本篇文章主要是常见问题的整理,在第二篇中会更详细深入了解 Redis
参考资料 JavaGuide、蛙课网、三太子敖丙、为什么Redis选择单线程模型、Redis命令总结、github优质文章、redis在线练习、redis三种模式配置
[TOC]
缓存的基本思想
大多数对缓存的理解即可以提高系统性能以及减少请求响应时间
缓存的基本思想是:空间换时间
比如 CPU Cache 缓存的是内存数据,用于解决 CPU 处理速度和内存不匹配的问题
内存缓存的是硬盘数据,用于解决硬盘访问速度过慢的问题
操作系统在 页表方案 基础之上引入了 快表(转换检测缓冲区) 来加速虚拟地址到物理地址的转换,我们可以把快表理解为一种特殊的高速缓冲存储器(Cache)
缓存总结: 为了避免用户在请求数据的时候获取速度过于缓慢,所以在数据库之上增加了缓存这一层来弥补
使用缓存为系统带来了什么问题
针对分布式缓存:
- 系统复杂性增加: 引入缓存之后,需要维护缓存和数据库的数据一致性、维护热点缓存等等
- 系统开发成本往往会增加: 引入缓存意味着系统需要一个单独的缓存服务,这是需要花费相应的成本的,并且这个成本还是很贵的,毕竟耗费的是宝贵的内存。但是,如果你只是简单的使用一下本地缓存存储一下简单的数据,并且数据量不大的话,那么就不需要单独去弄一个缓存服务
本地缓存解决方案:
本地缓存实际在很多项目中用的挺多,特别是单体架构的时候。数据量不大,并且没有分布式要求的话,使用本地缓存还是可以的
常见的单体架构图如下,使用 Nginx 来做负载均衡,部署两个相同的服务到服务器,两个服务使用同一个数据库,并且使用的是本地缓存
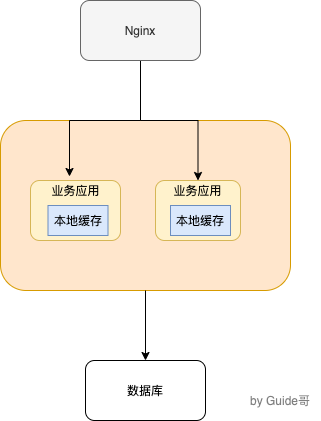
那本地缓存的方案有:
-
JDK 自带的 HashMap 和 ConcurrentHashMap
ConcurrentHashMap 可以看作是线程安全版本的 HashMap ,两者都是存放 key/value 形式的键值对。但是,大部分场景来说不会使用这两者当做缓存,因为只提供了缓存的功能,并没有提供其他诸如过期时间之类的功能。一个稍微完善一点的缓存框架至少要提供:过期时间、淘汰机制、命中率统计这三点
-
Ehcache 、 Guava Cache 、 Spring Cache 这三者是使用的比较多的本地缓存框架
Ehcache 相比于其他两者更加重量。不过,相比于 Guava Cache 、 Spring Cache 来说, Ehcache 支持可以嵌入到 hibernate 和 mybatis 作为多级缓存,并且可以将缓存的数据持久化到本地磁盘中、同时也提供了集群方案(比较鸡肋,可忽略)
Guava Cache 和 Spring Cache 两者比较像
Guava 相比于 Spring Cache 的话使用的更多一点,它提供了 API 非常方便我们使用,同时也提供了设置缓存有效时间等功能。它的内部实现也比较干净,很多地方都和 ConcurrentHashMap 的思想有异曲同工之妙。
使用 Spring Cache 的注解实现缓存的话,代码会看着很干净和优雅,但是很容易出现问题比如缓存穿透、内存溢出
-
Caffeine
相比于 Guava 来说 Caffeine 在各个方面比如性能要更加优秀,一般建议使用其来替代 Guava 。并且, Guava 和 Caffeine 的使用方式很像
为什么要有分布式缓存而不直接用本地缓存
可以把分布式缓存(Distributed Cache) 看作是一种内存数据库的服务,它的最终作用就是提供缓存数据的服务
如下图所示,就是一个简单的使用分布式缓存的架构图。使用 Nginx 来做负载均衡,部署两个相同的服务到服务器,两个服务使用同一个数据库和缓存
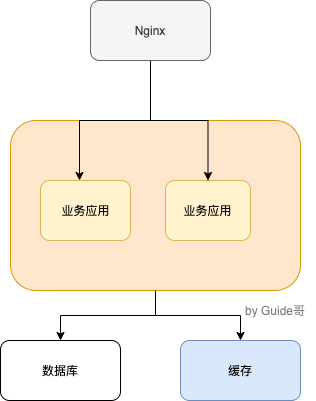
本地的缓存的优势是低依赖,比较轻量并且通常相比于使用分布式缓存要更加简单
再来分析一下本地缓存的局限性:
-
本地缓存对分布式架构支持不友好,比如同一个相同的服务部署在多台机器上的时候,各个服务之间的缓存是无法共享的,因为本地缓存只在当前机器上有
-
本地缓存容量受服务部署所在的机器限制明显。 如果当前系统服务所耗费的内存多,那么本地缓存可用的容量就很少
使用分布式缓存之后,缓存部署在一台单独的服务器上,即使同一个相同的服务部署在再多机器上,也是使用的同一份缓存。 并且,单独的分布式缓存服务的性能、容量和提供的功能都要更加强大
使用分布式缓存的缺点呢,也很显而易见,那就是你需要为分布式缓存引入额外的服务比如 Redis 或 Memcached,你需要单独保证 Redis 或 Memcached 服务的高可用
缓存读写模式/更新策略
Cache Aside Pattern(旁路缓存模式)
- 写: 更新 DB,然后直接删除 cache
- 读: 从 cache 中读取数据,读取到就直接返回,读取不到的话,就从 DB 中取数据返回,然后(客户端)再把数据放到 cache 中
Cache Aside Pattern 中服务端需要同时维系 DB 和 cache,并且是以 DB 的结果为准
另外,Cache Aside Pattern 有首次请求数据一定不在 cache 的问题,对于热点数据可以提前放入缓存中
Cache Aside Pattern 是我们平时使用比较多的一个缓存读写模式,比较适合读请求比较多的场景
Read/Write Through Pattern(读写穿透模式)
Read/Write Through 套路是:服务端把 cache 视为主要数据存储,从中读取数据并将数据写入其中。cache 服务负责将此数据读取和写入 DB,从而减轻了应用程序的职责
- 写(Write Through): 先查 cache,cache 中不存在,直接更新 DB。 cache 中存在,则先更新 cache,然后 cache 服务自己更新 DB(同步更新 cache 和 DB)
- 读(Read Through): 从 cache 中读取数据,读取到就直接返回 。读取不到的话,先从 DB 加载,写入到 cache 后返回响应
Read-Through Pattern 实际只是在 Cache-Aside Pattern (旁路缓存模式)之上进行了封装
在 Cache-Aside Pattern (旁路缓存模式)下,发生读请求的时候,如果 cache 中不存在对应的数据,是由客户端自己负责把数据写入 cache,而 Read Through Pattern (读写穿透模式)则是 cache 服务自己来写入缓存的,这对客户端是透明的
和 Cache Aside Pattern 一样, Read-Through Pattern 也有首次请求数据一定不在 cache 的问题,对于热点数据可以提前放入缓存中
Write Behind Pattern(异步缓存写入)
Write Behind Pattern (异步缓存写入)和 Read/Write Through Pattern (读写穿透模式)很相似,两者都是由 cache 服务来负责 cache 和 DB 的读写。
但是,两个又有很大的不同:
- Read/Write Through (读写穿透模式)是同步更新 cache 和 DB
- Write Behind Caching (异步缓存写入)则是只更新缓存,不直接更新 DB,而是改为异步批量的方式来更新 DB
Write Behind Pattern (异步缓存写入)下 DB 的写性能非常高,尤其适合一些数据经常变化的业务场景比如说一篇文章的点赞数量、阅读数量。 往常一篇文章被点赞 500 次的话,需要重复修改 500 次 DB,但是在 Write Behind Pattern 下可能只需要修改一次 DB 就可以了。
但是,这种模式同样也给 DB 和 Cache 一致性带来了新的考验,很多时候如果数据还没异步更新到 DB 的话,Cache 服务宕机就 gg 了
Redis 简介
Redis 就是一个使用 C 语言开发的一个开源的(遵从BSD协议)高性能键值对(key-value)的内存数据库,不过与传统数据库不同的是 Redis 的数据是存在内存中的,也就是它是内存数据库,所以读写速度非常快,因此 Redis 被广泛应用于缓存方向
Redis 除了做缓存之外,Redis 也经常用来做分布式锁,甚至是消息队列
Redis作为一个内存数据库:
- 性能优秀,数据在内存中,读写速度非常快,支持并发10W QPS
- 单进程单线程,是线程安全的,采用IO多路复用机制
- 丰富的数据类型,支持字符串(strings)、散列(hashes)、列表(lists)、集合(sets)、有序集合(sorted sets)等
- 支持数据持久化。可以将内存中数据保存在磁盘中,重启时加载
- 主从复制,哨兵,高可用
- 可以用作分布式锁
- 可以作为消息中间件使用,支持发布订阅 … …
Redis 和 Memcached
分布式缓存使用的比较多的主要是 Memcached 和 Redis。不过,现在基本没有看过还有项目使用 Memcached 来做缓存,都是直接用 Redis
Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来,随着 Redis 的发展,大家慢慢都转而使用更加强大的 Redis 了
分布式缓存主要解决的是单机缓存的容量受服务器限制并且无法保存通用的信息。因为,本地缓存只在当前服务里有效,比如如果部署了两个相同的服务,他们两者之间的缓存数据是无法通用的
Memcache 的代码层类似 Hash,特点如下:
- 支持简单数据类型
- 不支持数据持久化存储
- 不支持主从
- 不支持分片
Redis 特点如下:
- 数据类型丰富
- 支持数据磁盘持久化存储
- 支持主从
- 支持分片
两者的共同点和区别
共同点:
- 都是基于内存的数据库,一般都用来当做缓存使用
- 都有过期策略
- 两者的性能都非常高
区别:
- Redis 支持更丰富的数据类型(支持更复杂的应用场景)。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。Memcached 只支持最简单的 k/v 数据类型
- Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memecache 把数据全部存在内存之中
- Redis 有灾难恢复机制。 因为可以把缓存中的数据持久化到磁盘上
- Redis 在服务器内存使用完之后,可以将不用的数据放到磁盘上。但是,Memcached 在服务器内存使用完之后,就会直接报异常
- Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 Redis 目前是原生支持 cluster 集群模式的
- Memcached 是多线程,非阻塞 IO 复用的网络模型;Redis 使用单线程的多路 IO 复用模型。 (Redis 6.0 引入了多线程 IO )
- Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持。并且,Redis 支持更多的编程语言
- Memcached 过期数据的删除策略只用了惰性删除,而 Redis 同时使用了惰性删除与定期删除
为什么 Redis 能这么快
Redis 的效率很高,官方给出的数据是 100000+QPS,这是因为:
-
Redis 完全基于内存,绝大部分请求是纯粹的内存操作,执行效率高。
-
Redis 使用单进程单线程模型的(K,V)数据库,将数据存储在内存中,存取均不会受到硬盘 IO 的限制,因此其执行速度极快。另外单线程也能处理高并发请求,还可以避免频繁上下文切换和锁的竞争,如果想要多核运行也可以启动多个实例
-
数据结构简单,对数据操作也简单,Redis 不使用表,不会强制用户对各个关系进行关联,不会有复杂的关系限制,其存储结构就是键值对,类似于 HashMap,HashMap 最大的优点就是存取的时间复杂度为 O(1)
-
Redis 使用多路 I/O 复用模型,为非阻塞 IO
Redis 采用的 I/O 多路复用函数:epoll/kqueue/evport/select
为什么Redis是单线程
Redis 官方很敷衍就随便给了一点解释。不过基本要点也都说了,因为 Redis 的瓶颈不是 cpu 的运行速度,而往往是网络带宽和机器的内存大小。再说了,单线程切换开销小,容易实现既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了
缓存数据的处理流程是怎样的
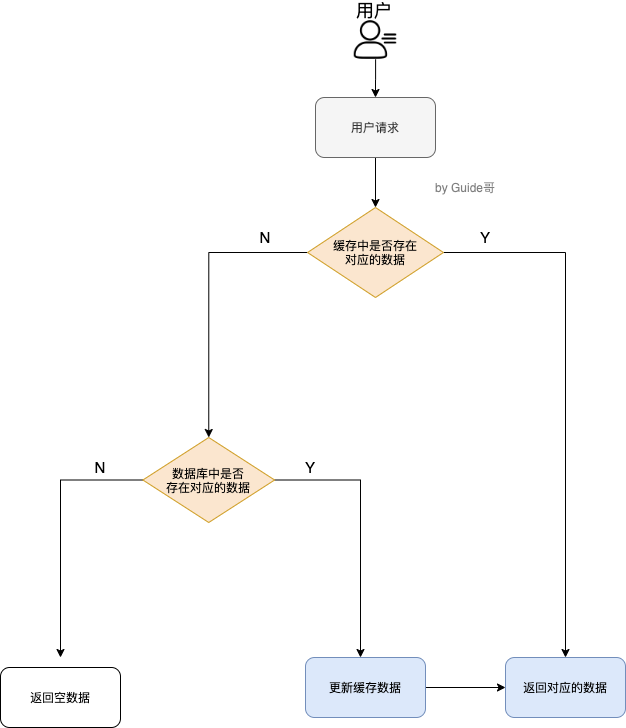
- 如果用户请求的数据在缓存中就直接返回
- 缓存中不存在的话就看数据库中是否存在
- 数据库中存在的话就更新缓存中的数据
- 数据库中不存在的话就返回空数据
为什么要用 Redis/为什么要用缓存
简单,来说使用缓存主要是为了提升用户体验以及应对更多的用户
下面我们主要从“高性能”和“高并发”这两点来看待这个问题
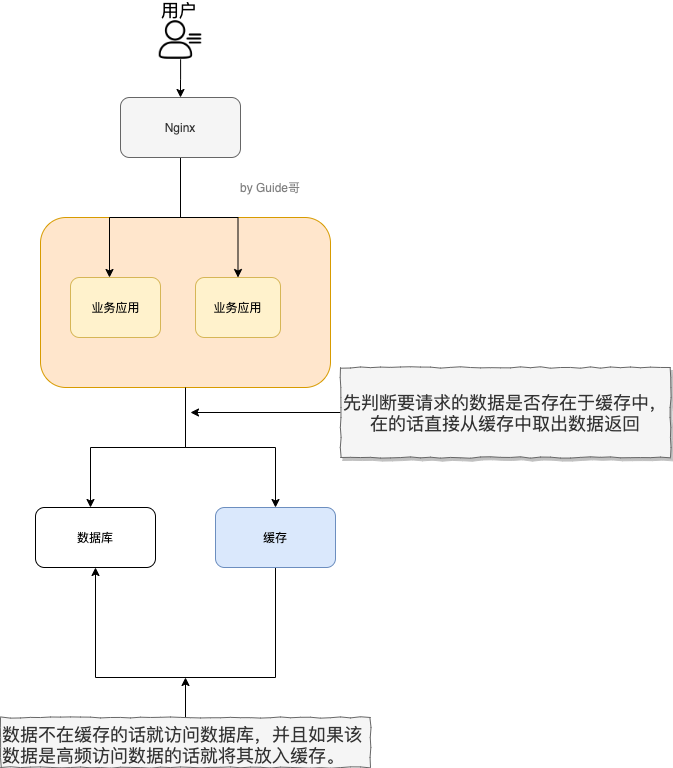
高性能:
假设场景:
假如用户第一次访问数据库中的某些数据的话,这个过程是比较慢,毕竟是从硬盘中读取的。但是,如果说,用户访问的数据属于高频数据并且不会经常改变的话,那么我们就可以将该用户访问的数据存在缓存中
这样的好处就是保证用户下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快
不过,要保持数据库和缓存中的数据的一致性。如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可
高并发:
一般像 MySQL 这类的数据库的 QPS 大概都在 1w 左右(4 核 8g),但是使用 Redis 缓存之后很容易达到 10w +,甚至最高能达到 30w +(就单机 redis 的情况,redis 集群的话会更高)
所以,直接操作缓存能够承受的数据库请求数量是远远大于直接访问数据库的,所以可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。进而,我们也就提高的系统整体的并发
Redis 单线程模型详解
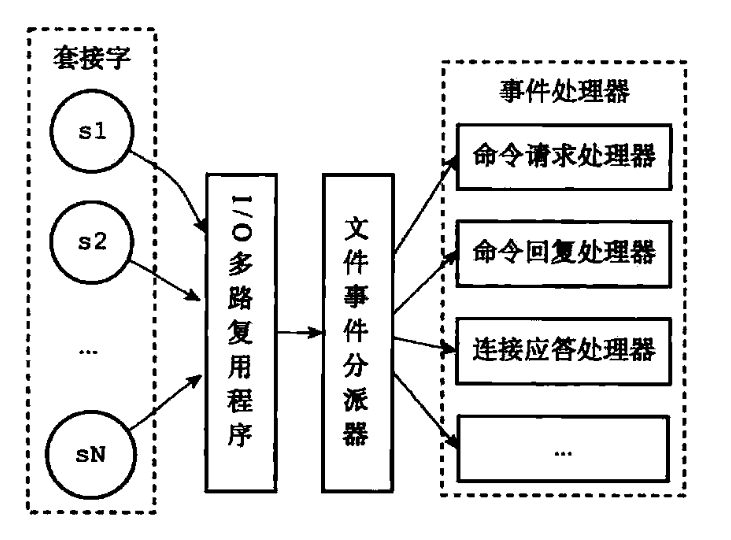
Redis 基于 Reactor 模式来设计开发了自己的一套高效的事件处理模型 (Netty 的线程模型也基于 Reactor 模式,Reactor 模式不愧是高性能 IO 的基石),这套事件处理模型对应的是 Redis 中的文件事件处理器(file event handler)。由于文件事件处理器(file event handler)是单线程方式运行的,所以一般都说 Redis 是单线程模型
监听大量的客户端连接
Redis 通过 IO 多路复用程序 监听来自客户端的大量连接(或者说是监听多个 socket),它会将感兴趣的事件及类型(读、写)注册到内核中并监听每个事件是否发生。
这样的好处非常明显: I/O 多路复用 技术的使用让 Redis 不需要额外创建多余的线程来监听客户端的大量连接,降低了资源的消耗(和 NIO 中的 Selector 组件很像)
另外, Redis 服务器是一个事件驱动程序,服务器需要处理两类事件: 1. 文件事件; 2. 时间事件
时间事件不需要多花时间了解,我们接触最多的还是 文件事件(客户端进行读取写入等操作,涉及一系列网络通信)
《Redis 设计与实现》文件事件
Redis 基于 Reactor 模式开发了自己的网络事件处理器:这个处理器被称为文件事件处理器(file event handler)。文件事件处理器使用 I/O 多路复用(multiplexing)程序来同时监听多个套接字,并根据 套接字目前执行的任务来为套接字关联不同的事件处理器。
当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关 闭(close)等操作时,与操作相对应的文件事件就会产生,这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
虽然文件事件处理器以单线程方式运行,但通过使用 I/O 多路复用程序来监听多个套接字,文件事件处理器既实现了高性能的网络通信模型,又可以很好地与 Redis 服务器中其他同样以单线程方式运行的模块进行对接,这保持了 Redis 内部单线程设计的简单性
可以看出,文件事件处理器(file event handler)主要是包含 4 个部分:
- 多个 socket(客户端连接)
- IO 多路复用程序(支持多个客户端连接的关键)
- 文件事件分派器(将 socket 关联到相应的事件处理器)
- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
Redis 没有使用多线程?为什么不使用多线程
虽然说 Redis 是单线程模型,但是,实际上 Redis 在 4.0 之后的版本中就已经加入了对多线程的支持
不过,Redis 4.0 增加的多线程主要是针对一些大键值对的删除操作的命令,使用这些命令就会使用主处理之外的其他线程来“异步处理”
Redis 6.0 之前主要还是单线程处理,主要原因可能是:
- 单线程编程容易并且更容易维护
- Redis 的性能瓶颈不再 CPU ,主要在内存和网络
- 多线程就会存在死锁、线程上下文切换等问题,甚至会影响性能
Redis6.0 引入多线程主要是为了提高网络 IO 读写性能,因为这个算是 Redis 中的一个性能瓶颈(Redis 的瓶颈主要受限于内存和网络)
虽然,Redis6.0 引入了多线程,但是 Redis 的多线程只是在网络数据的读写这类耗时操作上使用了, 执行命令仍然是单线程顺序执行。因此不需要担心线程安全问题
Redis 6.0 的多线程默认是禁用的,只使用主线程。如需开启需要修改 redis 配置文件 redis.conf
1
io-threads-do-reads yes
开启多线程后,还需要设置线程数,否则是不生效的。同样需要修改 redis 配置文件 redis.conf
1
io-threads 4 #官网建议4核的机器建议设置为2或3个线程,8核的建议设置为6个线程
Redis 给缓存数据设置过期时间有什么用
一般情况下,设置保存的缓存数据的时候都会设置一个过期时间
因为内存是有限的,如果缓存中的所有数据都是一直保存的话,那么很容易引发 Out of memory
Redis 自带了给缓存数据设置过期时间的功能,比如:
1
2
3
4
5
127.0.0.1:6379> exp key 60 # 数据在 60s 后过期
127.0.0.1:6379> setex key 60 value # 数据在 60s 后过期 (setex:[set] + [ex]pire)
127.0.0.1:6379> ttl key # 查看数据还有多久过期
Redis中除了字符串类型有自己独有设置过期时间的命令 setex 外,其他方法都需要依靠 expire 命令来设置过期时间 。另外, persist 命令可以移除一个键的过期时间
过期时间除了有助于缓解内存的消耗,还有什么其他用么?
很多时候,业务场景需要某个数据只在某一时间段内存在,比如短信验证码可能只在1分钟内有效,用户登录的 token 可能只在 1 天内有效
如果使用传统的数据库来处理的话,一般都是自己判断过期,这样更麻烦并且性能要差很多
Redis如何判断数据是否过期
Redis 通过一个叫做过期字典(可以看作是 hash 表)来保存数据过期的时间
过期字典的键指向 Redis 数据库中的某个 key(键) ,过期字典的值是一个 long 类型的整数,这个整数保存了字典 key 所指向的数据库键的过期时间(毫秒精度的 UNIX 时间戳)
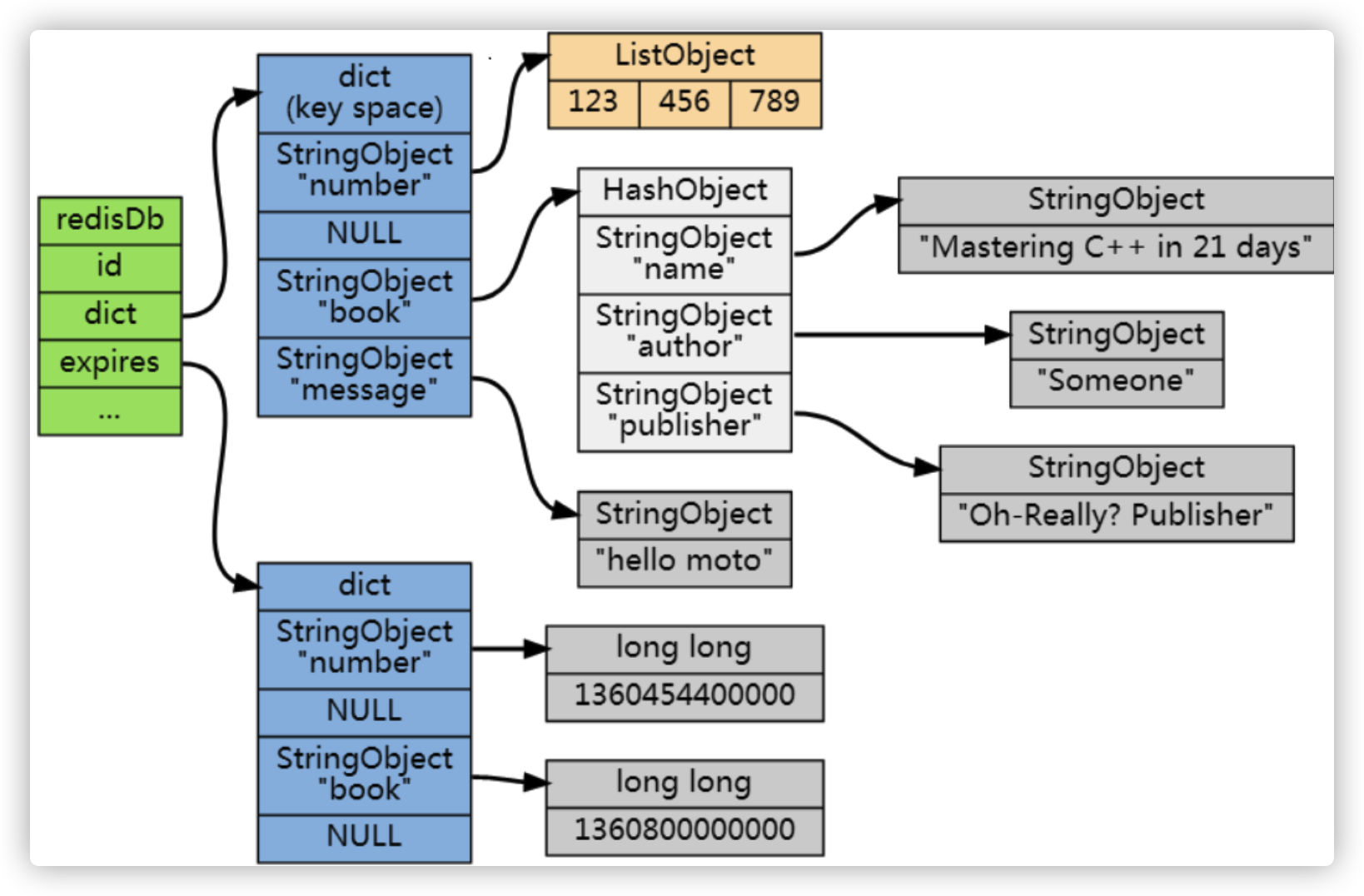
过期字典是存储在redisDb这个结构里的:
1
2
3
4
5
6
7
typedef struct redisDb {
...
dict *dict; //数据库键空间,保存着数据库中所有键值对
dict *expires // 过期字典,保存着键的过期时间
...
} redisDb;
过期数据的删除策略(淘汰策略)
常用的过期数据的删除策略有两个:
- 惰性删除 :只会在取出 key 的时候才对数据进行过期检查。这样对CPU最友好,但是可能会造成太多过期 key 没有被删除
- 定期删除 : 每隔一段时间抽取一批 key 执行删除过期 key 操作。并且,Redis 底层会并通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响
定期删除对内存更加友好
惰性删除对 CPU 更加友好
两者各有千秋,所以 Redis 采用的是 定期删除+惰性/懒汉式删除
定期理解: 默认 100ms 就随机抽一些设置了过期时间的 key,去检查是否过期,过期了就删了
不扫描全部: 假如 Redis 里面所有的 key 都有过期时间,都扫描一遍?那太恐怖了,而且线上基本上也都是会设置一定的过期时间的。全扫描跟你去查数据库不带 where 条件不走索引全表扫描一样,100ms一次,Redis 累都累死了
如果一直没随机到很多 key,惰性删除,见名知意,不主动删,等你来查询了看看过期没,过期就删了还不给你返回,没过期该怎么样就怎么样
但是,仅仅通过给 key 设置过期时间还是有问题的。因为还是可能存在定期删除和惰性删除漏掉了很多过期 key 的情况。这样就导致大量过期 key 堆积在内存里,然后就 Out of memory 了
如果定期没删,而且也没查询,那么就会涉及内存淘汰机制
Redis 内存淘汰机制可以解决大量过期 key 的问题
Redis 内存淘汰机制
Redis 提供 6 种数据淘汰策略:
- volatile-lru(least frequently used): 从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-ttl: 从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random: 从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
- allkeys-lru(least recently used): 当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 key(这个是最常用的)
- allkeys-random: 从数据集(server.db[i].dict)中任意选择数据淘汰
- no-eviction: 禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错
4.0 版本后增加以下两种:
-
volatile-lfu: 从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
-
allkeys-lfu: 当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的 key
Redis 持久化机制
很多时候需要持久化数据,也就是将内存中的数据写入到硬盘里面,大部分原因是为了之后重用数据(比如重启机器、机器故障之后恢复数据),或者是为了防止系统故障而将数据备份到一个远程位置
Redis 不同于 Memcached 的很重要一点就是:Redis 支持持久化,而且支持两种不同的持久化操作
Redis 的一种持久化方式叫快照(snapshotting,RDB),另一种方式是只追加文件(append-only file, AOF)。这两种方法各有千秋,下面详细这两种持久化方法是什么,怎么用,如何选择适合自己的持久化方法
快照(snapshotting)持久化(RDB)
Redis 可以通过创建快照来获得存储在内存里面的数据在某个时间点上的副本
RDB:快照形式是直接把内存中的数据保存到一个 dump 的文件中,定时保存,保存策略
工作原理:当 Redis 需要做持久化时,Redis 会 fork 一个子进程,子进程将数据写到磁盘上一个临时 RDB 文件中。当子进程完成写临时文件后,将原来的 RDB 替换掉,这样的好处是可以 copy-on-write
Redis 创建快照之后,可以对快照进行备份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本(Redis 主从结构,主要用来提高 Redis 性能),还可以将快照留在原地以便重启服务器的时候使用
快照持久化是 Redis 默认采用的持久化方式,在 Redis.conf 配置文件中默认有此下配置:
1
2
3
4
5
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
AOF(append-only file)持久化
与快照持久化相比,AOF 持久化 的实时性更好,因此已成为主流的持久化方案。默认情况下 Redis 没有开启 AOF(append only file)方式的持久化,可以通过 appendonly 参数开启:
AOF:把所有的对 Redis 的服务器进行修改的命令都存到一个文件里,命令的集合
以 append-only 的模式写入一个日志文件中,因为这个模式是只追加的方式,所以没有任何磁盘寻址的开销,所以很快,有点像Mysql中的binlog
可以做到全程持久化,只需要在配置中开启 appendonly yes。这样 Redis 每执行一个修改数据的命令,都会把它添加到 AOF 文件中,当 Redis 重启时,将会读取 AOF 文件进行重放,恢复到 Redis 关闭前的最后时刻。使用 AOF 的优点是会让 Redis 变得非常耐久。可以设置不同的 Fsync 策略,AOF 的默认策略是每秒钟 Fsync 一次,在这种配置下,就算发生故障停机,也最多丢失一秒钟的数据
1
appendonly yes
开启 AOF 持久化后每执行一条会更改 Redis 中的数据的命令,Redis 就会将该命令写入硬盘中的 AOF 文件。AOF 文件的保存位置和 RDB 文件的位置相同,都是通过 dir 参数设置的,默认的文件名是 appendonly.aof
在 Redis 的配置文件中存在三种不同的 AOF 持久化方式,它们分别是:
1
2
3
appendfsync always #每次有数据修改发生时都会写入AOF文件,这样会严重降低 Redis 的速度
appendfsync everysec #每秒钟同步一次,显示地将多个写命令同步到硬盘
appendfsync no #让操作系统决定何时进行同步
为了兼顾数据和写入性能,用户可以考虑 appendfsync everysec 选项 ,让 Redis 每秒同步一次 AOF 文件,Redis 性能几乎没受到任何影响。而且这样即使出现系统崩溃,用户最多只会丢失一秒之内产生的数据。当硬盘忙于执行写入操作的时候,Redis 还会优雅的放慢自己的速度以便适应硬盘的最大写入速度
Redis 4.0 开始支持 RDB (快照) 和 AOF 的混合持久化(默认关闭,可以通过配置项 aof-use-rdb-preamble 开启)
如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差
AOF重写
AOF 重写可以产生一个新的 AOF 文件,这个新的 AOF 文件和原有的 AOF 文件所保存的数据库状态一样,但体积更小
AOF 重写是一个有歧义的名字,该功能是通过读取数据库中的键值对来实现的,程序无须对现有 AOF 文件进行任何读入、分析或者写入操作。
在执行 BGREWRITEAOF 命令时,Redis 服务器会维护一个 AOF 重写缓冲区,该缓冲区会在子进程创建新 AOF 文件期间,记录服务器执行的所有写命令。当子进程完成创建新 AOF 文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新 AOF 文件的末尾,使得新旧两个 AOF 文件所保存的数据库状态一致。最后,服务器用新的 AOF 文件替换旧的 AOF 文件,以此来完成 AOF 文件重写操作
RDB 与 AOF 优缺点
RDB
优点: 生成多个数据文件,每个数据文件分别都代表了某一时刻 Redis 里面的数据,这种方式适合做冷备,完整的数据运维设置定时任务,定时同步到远端的服务器,比如阿里的云服务,这样一旦线上挂了,你想恢复多少分钟之前的数据,就去远端拷贝一份之前的数据就好了。RDB 对 Redis 的性能影响非常小,是因为在同步数据的时候他只是 fork 了一个子进程去做持久化的,而且他在数据恢复的时候速度比 AOF 来的快
缺点: RDB 都是快照文件,都是默认五分钟甚至更久的时间才会生成一次,这意味着你这次同步到下次同步这中间五分钟的数据都很可能全部丢失掉。AOF 则最多丢一秒的数据,数据完整性上高下立判。还有就是 RDB 在生成数据快照的时候,如果文件很大,客户端可能会暂停几毫秒甚至几秒,你公司在做秒杀的时候他刚好在这个时候 fork 了一个子进程去生成一个大快照,出大问题
AOF
优点: AOF 是一秒一次去通过一个后台的线程fsync操作,那最多丢这一秒的数据。
AOF 在对日志文件进行操作的时候是以 append-only 的方式去写的,他只是追加的方式写数据,自然就少了很多磁盘寻址的开销了,写入性能惊人,文件也不容易破损。AOF 的日志是通过一个叫非常可读的方式记录的,这样的特性就适合做灾难性数据误删除的紧急恢复了,比如公司的实习生通过 flushall 清空了所有的数据,只要这个时候后台重写还没发生,你马上拷贝一份AOF日志文件,把最后一条flushall 命令删了就完事了
缺点: AOF 的文件体积通常要大于 RDB 文件的体积。根据所使用的 Fsync 策略,AOF 的速度可能会慢于 RDB
两种策略选择:
如果非常关心你的数据,但仍然可以承受数分钟内的数据丢失,那么可以只使用 RDB 持久
AOF 将 Redis 执行的每一条命令追加到磁盘中,处理巨大的写入会降低 Redis 的性能,不知道你是否可以接受
数据库备份和灾难恢复:定时生成 RDB 快照非常便于进行数据库备份,并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度快。
当然了,Redis 支持同时开启 RDB 和 AOF,系统重启后,Redis 会优先使用 AOF 来恢复数据,这样丢失的数据会最少,真出什么时候第一时间用 RDB 恢复,然后 AOF 做数据补全
Redis 事务
Redis 可以通过 MULTI,EXEC,DISCARD 和 WATCH 等命令来实现事务(transaction)功能
1
2
3
4
5
6
7
8
9
> MULTI
OK
> INCR foo
QUEUED
> INCR bar
QUEUED
> EXEC
1) (integer) 1
2) (integer) 1
使用 MULTI 命令后可以输入多个命令。Redis 不会立即执行这些命令,而是将它们放到队列,当调用了 EXEC 命令将执行所有命令
但是,Redis 的事务和我们平时理解的关系型数据库的事务不同,Redis 是不支持 roll back 的,因而不满足原子性的(而且不满足持久性)
简单来说就是 Redis 开发者们觉得没必要支持回滚,这样更简单便捷并且性能更好。Redis 开发者觉得即使命令执行错误也应该在开发过程中就被发现而不是生产过程中
Redis 的事务像是提供了一种将多个命令请求打包的功能。然后,再按顺序执行打包的所有命令,并且不会被中途打断
如果有大量的key需要设置同一时间过期,一般需要注意什么?
如果大量的key过期时间设置的过于集中,到过期的那个时间点,Redis可能会出现短暂的卡顿现象。严重的话会出现缓存雪崩,我们一般需要在时间上加一个随机值,使得过期时间分散一些。
电商首页经常会使用定时任务刷新缓存,可能大量的数据失效时间都十分集中,如果失效时间一样,又刚好在失效的时间点大量用户涌入,就有可能造成缓存雪崩
缓存穿透
产生这个问题的原因可能是外部的恶意攻击,例如,对用户信息进行了缓存,但恶意攻击者使用不存在的用户 id 频繁请求接口导致查询缓存不命中,然后穿透 DB 查询依然不命中。这时会有大量请求穿透缓存访问到 DB。缓存和数据库中都没有的数据,而用户(黑客)不断发起请求。举个例子:如果我们数据库的 id 都是从 1 自增的,如果发起 id=-1 的数据或者 id 特别大不存在的数据,这样的不断攻击导致数据库压力很大,严重会击垮数据库
解决方法:
- 对不存在的用户,在缓存中保存一个空对象进行标记,防止相同 ID 再次访问 DB。不过有时这个方法并不能很好解决问题,可能导致缓存中存储大量无用数据
- 使用 BloomFilter 过滤器,BloomFilter 的特点是存在性检测,如果 BloomFilter 中不存在,那么数据一定不存在;如果 BloomFilter 中存在,实际数据也有可能会不存在。非常适合解决这类的问题,原理:利用高效的数据结构和算法快速判断出你这个 Key 是否在数据库中存在,不存在你 return 就好了,存在你就去查 DB 刷新 KV 再 return
- 缓存穿透我会在接口层增加校验,比如用户鉴权,参数做校验,不合法的校验直接 return,比如 id 做基础校验,id<=0 直接拦截
缓存击穿
某个热点数据失效时,大量针对这个数据的请求会穿透到数据源。跟缓存雪崩有点像,但是又有一点不一样,缓存雪崩是因为大面积的缓存失效,打崩了 DB。而缓存击穿不同的是缓存击穿是指一个 Key 非常热点,在不停地扛着大量的请求,大并发集中对这一个点进行访问,当这个 Key 在失效的瞬间,持续的大并发直接落到了数据库上,就在这个 Key 的点上击穿了缓存
解决方法:
- 可以使用互斥锁更新,保证同一个进程中针对同一个数据不会并发请求到 DB,减小 DB 压力
- 使用随机退避方式,失效时随机 sleep 一个很短的时间,再次查询,如果失败再执行更新
- 针对多个热点 key 同时失效的问题,可以在缓存时使用固定时间加上一个小的随机数,避免大量热点 key 同一时刻失效
- 设置热点数据永不过期
缓存雪崩
产生的原因是缓存挂掉,这时所有的请求都会穿透到 DB。目前电商首页以及热点数据都会去做缓存,一般缓存都是定时任务去刷新,或者查不到之后去更新缓存的,定时任务刷新就有一个问题
举个例子:如果首页所有 Key 的失效时间都是 12 小时,中午 12 点刷新的,我零点有个大促活动大量用户涌入,假设每秒 6000 个请求,本来缓存可以抗住每秒 5000 个请求,但是缓存中所有 Key 都失效了。此时 6000 个/秒的请求全部落在了数据库上,数据库必然扛不住,真实情况可能 DBA 都没反应过来直接挂了。此时,如果没什么特别的方案来处理,DBA 很着急,重启数据库,但是数据库立马又被新流量给打死了。这就是缓存雪崩
解决方法:
- 使用快速失败的熔断策略,减少 DB 瞬间压力
- 使用主从模式和集群模式来尽量保证缓存服务的高可用(如果 Redis 是集群部署,将热点数据均匀分布在不同的 Redis 库中也能避免全部失效)
- 在批量往 Redis 存数据的时候,把每个 Key 的失效时间都加个随机值就好了,这样可以保证数据不会再同一时间大面积失效
- 设置热点数据永不过期,有更新操作就更新缓存就好了(比如运维更新了首页商品,那你刷下缓存就好了,不要设置过期时间),电商首页的数据也可以用这个操作,保险
穿透击穿雪崩避免总结
- 事前:Redis 高可用,主从+哨兵,Redis cluster,避免全盘崩溃
- 事中:本地 ehcache 缓存 + Hystrix 限流+降级,避免** MySQL** 被打死
- 事后:Redis 持久化 RDB+AOF,一旦重启,自动从磁盘上加载数据,快速恢复缓存数据限流组件,可以设置每秒的请求,有多少能通过组件,剩余的未通过的请求,怎么办?走降级!可以返回一些默认的值,或者友情提示,或者空白的值
好处: 数据库绝对不会死,限流组件确保了每秒只有多少个请求能通过。 只要数据库不死,就是说,对用户来说,3/5 的请求都是可以被处理的。 只要有 3/5 的请求可以被处理,就意味着你的系统没死,对用户来说,可能就是点击几次刷不出来页面,但是多点几次,就可以刷出来一次
这个在目前主流的互联网大厂里面是最常见的,你是不是好奇,某明星爆出什么事情,你发现你去微博怎么刷都空白界面,但是有的人又直接进了,你多刷几次也出来了,那是做了降级,牺牲部分用户的体验换来服务的安全
Redis 其他保证集群高可用的方式
哨兵集群sentinel:哨兵必须用三个实例去保证自己的健壮性
哨兵 + 主从 并不能保证数据不丢失,但是可以保证集群的高可用
哨兵组件主要功能:
- 集群监控:负责监控 Redis master 和 slave 进程是否正常工作
- 消息通知:如果某个 Redis 实例有故障,那么哨兵负责发送消息作为报警通知给管理员
- 故障转移:如果 master node 挂掉了,会自动转移到 slave node 上
- 配置中心:如果故障转移发生了,通知 client 客户端新的 master 地址
Redis 主从同步
为什么要用主从这样的架构模式,前面提到了单机QPS(每秒查询率)是有上限的,而且 Redis 的特性就是必须支撑读高并发的,那一台机器又读又写,服务器的是顶不住的。但是可以让这个 master 机器去写,数据同步给别的 slave 机器,他们都拿去读,分发掉大量的请求那是不是好很多,而且扩容的时候还可以轻松实现水平扩容
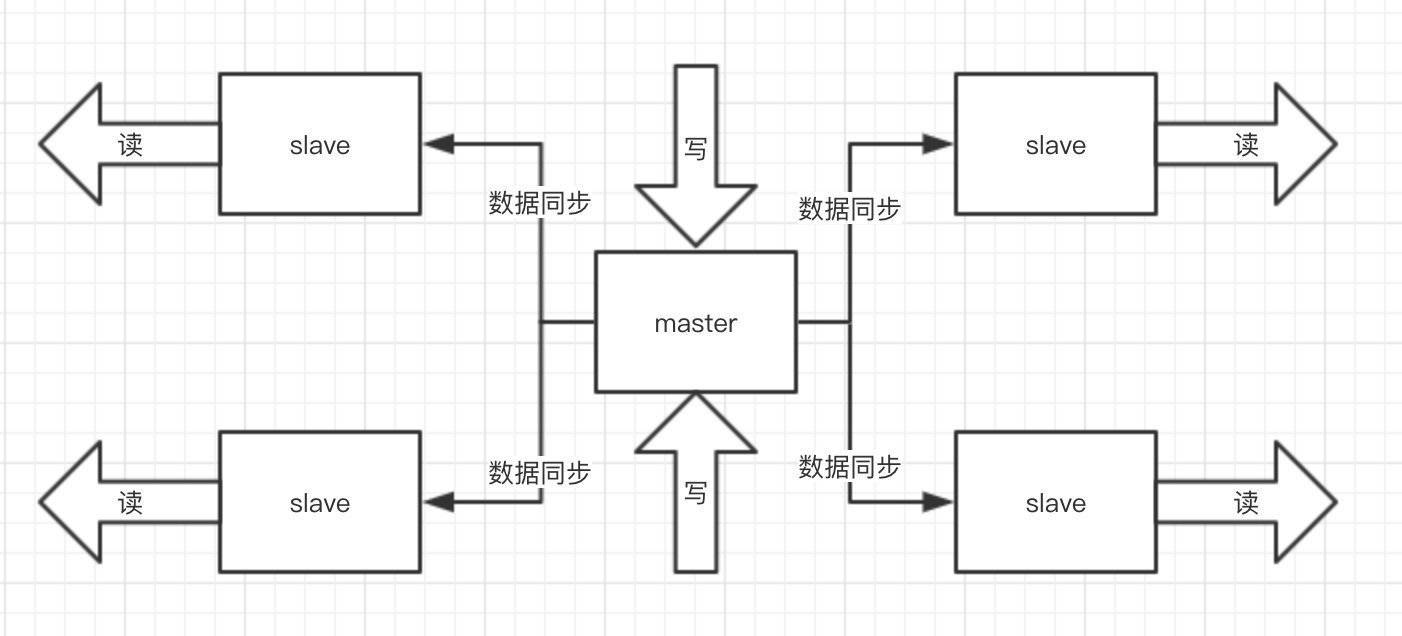
启动一台 slave 的时候,它会发送一个 psync 命令给 master ,如果是这个 slave 第一次连接到 master,它会触发一个全量复制,master 就会启动一个线程,生成 RDB 快照,还会把新的写请求都缓存在内存中,RDB 文件生成后,master 会将这个 RDB 发送给 slave ,slave 拿到之后做的第一件事情就是写进本地的磁盘,然后加载进内存,之后 master 会把内存里面缓存的那些新命名(AOF)都发给 slave。有新的数据进入 master 使用 AOF 嘛,增量的就像MySQL 的 Binlog 一样,把日志增量同步给从服务就好了
传输过程中有什么网络问题啥的,会自动重连的,并且连接之后会把缺少的数据补上。同时 RDB 快照的数据生成的时候,缓存区也必须同时开始接受新请求,不然旧的数据过去了,同步期间的增量数据没法一致
复制过程
- 从节点执行 slaveof[masterIP][masterPort],保存主节点信息
- 从节点中的定时任务发现主节点信息,建立和主节点的 Socket 连接
- 从节点发送 Ping 信号,主节点返回 Pong,两边能互相通信
- 连接建立后,主节点将所有数据发送给从节点(数据同步)
- 主节点把当前的数据同步给从节点后,便完成了复制的建立过程。接下来,主节点就会持续的把写命令发送给从节点,保证主从数据一致性
数据同步的过程
Redis 2.8 之前使用 sync[runId][offset] 同步命令,Redis 2.8 之后使用 psync[runId][offset] 命令。两者不同在于:Sync 命令仅支持全量复制过程;Psync 支持全量和部分复制
runId:每个 Redis 节点启动都会生成唯一的 uuid,每次 Redis 重启后,runId 都会发生变化
offset:主节点和从节点都各自维护自己的主从复制偏移量 offset,当主节点有写入命令时,offset=offset+命令的字节长度
从节点在收到主节点发送的命令后,也会增加自己的 offset,并把自己的 offset 发送给主节点。这样,主节点同时保存自己的 offset 和从节点的 offset,通过对比 offset 来判断主从节点数据是否一致
repl_backlog_size:保存在主节点上的一个固定长度的先进先出队列,默认大小是 1MB
主节点发送数据给从节点过程中,主节点还会进行一些写操作,这时候的数据存储在复制缓冲区中
从节点同步主节点数据完成后,主节点将缓冲区的数据继续发送给从节点,用于部分复制
主节点响应写命令时,不但会把命名发送给从节点,还会写入复制积压缓冲区,用于复制命令丢失的数据补救
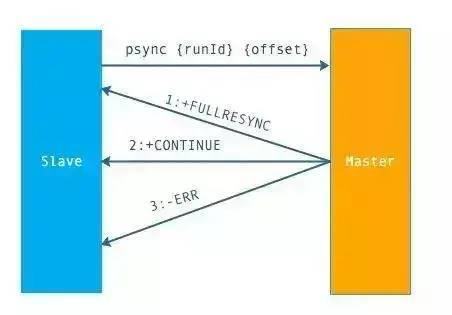
上面是 Psync(支持全量和部分复制) 的执行流程,从节点发送 psync[runId][offset] 命令,主节点有三种响应:
- FULLRESYNC:第一次连接,进行全量复制
- CONTINUE:进行部分复制
- ERR:不支持 psync 命令,进行全量复制
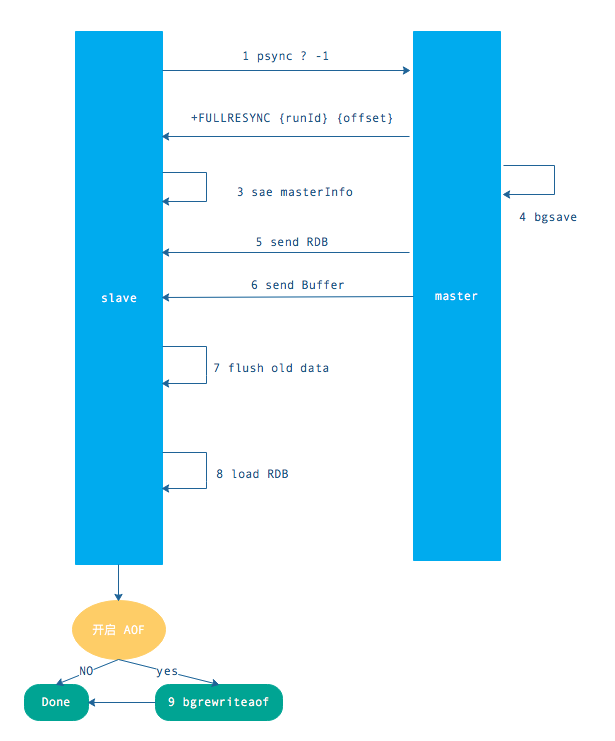
上面是全量复制的流程。主要有以下几步:
- 从节点发送 psync ? -1 命令(因为第一次发送,不知道主节点的 runId,所以为?,因为是第一次复制,所以 offset=-1)。
- 主节点发现从节点是第一次复制,返回 FULLRESYNC {runId} {offset},runId 是主节点的 runId,offset 是主节点目前的 offset。
- 从节点接收主节点信息后,保存到 info 中。
- 主节点在发送 FULLRESYNC 后,启动 bgsave 命令,生成 RDB 文件(数据持久化)。主节点发送 RDB 文件给从节点。到从节点加载数据完成这段期间主节点的写命令放入缓冲区。
- 从节点清理自己的数据库数据。
- 从节点加载 RDB 文件,将数据保存到自己的数据库中。如果从节点开启了 AOF,从节点会异步重写 AOF 文件
部分复制的过程:
- 部分复制主要是 Redis 针对全量复制的过高开销做出的一种优化措施,使用 psync[runId][offset] 命令实现
当从节点正在复制主节点时,如果出现网络闪断或者命令丢失等异常情况时,从节点会向主节点要求补发丢失的命令数据,主节点的复制积压缓冲区将这部分数据直接发送给从节点。
这样就可以保持主从节点复制的一致性。补发的这部分数据一般远远小于全量数据。
-
主从连接中断期间主节点依然响应命令,但因复制连接中断命令无法发送给从节点,不过主节点内的复制积压缓冲区依然可以保存最近一段时间的写命令数据。
-
当主从连接恢复后,由于从节点之前保存了自身已复制的偏移量和主节点的运行 ID。因此会把它们当做 psync 参数发送给主节点,要求进行部分复制。
-
主节点接收到 psync 命令后首先核对参数 runId 是否与自身一致,如果一致,说明之前复制的是当前主节点。
之后根据参数 offset 在复制积压缓冲区中查找,如果 offset 之后的数据存在,则对从节点发送+COUTINUE 命令,表示可以进行部分复制。因为缓冲区大小固定,若发生缓冲溢出,则进行全量复制。
- 主节点根据偏移量把复制积压缓冲区里的数据发送给从节点,保证主从复制进入正常状态
主从复制会存在哪些问题
- 一旦主节点宕机,从节点晋升为主节点,同时需要修改应用方的主节点地址,还需要命令所有从节点去复制新的主节点,整个过程需要人工干预。
- 主节点的写能力受到单机的限制。
- 主节点的存储能力受到单机的限制。
- 原生复制的弊端在早期的版本中也会比较突出,比如:Redis 复制中断后,从节点会发起 psync。此时如果同步不成功,则会进行全量同步,主库执行全量备份的同时,可能会造成毫秒或秒级的卡顿
主从复制的问题主流解决方案:哨兵
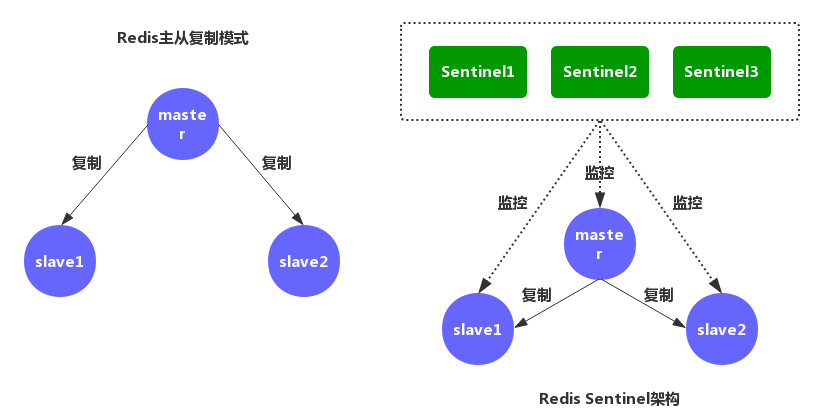
上面是 Redis Sentinel(哨兵)的架构图。Redis Sentinel(哨兵)主要功能包括主节点存活检测、主从运行情况检测、自动故障转移、主从切换
Redis Sentinel 最小配置是一主一从。Redis 的 Sentinel 系统可以用来管理多个 Redis 服务器
该系统可以执行以下四个任务:
- 监控:不断检查主服务器和从服务器是否正常运行
- 通知:当被监控的某个 Redis 服务器出现问题,Sentinel 通过 API 脚本向管理员或者其他应用程序发出通知
- 自动故障转移:当主节点不能正常工作时,Sentinel 会开始一次自动的故障转移操作,它会将与失效主节点是主从关系的其中一个从节点升级为新的主节点,并且将其他的从节点指向新的主节点,这样 人工干预就可以免了
- 配置提供者:在 Redis Sentinel 模式下,客户端应用在初始化时连接的是 Sentinel 节点集合,从中获取主节点的信息
哨兵工作原理
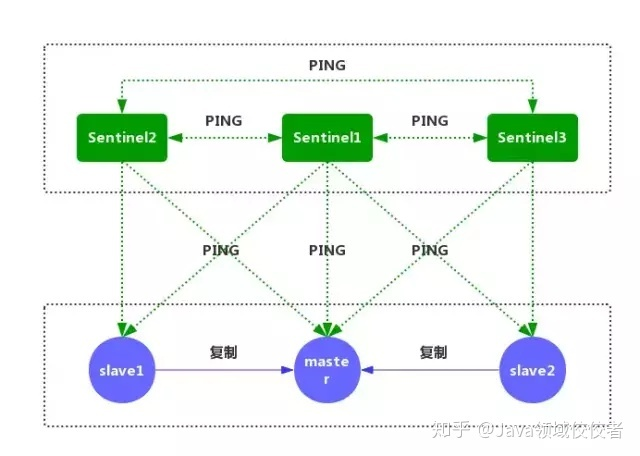
- 每个 Sentinel 节点都需要定期执行以下任务:每个 Sentinel 以每秒一次的频率,向它所知的主服务器、从服务器以及其他的 Sentinel 实例发送一个 PING 命令(如上图)
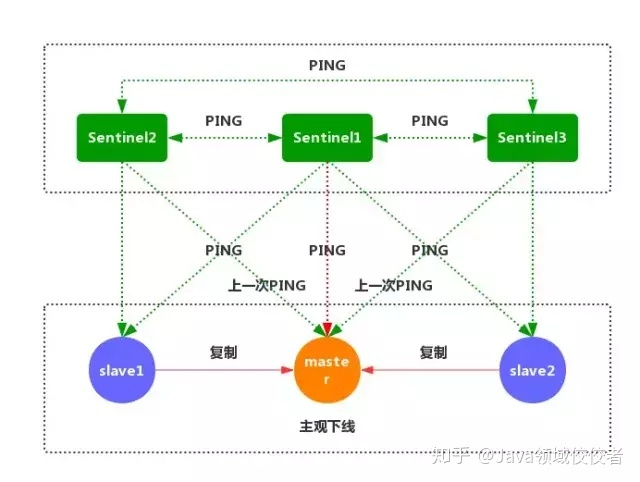
- 如果一个实例距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 所指定的值,那么这个实例会被 Sentinel 标记为主观下线(如上图)
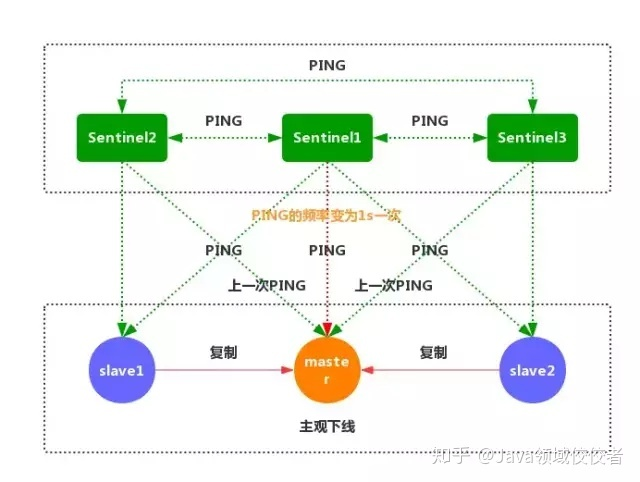
- 如果一个主服务器被标记为主观下线,那么正在监视这个服务器的所有 Sentinel 节点,要以每秒一次的频率确认主服务器的确进入了主观下线状态
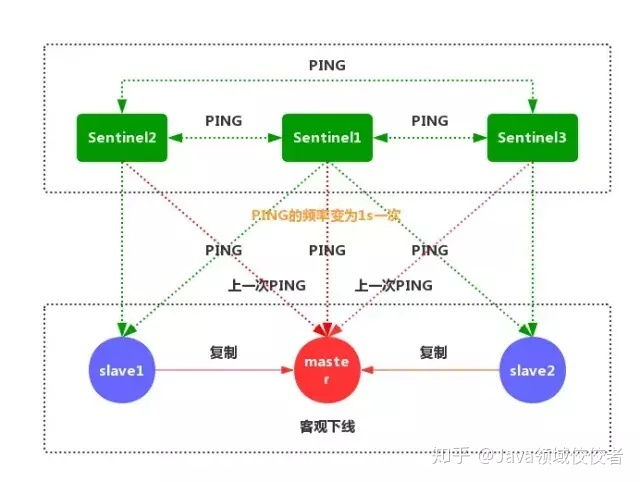
- 如果一个主服务器被标记为主观下线,并且有足够数量的 Sentinel(至少要达到配置文件指定的数量)在指定的时间范围内同意这一判断,那么这个主服务器被标记为客观下线
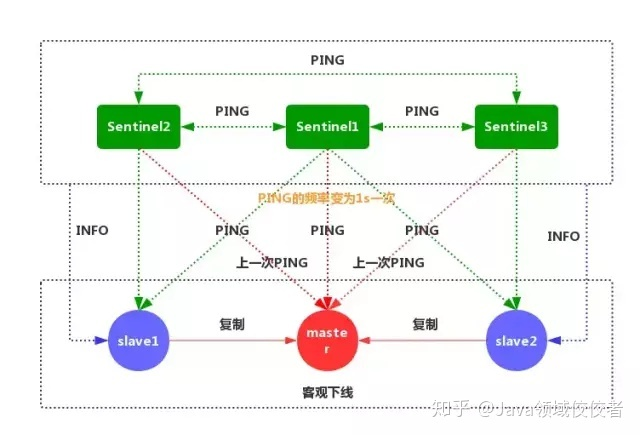
- 一般情况下,每个 Sentinel 会以每 10 秒一次的频率向它已知的所有主服务器和从服务器发送 INFO 命令 当一个主服务器被标记为客观下线时,Sentinel 向下线主服务器的所有从服务器发送 INFO 命令的频率,会从 10 秒一次改为每秒一次
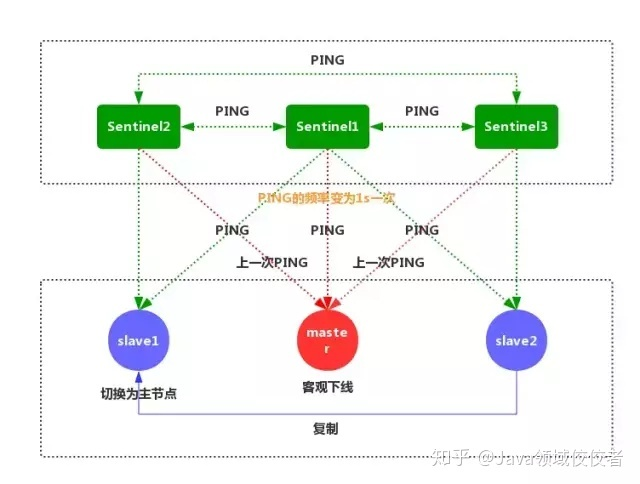
- Sentinel 和其他 Sentinel 协商客观下线的主节点的状态,如果处于 SDOWN 状态,则投票自动选出新的主节点,将剩余从节点指向新的主节点进行数据复制
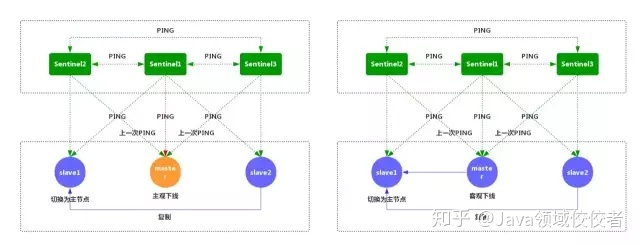
- 当没有足够数量的Sentinel同意主服务器下线时,主服务器的客观下线状态就会被移除
当主服务器重新向Sentinel的PING命令返回有效回复时主服务器的主观下线状态就会被移除
redis单例、主从模式、哨兵sentinel以及集群的配置方式及优缺点对比
redis 单例的安装和使用
redis 相对于其他的缓存框架安装非常的方便,只需要从https://redis.io/download下载后解压,进入redis目录之后执行如下命令即安装完成:
make install
这里需要注意的是 make 是 gcc 中的一个命令,安装之前请确保机器安装了 gcc。redis 中所有的命令都在 redis 安装目录中的 src 子目录下,其中比较重要的是 redis-server ,redis-sentinel ,redis-cli
编译完成之后在 src 目录下执行 ./redis-server 启动 redis(启动后可关闭该窗口),然后新开一个窗口,在命令行中执行 ./redis-cli 即可连接启动的 redis 服务。在其中执行如下命令即可看到编译安装成功了:
1
2
3
4
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> get hello
"world"
按照上述方式启动 redis,其使用的 ip 为本机 ip 127.0.0.1 ,端口为 6379 ,并且其余的配置采用的都是默认配置,相关配置可在 redis 安装目录下的 redis.conf 文件中查看。如果需要按照指定的配置文件来启动,可在 redis-server 后接上配置文件名,如:
./src/redis-server redis.conf
另外,上述使用 redis-cli 连接 redis 客户端时如果不带任何参数,那么其连接的默认 ip 和端口为 127.0.0.1:6379 。如果需要连接指定 ip 和端口的客户端,可以使用如下方式:
./src/redis-cli -h 127.0.0.1 -p 6379
这里 -h 参数表示连接的 ip ,-p 则表示连接的端口。配置好 redis 之后,就可以在 redis 中执行相关命令来操作数据
redis 主从模式的配置
redis 单例提供了一种数据缓存方式和丰富的数据操作 api ,但是将数据完全存储在单个 redis 中主要存在两个问题:数据备份和数据体量较大造成的性能降低。这里 redis 的主从模式为这两个问题提供了一个较好的解决方案
主从模式指的是使用一个 redis 实例作为主机,其余的实例作为备份机。主机和从机的数据完全一致,主机支持数据的写入和读取等各项操作,而从机则只支持与主机数据的同步和读取,也就是说,客户端可以将数据写入到主机,由主机自动将数据的写入操作同步到从机
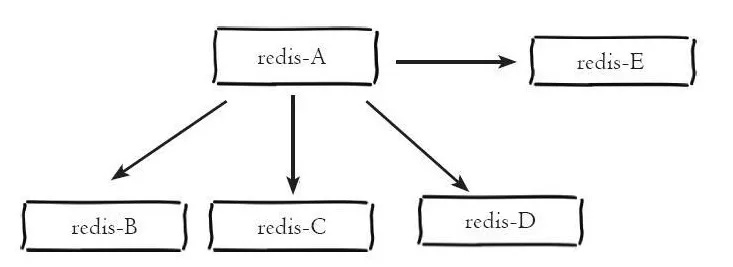
主从模式很好的解决了数据备份问题,并且由于主从服务数据几乎是一致的,因而可以将写入数据的命令发送给主机执行,而读取数据的命令发送给不同的从机执行,从而达到读写分离的目的。如下所示主机 redis-A 分别有 redis-B、redis-C、redis-D、redis-E 四个从机:
上面介绍了 redis 单例的配置方式,而上面我们也介绍了主从模式其实也是多个 redis 实例组成的,因而 redis 主从模式的配置可以理解为多个不同的 redis 实例通过一定的配置告知其相互之间的主从关系
每个 redis 实例都会占用一个本机的端口号,主从模式的配置主要的配置点有两个:当前实例端口号和当前实例是主机还是从机,是从机的话其主机的 ip 和端口是什么。一般的 redis 目录下的 redis.conf 保存的是默认配置,尽量不要对其进行修改,这里我们复制三份 redis.conf 文件,分别命名为 6379.conf,6380.conf 和 6381.conf ,如下是端口为 6379 的主机的主要配置:
1
2
3
4
bind 127.0.0.1
port 6379
logfile "6379.log"
dbfilename "dump-6379.rdb"
如下是端口为 6380 和 6381 的 从机的配置:
1
2
3
4
5
bind 127.0.0.1
port 6380
logfile "6380.log"
dbfilename "dump-6380.rdb"
slaveof 127.0.0.1 6379
1
2
3
4
5
bind 127.0.0.1
port 6381
logfile "6381.log"
dbfilename "dump-6381.rdb"
slaveof 127.0.0.1 6379
端口为 6380 和 6381 的实例被配置为端口为 6379 的实例的从机。配置完成后使用 redis-server 分别执行如下命令启动三个实例:
1
2
3
./src/redis-server 6379.conf
./src/redis-server 6380.conf
./src/redis-server 6381.conf
启动之后分别开启三个命令行工具分别执行以下命令连接 redis 实例:
1
2
3
./src/redis-cli -p 6379
./src/redis-cli -p 6380
./src/redis-cli -p 6381
分别在三个命令行工具中执行一个 get 命令,获取键名为 msg 的数据,如下所示:
1
2
127.0.0.1:6379> get msg
(nil)
1
2
127.0.0.1:6380> get msg
(nil)
1
2
127.0.0.1:6381> get msg
(nil)
在三个 redis 实例中都不存在键为 msg 的数据,现在在主机 6379 上设置一个键为 msg 的数据,如下所示:
1
2
127.0.0.1:6379> set msg "hello"
OK
接着在 6380 和 6381 的实例上执行 get msg 命令:
1
2
127.0.0.1:6380> get msg
"hello"
1
2
127.0.0.1:6381> get msg
"hello"
另外,如果不在配置文件中指定主从节点的关系,也可以在启动相关 redis 实例之后使用 slaveof 命令来指定当前节点称为某个节点的从节点,如:
1
127.0.0.1:6380> slaveof 127.0.0.1 6379
redis 中哨兵 sentinel 配置
redis 主从模式解决了数据备份和单例可能存在的性能问题,但是其也引入了新的问题。由于主从模式配置了三个 redis 实例,并且每个实例都使用不同的 ip(如果在不同的机器上)和端口号,根据前面所述,主从模式下可以将读写操作分配给不同的实例进行从而达到提高系统吞吐量的目的,但也正是因为这种方式造成了使用上的不便
因为每个客户端连接 redis 实例的时候都是指定了 ip 和端口号的,如果所连接的 redis 实例因为故障下线了,而主从模式也没有提供一定的手段通知客户端另外可连接的客户端地址,因而需要手动更改客户端配置重新连接。另外,主从模式下,如果主节点由于故障下线了,那么从节点因为没有主节点而同步中断,因而需要人工进行故障转移工作
为了解决这两个问题,在 2.8 版本之后 redis 正式提供了 sentinel(哨兵)架构
每个 sentinel 节点其实就是一个 redis 实例,与主从节点不同的是 sentinel 节点作用是用于监控 redis 数据节点的,而 sentinel 节点集合则表示监控一组主从 redis 实例多个 sentinel 监控节点的集合,比如有主节点 master 和从节点 slave-1、slave-2,为了监控这三个主从节点,这里配置 N 个s entinel 节点sentinel-1,sentinel-2,…,sentinel-N。如下图是 sentinel 监控主从节点的示例图:
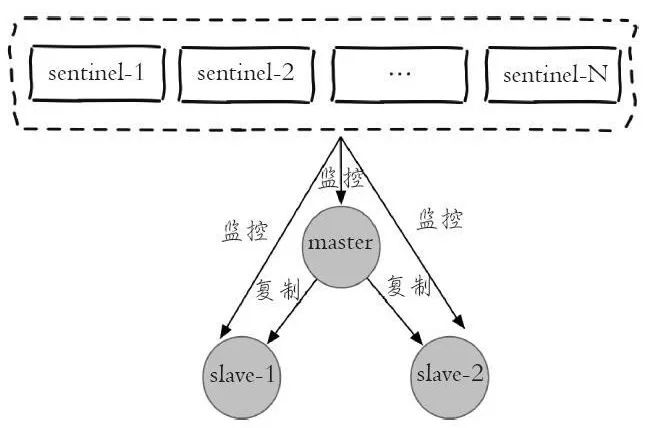
从图中可以看出,对于一组主从节点,sentinel 只是在其外部额外添加的一组用于监控作用的 redis 实例。在主从节点和 sentinel 节点集合配置好之后,sentinel 节点之间会相互发送消息,以检测其余 sentinel 节点是否正常工作,并且 sentinel 节点也会向主从节点发送消息,以检测监控的主从节点是否正常工作
前面讲到,sentinel 架构的主要作用是 解决主从模式下主节点的故障转移工作 的。这里如果主节点因为故障下线,那么某个 sentinel 节点发送检测消息给主节点时,如果在指定时间内收不到回复,那么该 sentinel 就会主观的判断该主节点已经下线,那么其会发送消息给其余的 sentinel 节点,询问其是否“认为”该主节点已下线,其余的 sentinel 收到消息后也会发送检测消息给主节点
如果其认为该主节点已经下线,那么其会回复向其询问的 sentinel 节点,告知其也认为主节点已经下线,当该 sentinel 节点最先收到超过指定数目(配置文件中配置的数目和当前 sentinel 节点集合数的一半,这里两个数目的较大值)的 sentinel 节点回复说当前主节点已下线,那么其就会对主节点进行故障转移工作,故障转移的基本思路是在从节点中选取某个从节点向其发送slaveof no one(假设选取的从节点为127.0.0.1:6380),使其称为独立的节点(也就是新的主节点),然后 sentinel 向其余的从节点发送 slaveof 127.0.0.1 6380 命令使它们重新成为新的主节点的从节点
重新分配之后 sentinel 节点集合还会继续监控已经下线的主节点(假设为127.0.0.1:6379),如果其重新上线,那么 sentinel 会向其发送 slaveof 命令,使其成为新的主机点(6380)的从节点,如此故障转移工作完成
每个 sentinel 节点在本质上还是一个 redis 实例,只不过和 redis 数据节点不同的是,其主要作用是监控 redis 数据节点。在 redis 安装目录下有个默认的 sentinel 配置文件sentinel.conf,和配置主从节点类似,这里复制三个配置文件:sentinel-26379.conf,sentinel-26380.conf 和 sentinel-26381.conf。分别按照如下示例编辑这三个配置文件:
1
2
3
4
5
6
7
8
9
port 26379
daemonize yes
logfile "26379.log"
dir /opt/soft/redis/data
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
sentinel myid mm55d2d712b1f3f312b637f9b546f00cdcedc787
对于端口为 26380 和 26381 的 sentinel ,其配置和上述类似,只需要把相应的端口号修改为对应的端口号即可。这里注意两点:
- 每个 sentinel 的 myid 参数也要进行修改,因为 sentinel 之间是通过该属性来唯一区分其他 sentinel 节点的
- 参数中 sentinel monitor mymaster 127.0.0.1 6379 2 这里的端口号 6379 是不用更改的,因为 sentinel 是通过检测主节点的状态来得知当前主节点的从节点有哪些的,因而设置为主节点的端口号即可
配置完成后首先启动三个主从节点,然后分别使用三个配置文件使用如下命令启用sentinel:
1
2
3
./src/redis-sentinel sentinel-26379.conf
./src/redis-sentinel sentinel-26380.conf
./src/redis-sentinel sentinel-26381.conf
由于 sentinel 节点也是一个 redis 实例,因而可以通过如下命令使用 redis-cli 连接 sentinel 节点:
1
./src/redis-cli -p 26379
连上 sentinel 节点之后可以通过如下命令查看 sentinel 状态:
1
127.0.0.1:26379> info sentinel
结果:
1
2
3
4
5
6
7
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=127.0.0.1:6379,slaves=2,sentinels=3
可以看到,sentinel 检测到主从节点总共有三个,其中一个主节点,两个从节点,并且 sentinel 节点总共也有三个。启动完成之后,通过主动下线主节点来模拟 sentinel的故障转移过程。首先我们连接上端口为 6379 的主节点,使用如下命令查看主从节点状态:
1
127.0.0.1:6379> info replication
结果:
1
2
3
4
5
6
7
8
9
10
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=45616,lag=1
slave1:ip=127.0.0.1,port=6381,state=online,offset=45616,lag=1
master_repl_offset:45616
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:45615
可以看到,当前主节点有两个从节点,端口分别为 6380 和 6381 。然后对主节点执行如下命令:
1
127.0.0.1:6379> shutdown save
然后连接上端口号为 6380 的从节点,并执行如下命令:
1
127.0.0.1:6380> info replication
结果如下:
1
2
3
4
5
6
7
8
9
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6381,state=online,offset=12344,lag=0
master_repl_offset:12477
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:12476
当端口为 6379 的实例下线之后,端口为 6380 的实例被重新竞选为新的主节点,并且端口为6381 的实例被设置为 6380 的实例的从节点。如果此时重新启用端口为 6379 的节点,然后再查看主从状态,结果如下:
1
2
3
4
5
6
7
8
9
10
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6381,state=online,offset=59918,lag=0
slave1:ip=127.0.0.1,port=6379,state=online,offset=59918,lag=1
master_repl_offset:60051
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:60050
可以看到,端口为 6379 的 redis 实例重新连接后,sentinel 节点检测到其重新连接,那么对其发送命令,使其成为新的主节点的从节点
redis Cluster 集群的配置
redis 集群是在 redis 3.0 版本推出的一个功能,其有效的解决了 redis 在分布式方面的需求。当遇到单机内存,并发和流量瓶颈等问题时,可采用 Cluster 方案达到负载均衡的目的
并且从另一方面讲,redis 中 sentinel 有效的解决了故障转移的问题,也解决了主节点下线客户端无法识别新的可用节点的问题,但是如果是从节点下线了,sentinel 是不会对其进行故障转移的,并且连接从节点的客户端也无法获取到新的可用从节点 ,而这些问题在 Cluster 中都得到了有效的解决
redis 集群中数据是和槽(slot)挂钩的,其总共定义了 16384 个槽,所有的数据根据一致哈希算法会被映射到这 16384 个槽中的某个槽中;另一方面,这 16384 个槽是按照设置被分配到不同的 redis 节点上的
比如启动了三个 redis 实例:cluster-A,cluster-B 和 cluster-C,这里将 0-5460 号槽分配给 cluster-A,将 5461-10922 号槽分配给 cluster-B ,将 10923-16383 号槽分配给 cluster-C(总共有 16384 个槽,但是其标号类似数组下标,是从 0 到 16383 )。也就是说数据的存储只和槽有关,并且槽的数量是一定的,由于一致 hash 算法是一定的,因而将这 16384 个槽分配给无论多少个redis实例,对于确认的数据其都将被分配到确定的槽位上。redis 集群通过这种方式来达到 redis 的高效和高可用性目的
这里需要进行说明的一点是,一致哈希算法根据数据的 key 值计算映射位置时和所使用的节点数量有非常大的关系。一致哈希分区的实现思路是为系统中每个节点分配一个 token ,范围一般在 0~2^32 ,这些 token 构成一个哈希环,数据读写执行节点查找操作时,先根据 key 计算 hash 值,然后顺时针找到第一个大于等于该 hash 值的 token 节点,需要操作的数据就保存在该节点上。通过分析可以发现,一致哈希分区存在如下问题:
- 加减节点会造成哈希环中部分数据无法命中,需要手动处理或忽略这部分数据
- 当使用少量节点时,节点变化将大范围影响环中数据映射,因此这种方式不适合少量节点的分布式方案
- 普通的一致性哈希分区在增减节点时需要增加一倍或减去一半节点才能保证数据和负载的平衡
正是由于一致哈希分区的这些问题,redis 使用了虚拟槽来处理分区时节点变化的问题 ,也即将所有的数据映射到 16384 个虚拟槽位上,当 redis 节点变化时数据映射的槽位将不会变化,并且这也是 redis 进行节点扩张的基础
对于 redis 集群的配置,首先将 redis 安装目录下的 redis.conf 文件复制六份,分别取名为:cluster-6379.conf、cluster-6380.conf、cluster-6381.conf、cluster-6382.conf、cluster-6383.conf、cluster-6384.conf
对于一个高可用的集群方案,集群每个节点都将为其分配一个从节点,以防止数据节点因为故障下线,这里使用六份配置文件定义六个redis实例,其中三个作为主节点,剩余三个分别作为其从节点。对于这六份配置文件,以其中一份为例,以下是其需要修改的参数:
1
2
3
4
5
6
7
8
port 6379
cluster-enabled yes
cluster-node-timeout 15000
cluster-config-file "nodes-6379.conf"
pidfile /var/run/redis_6379.pid
logfile "cluster-6379.log"
dbfilename dump-cluster-6379.rdb
appendfilename "appendonly-cluster-6379.aof"
对于其余的配置文件,只需要将其中对应项的端口号和带有端口号的文件名修改为当前要指定的端口号和端口号的文件名即可
配置文件配置好之后使用如下命令启动集群中的每个实例:
1
2
3
4
5
6
./src/redis-server cluster-6379.conf
./src/redis-server cluster-6380.conf
./src/redis-server cluster-6381.conf
./src/redis-server cluster-6382.conf
./src/redis-server cluster-6383.conf
./src/redis-server cluster-6384.conf
上述配置文件中,当前配置和启动过程中并没有指定这六个实例的主从关系 ,也没有对16384 个槽位进行分配。因而我们还需要进行进一步的配置,槽位的分配和主从关系的设定有两种方式进行,一种是使用 redis-cli 连接到集群节点上后使用 cluster meet 命令连接其他的节点,如我们首先执行如下命令连接到 6379 端口的节点
./src/redis-cli -p 6379
连接上后使用 cluster meet 命令分别连接其余节点:
1
2
3
4
5
127.0.0.1:6379>cluster meet 127.0.0.1 6380
127.0.0.1:6379>cluster meet 127.0.0.1 6381
127.0.0.1:6379>cluster meet 127.0.0.1 6382
127.0.0.1:6379>cluster meet 127.0.0.1 6383
127.0.0.1:6379>cluster meet 127.0.0.1 6384
连接好后可以使用 cluster nodes 命令查看当前集群状态:
1
2
3
4
5
6
7
127.0.0.1:6379> cluster nodes
4fa7eac4080f0b667ffeab9b87841da49b84a6e4 127.0.0.1:6384 master - 0 1468073975551 5 connected
cfb28ef1deee4e0fa78da86abe5d24566744411e 127.0.0.1:6379 myself,master - 0 0 0 connected
be9485a6a729fc98c5151374bc30277e89a461d8 127.0.0.1:6383 master - 0 1468073978579 4 connected
40622f9e7adc8ebd77fca0de9edfe691cb8a74fb 127.0.0.1:6382 master - 0 1468073980598 3 connected
8e41673d59c9568aa9d29fb174ce733345b3e8f1 127.0.0.1:6380 master - 0 1468073974541 1 connected
40b8d09d44294d2e23c7c768efc8fcd153446746 127.0.0.1:6381 master - 0 1468073979589 2 connected
可以看到配置的六个节点都已经加入到了集群中,但是其现在还不能使用,因为还没有将 16384 个槽分配到集群节点中。虚拟槽的分配可以使用 redis-cli 分别连接到 6379, 6380 和 6381 端口的节点中,然后分别执行如下命令:
1
2
3
127.0.0.1:6379>cluster addslots {0...5461}
127.0.0.1:6380>cluster addslots {5462...10922}
127.0.0.1:6381>cluster addslots {10923...16383}
添加完槽位后可使用 cluster info 命令查看当前集群状态:
1
2
3
4
5
6
7
8
9
10
11
12
127.0.0.1:6379> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:5
cluster_my_epoch:0
cluster_stats_messages_sent:4874
cluster_stats_messages_received:4726
这里将 16384 个虚拟槽位分配给了三个节点,而剩余的三个节点通过如下命令将其配置为这三个节点的从节点,从而达到高可用的目的:
1
2
3
4
5
6
127.0.0.1:6382>cluster replicate cfb28ef1deee4e0fa78da86abe5d24566744411e
OK
127.0.0.1:6383>cluster replicate 8e41673d59c9568aa9d29fb174ce733345b3e8f1
OK
127.0.0.1:6384>cluster replicate 40b8d09d44294d2e23c7c768efc8fcd153446746
OK
如此,所有的集群节点都配置完毕,并且处于可用状态。这里可以使用 cluster nodes 命令查看当前节点的状态:
1
2
3
4
5
6
7
127.0.0.1:6379> cluster nodes
4fa7eac4080f0b667ffeab9b87841da49b84a6e4 127.0.0.1:6384 slave 40b8d09d44294d2e23c7c768efc8fcd153446746 0 1468076865939 5 connected
cfb28ef1deee4e0fa78da86abe5d24566744411e 127.0.0.1:6379 myself,master - 0 0 0 connected 0-5461
be9485a6a729fc98c5151374bc30277e89a461d8 127.0.0.1:6383 slave 8e41673d59c9568aa9d29fb174ce733345b3e8f1 0 1468076868966 4 connected
40622f9e7adc8ebd77fca0de9edfe691cb8a74fb 127.0.0.1:6382 slave cfb28ef1deee4e0fa78da86abe5d24566744411e 0 1468076869976 3 connected
8e41673d59c9568aa9d29fb174ce733345b3e8f1 127.0.0.1:6380 master - 0 1468076870987 1 connected 5462-10922
40b8d09d44294d2e23c7c768efc8fcd153446746 127.0.0.1:6381 master - 0 1468076867957 2 connected 10923-16383
使用 redis-cli 使用如下命令连接集群:
./src/redis-cli -c -p 6380
注意连接集群模式的 redis 实例时需要加上参数 -c ,表示连接的是集群模式的实例。连接上后执行 get 命令:
1
2
3
127.0.0.1:6380> get hello
-> Redirected to slot [866] located at 127.0.0.1:6379
(nil)
可以看到,在 6380 端口的实例上执行 get 命令时,其首先会为当前的键通过一致哈希算法计算其所在的槽位,并且判断该槽位不在当前 redis 实例中,因而重定向到目标实例上执行该命令,最后发现没有该键对应的值,因而返回了一个(nil)
分片插槽深度理解
16384个插槽,为了方便计算,用15000替代
3个主节点,平均分配,每个主节点负责5000个插槽
等于是把总量15G的数据,平均分配到3个主节点,每个节点5G
将Redis数据分布到不同机器上,根本目的是为了用多台普通硬件的组合,去解决单台顶级硬件也无法解决的超大容量、超高并发和高可用性问题
水平扩容,从3个主节点,升级到4个主节点,需要重新计算插槽,做数据的迁移同步
每个主节点,最好都配置从节点,这样主节点挂了后,不需要重新计算插槽,而是由从节点晋级到新的主节点,继承之前的插槽