[TOC]
什么是 I/O
在计算机系统中 I/O 就是输入(Input)和输出(Output)的意思,针对不同的操作对象,可以划分为磁盘 I/O 模型,网络 I/O 模型,内存映射 I/O , Direct I/O、数据库 I/O 等,只要具有输入输出类型的交互系统都可以认为是 I/O 系统,也可以说 I/O 是整个操作系统数据交换与人机交互的通道,这个概念与选用的开发语言没有关系,是一个通用的概念
在如今的系统中 I/O 却拥有很重要的位置,现在系统都有可能处理大量文件,大量数据库操作,而这些操作都依赖于系统的 I/O 性能,也就造成了现在系统的瓶颈往往都是由于 I/O 性能造成的
因此,为了解决磁盘 I/O 性能慢的问题,系统架构中添加了缓存来提高响应速度;或者有些高端服务器从硬件级入手,使用了固态硬盘(SSD)来替换传统机械硬盘;在大数据方面,Spark 越来越多的承担了实时性计算任务,而传统的 Hadoop 体系则大多应用在了离线计算与大量数据存储的场景,这也是由于磁盘 I/O 性能远不如内存 I/O 性能而造成的格局(Spark更多的使用了内存,而 MapReduece 更多的使用了磁盘)。因此,一个系统的优化空间,往往都在低效率的 I/O 环节上,很少看到一个系统 CPU、内存的性能是其整个系统的瓶颈。也正因为如此,Java 在 I/O 上也一直在做持续的优化,从JDK 1.4 开始便引入了 NIO 模型,大大的提高了以往 BIO 模型下的操作效率
进程中的IO调用步骤大致可以分为以下四步:
- 进程向操作系统请求数据
- 操作系统把外部数据加载到内核的缓冲区中
- 操作系统把内核的缓冲区拷贝到进程的缓冲区
- 进程获得数据完成自己的功能
当操作系统在把外部数据放到进程缓冲区的这段时间(即上述的第二,三步),如果应用进程是挂起等待的,那么就是同步 IO,反之,就是异步 IO,也就是 AIO
同步和异步
同步:
两个同步任务相互依赖,并且一个任务必须以依赖于另一任务的某种方式执行。 比如在A->B事件模型中,你需要先完成 A 才能执行B。 再换句话说,同步调用中被调用者未处理完请求之前,调用不返回,调用者会一直等待结果的返回
所谓同步,指的是协同步调。既然叫协同,所以至少要有2个以上的事物存在。协同的结果就是多个事物不能同时进行,必须一个一个的来,上一个事物结束后,下一个事物才开始
那当一个事物正在进行时,其它事物都在干嘛呢?
严格来讲这个并没有要求,但一般都是处于一种“等待”的状态,因为通常后面事物的正常进行都需要依赖前面事物的结果或前面事物正在使用的资源
因此,可以认为,同步更希望关注的是从宏观整体来看,多个事物是一种逐个逐个的串行化关系,绝对不会出现交叉的情况
所以,自然也不太会去关注某个瞬间某个具体事物是处于一个什么状态
比如排队买火车票这件事:
其实售票大厅更在意的是旅客一个一个的到窗口去买票,因为一次只能卖一张票
即使大家一窝蜂的都围上去,还是一次只能卖一张票,排队这种形式来即一个一个的买票
至于每个旅客排队时的状态,是看手机还是说话或者干其他,根本不用去关注
除了这种由于资源导致的同步外,还存在一种由于逻辑上的先后顺序导致的同步
比如先更新代码,然后再编译,接着再打包。这些操作由于后一步要使用上一步的结果,所以只能按照这种顺序一个一个的执行
关于同步还需知道两个小的点:
- 范围,并不需要在全局范围内都去同步,只需要在某些关键的点执行同步即可
比如食堂只有一个卖饭窗口,肯定是同步的,一个人买完,下一个人再买。但吃饭的时候不是一个人吃完下一个才能吃
- 粒度,并不是只有大粒度的事物才有同步,小粒度的事物也有同步
只不过小粒度的事物同步通常是天然支持的,而大粒度的事物同步往往需要手工处理
比如两个线程的同步就需要手工处理,但一个线程里的两个语句天然就是同步的
异步:
两个异步的任务完全独立的,一方的执行不需要等待另外一方的执行。再换句话说,异步调用中一调用就返回结果,不需要等待结果返回,当结果返回的时候通过回调函数或者其他方式拿着结果再做相关事情
所谓异步,就是步调各异。既然是各异,那就是都不相同。所以结果就是:
多个事物可以你进行你的、我进行我的,谁都不用管谁,所有的事物都在同时进行中
一言以蔽之,同步就是多个事物不能同时开工,异步就是多个事物可以同时开工
一定要去体会“多个事物”,多个线程是多个事物,多个方法是多个事物,多个语句是多个事物,多个CPU指令是多个事物。等等等等
阻塞和非阻塞
阻塞:
阻塞就是发起一个请求,调用者一直等待请求结果返回,也就是当前线程会被挂起,无法从事其他任务,只有当条件就绪才能继续
所谓阻塞,指的是阻碍堵塞。它的本意可以理解为由于遇到了障碍而造成的动弹不得
非阻塞:
非阻塞就是发起一个请求,调用者不用一直等着结果返回,可以先去干其他事情
所谓非阻塞,自然是和阻塞相对,可以理解为由于没有遇到障碍而继续畅通无阻
比如堵车:
汽车可以正常通行时,就是非阻塞。一旦堵上了,一动不动,就是阻塞
因此阻塞关注的是不能动,非阻塞关注的是可以动
不能动的结果就是只能等待,可以动的结果就是继续前行
因此和阻塞搭配的词一定是等待,和非阻塞搭配的词一定是进行
阻塞和等待:
等待只是阻塞的一个副作用而已,表明随着时间的流逝,没有任何有意义的事物发生或进行
阻塞的真正含义是你关心的事物由于某些原因无法继续进行,因此让你等待。但没必要干等,你可以做一些其它无关的事物,因为这并不影响你对相关事物的等待
在堵车时,可以干等,也可以玩手机、和别人聊天,或者打牌、甚至先去吃饭都行。因为这些事物并不影响你对堵车的等待。不过你的车必须呆在原地
在计算机里,是没有人这么灵活的,一般在阻塞时,选在干等,因为这最容易实现,只需要挂起线程,让出 CPU 即可。在条件满足时,会重新调度该线程
阻塞/非阻塞 和 同步/异步 两两组合
所谓同步/异步,关注的是能不能同时开工
所谓阻塞/非阻塞,关注的是能不能动,能不能继续执行
通过推理进行组合:
同步阻塞: 不能同时开工,也不能动。只有一条小道,一次只能过一辆车,可悲的是还堵上了
同步非阻塞: 不能同时开工,但可以动。只有一条小道,一次只能过一辆车,幸运的是可以正常通行
异步阻塞: 可以同时开工,但不可以动。有多条路,每条路都可以跑车,可气的是全都堵上了
异步非阻塞: 可以工时开工,也可以动。有多条路,每条路都可以跑车,很爽的是全都可以正常通行
其实它们的关注点是不同的,只要搞明白了这点,组合起来比较好理解
回到程序里,把它们和线程关联起来:
- 同步阻塞,相当于一个线程在等待
- 同步非阻塞,相当于一个线程在正常运行
- 异步阻塞,相当于多个线程都在等待
- 异步非阻塞,相当于多个线程都在正常运行
BIO、NIO、AIO 基本定义
BIO (Blocking I/O): 同步阻塞 I/O 模式,数据的读取写入必须阻塞在一个线程内等待其完成。这里使用那个经典的烧开水例子,这里假设一个烧开水的场景,有一排水壶在烧开水,BIO 的工作模式就是,叫一个线程停留在一个水壶那,直到这个水壶烧开,才去处理下一个水壶。但是实际上线程在等待水壶烧开的时间段什么都没有做
NIO (New I/O): 同时支持阻塞与非阻塞模式,但这里我们以其同步非阻塞 I/O 模式来说明,那么什么叫做同步非阻塞?如果还拿烧开水来说,NIO 的做法是叫一个线程不断的轮询每个水壶的状态,看看是否有水壶的状态发生了改变,从而进行下一步的操作
AIO ( Asynchronous I/O): 异步非阻塞 I/O 模型。异步非阻塞与同步非阻塞的区别在哪里?异步非阻塞无需一个线程去轮询所有 I/O 操作的状态改变,在相应的状态改变后,系统会通知对应的线程来处理。对应到烧开水中就是,为每个水壶上面装了一个开关,水烧开之后,水壶会自动通知我水烧开了
BIO(Blocking I/O)同步阻塞I/O
这是最基本与简单的 I/O 操作方式,其根本特性是做完一件事再去做另一件事,一件事一定要等前一件事做完,这很符合程序员传统的顺序来开发思想,因此 BIO 模型程序开发起来较为简单,易于把握。
但是 BIO 如果需要同时做很多事情(例如同时读很多文件,处理很多tcp请求等),就需要系统创建很多线程来完成对应的工作
因为 BIO 模型下一个线程同时只能做一个工作,如果线程在执行过程中依赖于需要等待的资源,那么该线程会长期处于阻塞状态,我们知道在整个操作系统中,线程是系统执行的基本单位,在 BIO 模型下的线程阻塞就会导致系统线程的切换,从而对整个系统性能造成一定的影响
当然如果我们只需要创建少量可控的线程,那么采用 BIO 模型也是很好的选择,但如果在需要考虑高并发的 web 或者 tcp 服务器中采用BIO 模型就无法应对了,如果系统开辟成千上万的线程,那么 CPU 的执行时机都会浪费在线程的切换中,使得线程的执行效率大大降低
此外,关于线程这里说一句题外话,在系统开发中线程的生命周期一定要准确控制,在需要一定规模并发的情形下,尽量使用线程池来确保线程创建数目在一个合理的范围之内,切莫编写线程数量创建上限的代码
NIO (New I/O) 同步非阻塞I/O
关于 NIO,国内有很多技术博客将英文翻译成 No-Blocking I/O,非阻塞I/O模型 ,当然这样就与 BIO 形成了鲜明的特性对比
NIO 本身是基于事件驱动的思想来实现的,其目的就是解决 BIO 的大并发问题,在BIO模型中,如果需要并发处理多个 I/O 请求,那就需要多线程来支持
NIO 使用了多路复用器机制,以 socket 使用来说,多路复用器通过不断轮询各个连接的状态,只有在 socket 有流可读或者可写时,应用程序才需要去处理它,在线程的使用上,不需要一个连接就必须使用一个处理线程了,而是只是有效请求时(确实需要进行 I/O 处理时),才会使用一个线程去处理,这样就避免了 BIO 模型下大量线程处于阻塞等待状态的情景
相对于 BIO 的流,NIO 抽象出了新的通道(Channel)作为输入输出的通道,并且提供了缓存(Buffer)的支持,在进行读操作时,需要使用 Buffer 分配空间,然后将数据从 Channel 中读入 Buffer 中,对于 Channel 的写操作,也需要现将数据写入 Buffer,然后将 Buffer 写入 Channel 中
如下是NIO方式进行文件拷贝操作的示例,见下图:
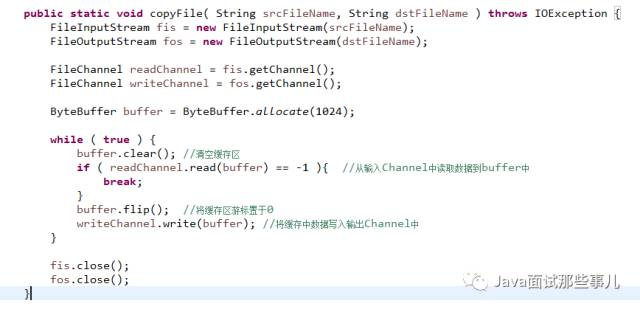
通过比较 New IO 的使用方式可以发现,新的 IO 操作不再面向 Stream 来进行操作了,改为了通道 Channel,并且使用了更加灵活的缓存区类 Buffer,Buffer 只是缓存区定义接口, 根据需要,我们可以选择对应类型的缓存区实现类。在 java NIO 编程中,我们需要理解以下 3 个对象 Channel、Buffer和Selector:
Channel:
国内大多翻译成“通道”。Channel 和 IO 中的 Stream(流) 是差不多一个等级的。只不过 Stream 是单向的,譬如:InputStream, OutputStream。而 Channel 是双向的,既可以用来进行读操作,又可以用来进行写操作,NIO 中的 Channel 的主要实现有:FileChannel、DatagramChannel、SocketChannel、ServerSocketChannel;通过看名字就可以猜出个所以然来:分别可以对应文件 IO、UDP 和 TCP( Server 和 Client )
Buffer:
NIO 中的关键 Buffer 实现有:ByteBuffer、CharBuffer、DoubleBuffer、 FloatBuffer、IntBuffer、 LongBuffer,、ShortBuffer,分别对应基本数据类型: byte、char、double、 float、int、 long、 short。当然 NIO 中还有MappedByteBuffer, HeapByteBuffer, DirectByteBuffer 等这里先不具体陈述其用法细节
Selector:
Selector 是 NIO 相对于 BIO 实现多路复用的基础,Selector 运行单线程处理多个 Channel,如果你的应用打开了多个通道,但每个连接的流量都很低,使用 Selector 就会很方便。例如在一个聊天服务器中。要使用 Selector , 得向 Selector 注册 Channel,然后调用它的 select() 方法。这个方法会一直阻塞到某个注册的通道有事件就绪。一旦这个方法返回,线程就可以处理这些事件,事件的例子有如新的连接进来、数据接收等
补充DirectByteBuffer 与 HeapByteBuffer 的区别:
ByteBuffer 分配内存的两种方式:
-
HeapByteBuffer 其内存空间在 JVM 的 heap(堆)上分配,可以看做是 jdk 对于 byte[] 数组的封装
-
DirectByteBuffer 则直接利用了系统接口进行内存申请,其内存分配在c heap 中,这样就减少了内存之间的拷贝操作,如此一来,在使用 DirectByteBuffer 时,系统就可以直接从内存将数据写入到 Channel 中,而无需进行 Java 堆的内存申请,复制等操作,提高了性能
为什么不直接使用 DirectByteBuffer,还要来个 HeapByteBuffer?
原因在于 DirectByteBuffer 是通过 full gc 来回收内存的,DirectByteBuffer 会自己检测情况而调用 system.gc(),但是如果参数中使用了 DisableExplicitGC 那么就无法回收该快内存了,-XX:+DisableExplicitGC 标志自动将 System.gc() 调用转换成一个空操作,就是应用中调用 System.gc() 会变成一个空操作,那么如果设置了就需要我们手动来回收内存了
所以DirectByteBuffer使用起来相对于完全托管于 java 内存管理的Heap ByteBuffer 来说更复杂一些,如果用不好可能会引起OOM。Direct ByteBuffer 的内存大小受 -XX:MaxDirectMemorySize JVM 参数控制(默认大小64M),在 DirectByteBuffer 申请内存空间达到该设置大小后,会触发 Full GC
这里再来看一个 NIO 模型下的 TCP 服务器的实现,通过代码可以看到 Selector 正是 NIO 模型下 TCP Server 实现 IO 复用的关键,请仔细理解下段代码 while 循环中的逻辑,见下图:

AIO (Asynchronous I/O) 异步非阻塞I/O
Java AIO 就是 Java 作为对异步 IO 提供支持的 NIO.2 ,Java NIO2 (JSR 203)定义了更多的 New I/O APIs, 提案 2003 提出,直到 2011 年才发布, 最终在JDK 7中才实现。JSR 203 除了提供更多的文件系统操作API(包括可插拔的自定义的文件系统), 还提供了对 socket 和文件的异步 I/O操作。 同时实现了JSR-51提案中的 socket channel 全部功能,包括对绑定, option 配置的支持以及多播 multicast 的实现
从编程模式上来看 AIO 相对于 NIO 的区别在于,NIO需要使用者线程不停的轮询 IO 对象,来确定是否有数据准备好可以读了,而 AIO 则是在数据准备好之后,才会通知数据使用者,这样使用者就不需要不停地轮询了。当然 AIO 的异步特性并不是 Java 实现的伪异步,而是使用了系统底层 API 的支持,在 Unix 系统下,采用了 epoll IO 模型,而 windows 便是使用了 IOCP 模型。可以参考 Netty 在高并发下使用 AIO 的相关技术
阻塞IO和非阻塞IO
应用程序都是运行在用户空间的,所以它们能操作的数据也都在用户空间。按照这样子来理解,只要数据没有到达用户空间,用户线程就操作不了
如果此时用户线程已经参与,那它一定会被阻塞在 IO 上。这就是常说的阻塞IO。用户线程被阻塞在等待数据上或拷贝数据上
非阻塞IO 就是用户线程不参与以上两个过程(等待数据、拷贝数据),即数据已经拷贝到用户空间后,才去通知用户线程,一上来就可以直接操作数据了
用户线程没有因为 IO 的事情出现阻塞,这就是常说的非阻塞IO
同步IO和同步阻塞IO
按照对同步的理解,同步IO 是指发起 IO 请求后,必须拿到 IO 的数据才可以继续执行
按照程序的表现形式又分为两种:
- 在等待数据的过程中,和拷贝数据的过程中,线程都在阻塞,这就是同步阻塞IO
- 在等待数据的过程中,线程采用死循环式轮询,在拷贝数据的过程中,线程在阻塞,这其实还是同步阻塞IO
很多文章把第二种归为同步非阻塞IO,这肯定是错误的,它一定是阻塞IO,因为拷贝数据的过程,线程是阻塞的
严格来讲,在IO的概念上,同步和非阻塞是不可能搭配的,因为它们是一对相悖的概念
同步IO 意味着必须拿到 IO 的数据,才可以继续执行。因为后续操作依赖IO数据,所以它必须是阻塞的
非阻塞IO 意味着发起 IO 请求后,可以继续往下执行。说明后续执行不依赖于 IO 数据,所以它肯定不是同步的
因此,在IO上,同步和非阻塞是互斥的,所以不存在同步非阻塞IO。但同步非阻塞是存在的,那不叫IO,叫操作数据了
所以,同步IO一定是阻塞IO,同步IO也就是同步阻塞IO
异步IO和异步阻塞/非阻塞IO
按照对异步的理解,异步IO 是指发起 IO 请求后,不用拿到IO的数据就可以继续执行
用户线程的继续执行,和操作系统准备 IO 数据的过程是同时进行的,因此才叫做异步IO
按照IO数据的两个过程,又可以分为两种:
- 在等待数据的过程中,用户线程继续执行,在拷贝数据的过程中,线程在阻塞,这就是异步阻塞IO
- 在等待数据的过程中,和拷贝数据的过程中,用户线程都在继续执行,这就是异步非阻塞IO
第一种情况是,用户线程没有参与数据等待的过程,所以它是异步的。但用户线程参与了数据拷贝的过程,所以它又是阻塞的。合起来就是异步阻塞IO
第二种情况是,用户线程既没有参与等待过程也没有参与拷贝过程,所以它是异步的。当它接到通知时,数据已经准备好了,它没有因为IO数据而阻塞过,所以它又是非阻塞的。合起来就是异步非阻塞IO
多路复用
IO 多路复用 (I/O multiplexing),IO 多路复用是一种同步 IO 模型,实现一个线程可以监视多个文件句柄;一旦某个文件句柄就绪,就能够通知应用程序进行相应的读写操作;没有文件句柄就绪时会阻塞应用程序,交出cpu。多路是指网络连接,复用指的是同一个线程

I/O multiplexing 这里面的 multiplexing 指的其实是在单个线程通过记录跟踪每一个Sock(I/O流)的状态(对应空管塔里面的Fight progress strip槽)来同时管理多个I/O流
发明它的原因,是尽量多的提高服务器的吞吐能力
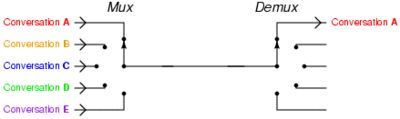
在同一个线程里面,通过拨开关的方式,来同时传输多个I/O流
IO 多路复用解决的问题:
应用程序通常需要处理来自多条事件流中的事件,比如现在用的电脑,需要同时处理键盘鼠标的输入、中断信号等等事件,再比如 web 服务器如 nginx,需要同时处理来来自 N 个客户端的事件(ngnix 会有很多链接进来, epoll 会把他们都监视起来,然后像拨开关一样,谁有数据就拨向谁,然后调用相应的代码处理)
而 CPU 单核在同一时刻只能做一件事情,一种解决办法是对 CPU 进行时分复用(多个事件流将 CPU 切割成多个时间片,不同事件流的时间片交替进行)。在计算机系统中,用线程或者进程来表示一条执行流,通过不同的线程或进程在操作系统内部的调度,来做到对 CPU 处理的时分复用。这样多个事件流就可以并发进行,不需要一个等待另一个太久,在用户看起来他们似乎就是并行在做一样
但凡事都是有成本的。线程/进程也一样,有这么几个方面:
- 线程/进程创建成本
- CPU切换不同线程/进程成本 Context Switch
- 多线程的资源竞争
IO 多路复用可以在单线程/进程中处理多个事件流,因此 IO 多路复用解决的本质问题是在用更少的资源完成更多的事
IO多路复用的三种实现方式:select、poll、epoll
select 是第一个实现 (1983 左右在 BSD 里面实现):
select 被实现以后,很快就暴露出了很多问题:
- select 会修改传入的参数数组,这个对于一个需要调用很多次的函数,是非常不友好的
- select 如果任何一个 sock (I/O stream)出现了数据,select 仅仅会返回,但是并不会告诉你是那个 sock 上有数据,于是你只能自己一个一个的找,十几个 sock 可能还好,要是几万的sock每次都找一遍,这个无谓的开销就颇有海天盛筵的豪气了
- select 只能监视 1024 个链接,linux 定义在头文件中的,参见 FD_SETSIZE
- select 不是线程安全的,如果你把一个 sock 加入到 select, 然后突然另外一个线程发现这个 sock 不用,要收回,这个select 不支持的,如果关掉这个 sock, select 的标准行为是不可预测的
14年以后(1997年)其他人实现了 poll, poll 修复了 select 的很多问题:
- poll 去掉了1024个链接的限制
- poll 从设计上来说,不再修改传入数组
但是 poll 仍然不是线程安全的, 这就意味着,不管服务器有多强悍,也只能在一个线程里面处理一组 I/O 流。当然可以那多进程来配合了,不过然后就会有了多进程的各种问题
5年以后, 在2002, Davide Libenzi 实现了epoll:
epoll 可以说是I/O 多路复用最新的一个实现,epoll 修复了poll 和select绝大部分问题, 比如:
- epoll 现在是线程安全的
- epoll 现在不仅告诉你 sock 组里面数据,还会告诉你具体哪个 sock 有数据,不用自己去找
epoll 有个致命的缺点即只有 linux 支持