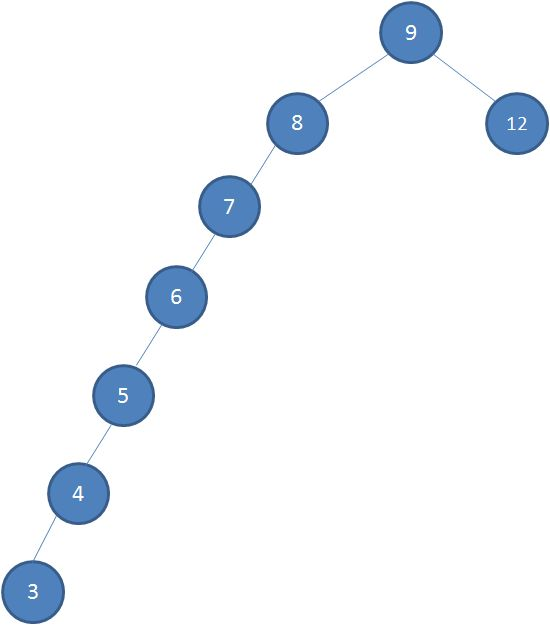
这样的形态虽然也符合二叉查找树的特性,但是查找的性能大打折扣,因此红黑树应运而生
红黑树(Red Black Tree)是一种自平衡的二叉查找树,除了符合二叉查找树的基本特性外,还具有下面这些特性:
- 节点是红色或黑色
- 根节点是黑色
- 每个叶子节点都是黑色的空节点(NIL节点)
- 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点
这些规则,保证了红黑树的自平衡,红黑树从根到叶子的最长路径不会超过最短路径的 2 倍
当插入或删除节点的时候,红黑树的规则有可能被打破,调整的方法:变色 和 旋转(左旋转、右旋转)
插入的新节点为 红色
红黑树的应用:JDK的集合类 TreeMap 和 TreeSet ,Java8 中的 HashMap 等等
数据库事务隔离级别
参考资料 知乎事务隔离级别
- 读未提交(READ UNCOMMITTED): 一个事务还没提交时,它做的变更就能被别的事务看到,可能导致脏读
- 读已提交(READ COMMITTED): 一个事务提交之后,它做的变更才会被其他事务看到,可以避免脏读,但仍然可能出现不可重复读和幻读
- 可重复读(REPEATABLE READ): 一个事务执行过程中,多次读取同一条记录时看到的结果保持一致,可以避免脏读和不可重复读;按 SQL 标准仍然可能出现幻读,不过 MySQL InnoDB 会结合 MVCC 和 next-key lock 尽量减少这类问题
- 串行化(SERIALIZABLE): 隔离级别最高,并发度最低,读写冲突会被严格串行化处理,容易带来更多锁等待和超时
隔离级别解决了哪些问题:
脏读(dirty read): 一个事务读到了另一个未提交事务修改过的数据
为了防止脏读,每次写入前,数据库都会记住旧值,当前事务尚未提交时,其他事务的读取都会拿到旧值,当前事务提交后,其他事务才能读取到新值

不可重复读(non-repeatable read): 在一个事务内两次读到的数据不一样(如果一个事务只能读到另一个已经提交的事务修改过的数据,并且其他事务每对该数据进行一次修改并提交后,该事务都能查询得到最新值)
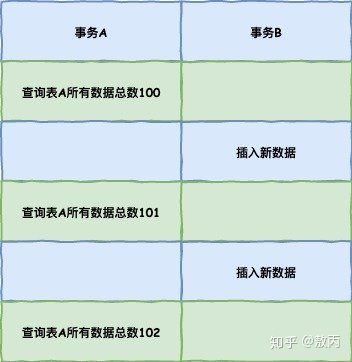
幻读(phantom read): 加入第一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行,同时第二个事务也修改这个表中的数据,插入一行新数据,以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好像发生幻觉一样(如果一个事务先根据某些条件查询出一些记录,之后另一个事务又向表中插入了符合这些条件的记录,原先的事务再次按照该条件查询时,能把另一个事务插入的记录也读出来)
Mysql事务隔离级别:
- 读未提交 READ UNCOMMITTED
- 读已提交 READ COMMITTED
- 可重复读 REPEATABLE READ
- 串行化 SERIALIZABLE
submit 和 execute 的区别
线程池里这两个方法都很常见,但面试里最好把“返回值”和“异常处理”分开回答:
execute(Runnable command)只接收Runnable,没有返回值,提交后拿不到任务结果submit()可以接收Runnable或Callable,返回Future,可以通过get()拿到结果或异常submit()不会把任务异常直接抛回调用方线程,异常会被封装到Future里,通常在调用get()时暴露execute()也不会同步抛回到提交任务的线程;任务运行时抛出的异常,通常会交给工作线程的UncaughtExceptionHandler处理
如果面试官继续追问,一般可以补一句:需要关心任务结果、任务状态或异常回传时,用 submit() 更合适;只想“扔出去执行”时,用 execute() 就够了。
ThreadLocal
ThreadLocal 的作用主要是做数据隔离,填充的数据只属于当前线程,变量的数据对别的线程而言是相对隔离的,在多线程环境下,如何防止自己的变量被其它线程篡改
Spring 实现事务隔离级别的源码中有使用到 ThreadLocal
Spring 采用 ThreadLocal 的方式,来保证单个线程中的数据库操作使用的是同一个数据库连接。同时,业务层在使用事务时不需要显式管理 Connection 对象,框架会通过传播行为、资源绑定和拦截器链完成事务协作。TransactionSynchronizationManager 就是这类实现的核心类之一:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
public abstract class TransactionSynchronizationManager {
private static final Log logger = LogFactory.getLog(TransactionSynchronizationManager.class);
private static final ThreadLocal<Map<Object, Object>> resources =
new NamedThreadLocal<Map<Object, Object>>("Transactional resources");
private static final ThreadLocal<Set<TransactionSynchronization>> synchronizations =
new NamedThreadLocal<Set<TransactionSynchronization>>("Transaction synchronizations");
private static final ThreadLocal<String> currentTransactionName =
new NamedThreadLocal<String>("Current transaction name");
private static final ThreadLocal<Boolean> currentTransactionReadOnly =
new NamedThreadLocal<Boolean>("Current transaction read-only status");
private static final ThreadLocal<Integer> currentTransactionIsolationLevel =
new NamedThreadLocal<Integer>("Current transaction isolation level");
private static final ThreadLocal<Boolean> actualTransactionActive =
new NamedThreadLocal<Boolean>("Actual transaction active");
...
...
}
Spring 事务不是“只靠 ThreadLocal 和 AOP”就能完成的,事务管理器、连接绑定、传播行为和回滚规则同样重要;
ThreadLocal主要负责把资源绑定到当前线程。
自己写的案例,在使用拦截器的时候,为了获取上下文的用户信息,使用了 ThreadLocal
1
2
3
4
5
6
7
8
9
10
11
public class UserThreadLocal {
private static ThreadLocal<User> userHolder = new ThreadLocal<User>();
public static void setUser(User user) {
userHolder.set(user);
}
public static User getUser() {
return userHolder.get();
}
}
这类写法在实际项目里一定要在请求结束后调用
remove(),否则在线程池复用工作线程时很容易残留上一次请求的上下文数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
@Service
public class AccessInterceptor extends HandlerInterceptorAdapter {
@Autowired
UserService userService;
@Autowired
RedisService redisService;
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
if (handler instanceof HandlerMethod) {
User user = getUser(request, response);
UserThreadLocal.setUser(user);
HandlerMethod handlerMethod = (HandlerMethod) handler;
AccessLimit accessLimit = handlerMethod.getMethodAnnotation(AccessLimit.class);
if (accessLimit == null) {
return true;
}
...
...
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
@Service
public class UserArgumentResolver implements HandlerMethodArgumentResolver {
public Object resolveArgument(MethodParameter parameter, ModelAndViewContainer mavContainer, NativeWebRequest webRequest, WebDataBinderFactory binderFactory) throws Exception {
// 获取LoginInterceptor设置到request中的用户信息,注入到参数中
User user = (User) webRequest.getAttribute("currentUser", RequestAttributes.SCOPE_REQUEST);
if (user != null) {
return user;
} else {
user = UserThreadLocal.getUser();
if (user != null) {
return user;
}
}
throw new GlobalException(CodeMsg.SESSION_ERROR);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
@Configuration
public class WebMvcConfig extends WebMvcConfigurerAdapter {
@Autowired
UserArgumentResolver userArgumentResolver;
@Autowired
AccessInterceptor accessInterceptor;
/**
* 往Controller的参数中赋值
*
* @param argumentResolvers
*/
@Override
public void addArgumentResolvers(List<HandlerMethodArgumentResolver> argumentResolvers) {
argumentResolvers.add(userArgumentResolver);
}
/**
* 将校验登录User是否为空的拦截器添加进来
*
* @param registry
*/
@Override
public void addInterceptors(InterceptorRegistry registry) {
// 加入的顺序就是执行的顺序
registry.addInterceptor(loginInterceptor).addPathPatterns("/**");
registry.addInterceptor(accessInterceptor);
super.addInterceptors(registry);
}
}
ThreadLocal set 方法源码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class.
*/
ThreadLocal.ThreadLocalMap threadLocals = null;
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
ThreadLocalMap 需要重点关注一下,而 ThreadLocalMap 是从当前线程 Thread 的 threadLocals 变量中获取的。
每个线程 Thread 都维护了自己的 threadLocals 变量,所以在每个线程创建 ThreadLocal 的时候,实际上数据是存在自己线程 Thread 的 threadLocals 变量里面的,别人没办法拿到,从而实现了隔离
ThreadLocalMap 作为内部类,其实并没有实现 Map 接口,而且它的 Entry 继承了 WeakReference(弱引用)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
static class ThreadLocalMap {
/**
* The entries in this hash map extend WeakReference, using
* its main ref field as the key (which is always a
* ThreadLocal object). Note that null keys (i.e. entry.get()
* == null) mean that the key is no longer referenced, so the
* entry can be expunged from table. Such entries are referred to
* as "stale entries" in the code that follows.
*/
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
/**
* The initial capacity -- MUST be a power of two.
*/
private static final int INITIAL_CAPACITY = 16;
/**
* The table, resized as necessary.
* table.length MUST always be a power of two.
*/
private Entry[] table;
用数组是因为一个线程里可以有多个 ThreadLocal 存放不同类型的对象,它们最终都会进入当前线程自己的 ThreadLocalMap。
ThreadMap 的 set 方法,解决 Hash 冲突
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
private void set(ThreadLocal<?> key, Object value) {
// We don't use a fast path as with get() because it is at
// least as common to use set() to create new entries as
// it is to replace existing ones, in which case, a fast
// path would fail more often than not.
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
ThreadLocalMap 在存储的时候会给每一个 ThreadLocal 对象一个 threadLocalHashCode ,在插入过程中,根据 ThreadLocal 对象的 hash 值,定位到 table 中的位置 i,int i = key.threadLocalHashCode & (len-1)
然后会判断一下:如果当前位置是空的,就初始化一个 Entry 对象放在位置 i 上
1
2
3
4
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
如果位置i不为空,并且这个 Entry 对象的 key 正好是即将设置的 key,那么就刷新 Entry 中的 value
1
2
3
4
if (k == key) {
e.value = value;
return;
}
如果位置 i 的不为空,而且 key 不等于 entry,那就找下一个空位置,直到为空为止
set 和 get 如果冲突严重的话,效率还是很低的
共享线程的 ThreadLocal 数据,使用 InheritableThreadLocal实例
1
final ThreadLocal threadLocal = new InheritableThreadLocal();
InheritableThreadLocal只适合父线程直接创建子线程的场景,并不适合线程池复用线程的场景;在线程池里传递上下文,更稳妥的做法通常是显式传参或使用专门的上下文传递方案。
ThreadLocal 内存泄漏问题
ThreadLocal 在保存的时候会把自己当做 key 存在 ThreadLocalMap 中,且现在 key 被设计成 WeakReference 弱引用(垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存)
这就导致了一个问题,ThreadLocal 在没有外部强引用时,发生 GC 时会被回收,如果创建ThreadLocal 的线程一直持续运行,那么这个 Entry 对象中的 value 就有可能一直得不到回收,发生内存泄露
就比如线程池里面的线程,线程都是复用的,那么之前的线程实例处理完之后,出于复用的目的线程依然存活,所以,ThreadLocal 设定的 value 值被持有,导致内存泄露
内存泄漏解决方案
在代码的最后使用 remove ,只要记得在 使用的最后 用 remove 把值清空就好了
1
2
3
4
5
6
7
ThreadLocal<String> localName = new ThreadLocal();
try {
localName.set("张三");
……
} finally {
localName.remove();
}
一个接口多个实现类的 Spring 注入方式
1
2
3
public interface Interface1 {
void fun();
}
以下是接口的两个实现类,注意 @Service 注解里显式指定了 Bean 名称,后面注入时就可以按名称区分:
1
2
3
4
5
6
7
@Service("s1")
public class Interface1Impl1 implements Interface1 {
@Override
public void fun() {
System.out.println("接口1实现类1 ...");
}
}
1
2
3
4
5
6
7
@Service("s2")
public class Interface1Impl2 implements Interface1 {
@Override
public void fun() {
System.out.println("接口1实现类2 ...");
}
}
注入方式:
- 通过
@Autowired和@Qualifier配合注入
1
2
3
@Autowired
@Qualifier("s1")
private Interface1 interface1;
- 使用
@Resource,根据 Bean 名称注入
1
2
@Resource(name = "s1")
private Interface1 interface1;
- 在一个实现类上标记
@Primary,再直接@Autowired
1
2
3
4
5
6
7
8
9
10
11
@Service
@Primary
public class Interface1Impl1 implements Interface1 {
@Override
public void fun() {
System.out.println("默认实现");
}
}
@Autowired
private Interface1 interface1;
Java 基础高频题补充
-
==和equals()的区别==比较的是两个变量保存的地址值;如果是基本类型,比较的是字面值本身。equals()是对象语义比较,默认继承自Object时仍然是地址比较,很多类例如String会重写它来比较内容。 -
hashCode()和equals()的关系如果两个对象通过
equals()判断相等,那么它们的hashCode()必须相同;反过来hashCode()相同,不代表equals()一定相等。这是HashMap、HashSet等哈希容器的基础约定。 -
HashMap和ConcurrentHashMap的区别HashMap线程不安全,适合单线程场景;ConcurrentHashMap线程安全,JDK 8 以后主要通过数组、链表、红黑树加上 CAS 与同步控制来保证并发性能。面试里常见追问是:为什么Hashtable性能更差,因为它基本是整表级别的同步。 -
volatile和synchronized的区别volatile主要保证可见性和一定程度的有序性,不能保证复合操作的原子性;synchronized既能保证可见性,也能保证临界区代码的原子性,还能提供互斥访问。 -
ArrayList和LinkedList的区别ArrayList底层是动态数组,随机访问快,尾部追加效率高;LinkedList底层是双向链表,插入删除某个已定位节点时更方便,但随机访问慢,而且额外指针带来的内存开销更大。 -
final、finally、finalize()final用来修饰类、方法、变量,表示不可继承、不可重写或不可再次赋值;finally是异常处理的一部分,通常用于资源释放;finalize()是Object的旧方法,已经不推荐依赖,也不应该用于资源管理。
Spring MVC 流程
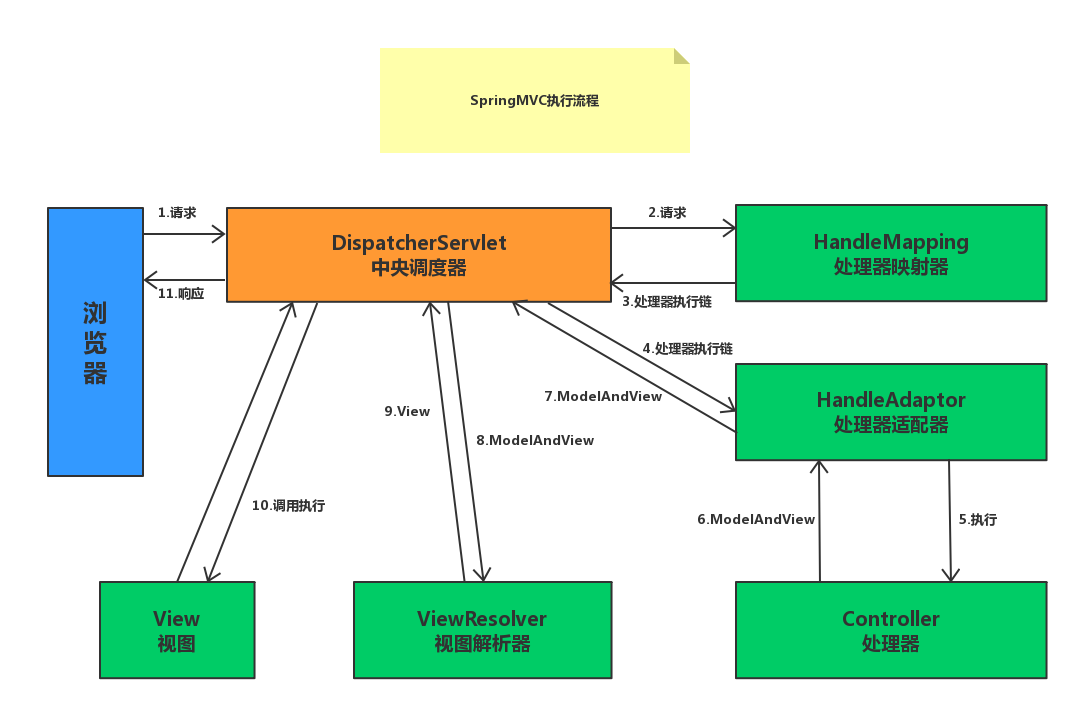
- 用户发送请求到前端控制器 DispatcherServlet
- DispatcherServlet 收到请求调用处理映射器 HandlerMapping
- 处理器映射器找到具体的处理器(可以根据 xml 配置、注解进行查找),生成处理器对象及处理器拦截器一并返回给 DispatcherServlet
- DispatcherServlet 调用 HandlerAdapter 处理器适配器
- HandlerAdapter 经过适配调用具体的处理器( Controller )
- Controller 执行完成返回 ModelAndView
- HandlerAdapter 将 Controller 执行结果 ModelAndView 返回给 DispatcherServlet
- DispatcherServlet 将 ModelAndView 传给 ViewResolver 视图解析器
- ViewResolver 解析后返回具体 View
- DispatcherServlet 根据 View 进行渲染视图(即将模型数据填充至视图中)
- DispatcherServlet 响应用户