[TOC]
RPC:一种架构模式,只要符合远程过程调用,都叫rpc。比如 openFeign 就是一种基于http实现的rpc
rpc的序列化效率更高
http超文本传输协议,如果基于http实现的rpc,一样不能摆脱http协议规范的请求头,只不过rpc会视情况压缩这部分内容
什么是RPC
RPC(Remote Procedure Call 远程过程调用) 分布式促使 RPC 诞生,RPC让分布式系统更加简单,让开发人员把精力放到业务上,并且提供高效安全的通信
它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。也就是说两台服务器 A、B,一个应用部署在 A 服务器上,想要调用 B 服务器上应用提供的方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据,就是要像调用本地的函数一样去调远程函数
RPC 只是一种通信模式,和 http 并不冲突对立,相反http可以作为RPC传输数据的一种协议,把RPC当作一种模式和思想,才能更好地理解它
RPC 一种模式策略和框架,并不是单纯的通信协议
方法调用
典型的 B/S 模型或者 C/S 模型都是客户端要调用服务端接口来获取数据和结果,这种属于外部调用
区别于外部调用,内部系统随着业务规模的扩大,出现了分布式和微服务,简单说就是把一个庞大的业务拆分成很多子服务,并且每个子服务都部署在很多独立分布的机器上,从而形成一个庞大的内部系统
本地调用
假设调用函数 Multiply 来计算 lvalue * rvalue 的结果:
1
2
3
4
5
6
7
8
int Multiply(int l, int r) {
int y = l * r;
return y;
}
int lvalue = 10;
int rvalue = 20;
int l_times_r = Multiply(lvalue, rvalue);
这是非常普通的本地函数调用,因为在同一个地址空间,或者说在同一块内存,所以通过方法栈和参数栈就可以实现
远程调用
当系统改造为分布式应用时,将很多可以共享的功能都单独抽出来,放到一个服务中,让别的服务去调用
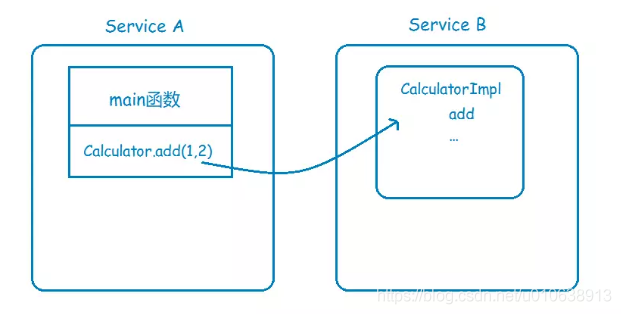
但是 service A 中并没有 Service B 的 CalculatorImpl 实现类
- 可以模仿 B/S 架构的调用方式,在 Service B 中暴露一个 Restful 接口,然后 Service A 通过调用 Restful 接口间接的调用 CalculatorImpl 实现类的 add 方法
上述方法接近RPC,但如果是这样,那么每次调用时,都需要写以穿发起 http 请求的代码( httpClient.sendRequest )
而 RPC 远程过程调用需要像本地调用一样,去发起远程调用,让使用者感知不到远程调用的过程
- 代理模式,通过 Spring 注入 Calculator 对象,注入时,如果扫描到对象加了 @Reference 注解,那么久生成一个代理对象,将这个代理对象放进容器中。在代理对象的内部,就是通过 httpClient 来实现 RPC 远程过程调用
上述方法就是很多 RPC 框架要解决的问题和解决思路,比如 Dubbo
在本地调用时需要有:
- 确定的类或函数
- 类或函数的参数
- 类或函数的返回值
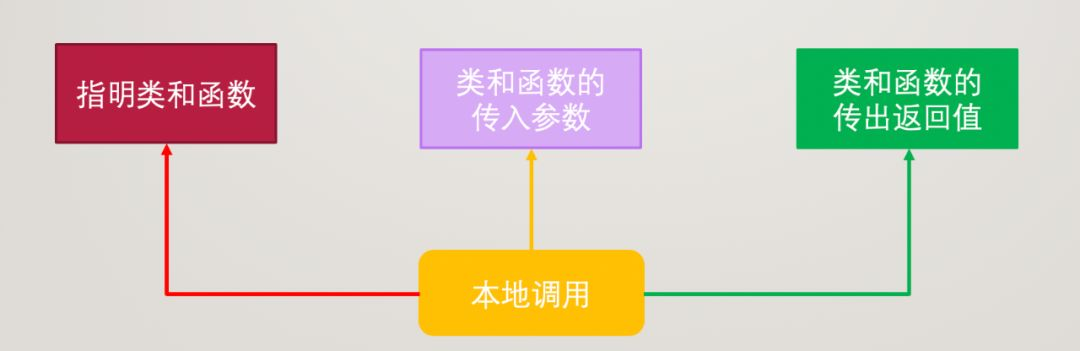
远程调用肯定也不会缺少这三要素,唯一的区别在于这三要素是要被传输过去的,这其中就涉及协议编码和解码的过程
Service A 需要通过网络传输来告诉 Service B,它想要 add 函数,传入的两个参数分别是 3 和 5 ,返回的结果放在 result 里面就可以
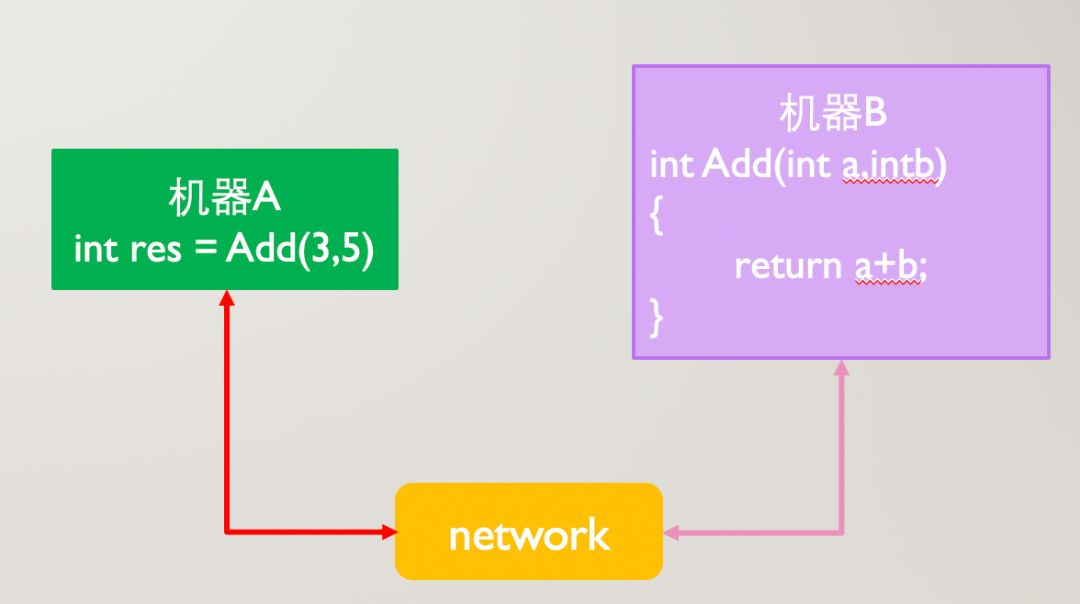
传输的报文里面按照约定的协议格式给出了函数名和参数,大致这样:
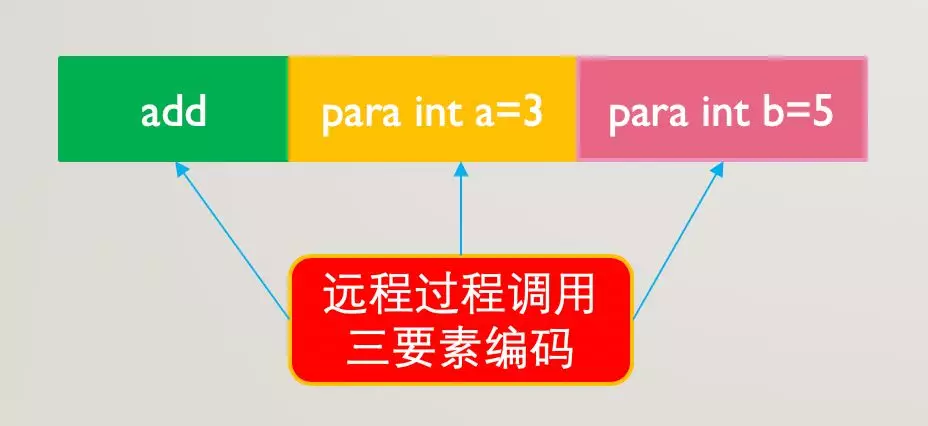
上述的编码只是一种举例不代表实际应用,为了提高传输效率可以进行二进制编码(只有二进制数据才能在网络中传输)
总结: RPC需要解决的两个问题:
- 解决分布式系统中,服务之间的调用问题
- 远程调用时,要能够像本地调用一样方便,让调用者感知不到远程调用的逻辑
如何实现一个RPC
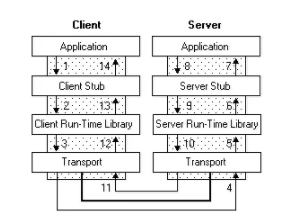
以左边的 Client 端为例,Application就是 RPC 的调用方,Client Stub 就是我们上面说到的代理对象,也就是那个看起来像是 Calculator 的实现类,其实内部是通过 RPC 方式来进行远程调用的代理对象,至于 Client Run-time Library,则是实现远程调用的工具包,比如 JDK 的 Socket,最后通过底层网络实现实现数据的传输
这个过程中最重要的就是序列化和反序列化了,因为数据传输的数据包必须是二进制的,直接丢一个Java对象过去,对方不认识,必须把 Java 对象序列化为二进制格式,传给Server端,Server端接收到之后,再反序列化为 Java 对象
http 好比普通话, RPC 好比团队内部黑话 讲普通话,好处就是谁都能听得懂,谁都会讲 讲黑话,好处是可以更精简、更加保密、更加可定制,坏处是要求说黑话的另一方( Client 端)也要懂
RPC 的核心功能主要由 5 个模块 (客户端、客户端 Stub、网络传输模块、服务端 Stub、服务端) 组成,如果想要自己实现一个 RPC,最简单的方式要实现三个技术点,分别是:
- 服务寻址
- 数据流的序列化和反序列化
- 网络传输
服务寻址:
服务寻址可以使用 Call ID 映射。在本地调用中,函数体是直接通过函数指针来指定的,但是在远程调用中,函数指针是不行的,因为两个进程的地址空间是完全不一样的(不同机器)
所以在 RPC 中,所有的函数都必须有自己的一个 ID。这个 ID 在所有进程中都是唯一确定的
客户端在做远程过程调用时,必须附上这个 ID。然后我们还需要在客户端和服务端分别维护一个函数和 Call ID 的对应表
当客户端需要进行远程调用时,它就查一下这个表,找出相应的 Call ID,然后把它传给服务端,服务端也通过查表,来确定客户端需要调用的函数,然后执行相应函数的代码
实现方式:服务注册中心,要调用服务,首先需要一个服务注册中心去查询对方服务都有哪些实例。Dubbo 的服务注册中心是可以配置的,官方推荐使用 Zookeeper
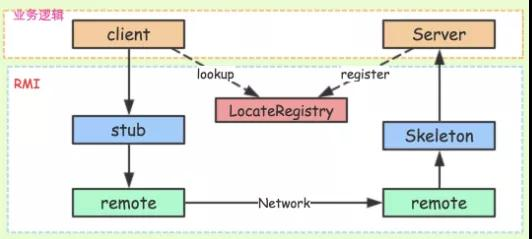
实现案例:RMI ( Remote Method Invocation,远程方法调用 ) 也就是 RPC 本身的实现方式
-
Registry(服务发现):借助 JNDI 发布并调用了 RMI 服务。实际上,JNDI 就是一个注册表,服务端将服务对象放入到注册表中,客户端从注册表中获取服务对象
-
RMI 服务在服务端实现之后需要注册到 RMI Server 上,然后客户端从指定的 RMI 地址上 Lookup 服务,调用该服务对应的方法即可完成远程方法调用
-
Registry 是个很重要的功能,当服务端开发完服务之后,要对外暴露,如果没有服务注册,则客户端是无从调用的,即使服务端的服务就在那里
数据流的序列化和反序列化:
本地调用中,只需要把参数压到栈里,然后让函数自己去栈里读就行
但是在远程过程调用时,客户端跟服务端是不同的进程,不能通过内存来传递参数
这时候就需要客户端把参数先转成一个字节流,传给服务端后,再把字节流转成自己能读取的格式,从服务端返回的值也需要序列化反序列化的过程
只有二进制数据才能在网络中传输
- 将对象转换成二进制流的过程叫做序列化
- 将二进制流转换成对象的过程叫做反序列化
网络传输
网络传输:远程调用往往用在网络上,客户端和服务端是通过网络连接的
所有的数据都需要通过网络传输,因此就需要有一个网络传输层。网络传输层需要把 Call ID 和序列化后的参数字节流传给服务端,然后再把序列化后的调用结果传回客户端
只要能完成这两者的,都可以作为传输层使用。因此,它所使用的协议其实是不限的,能完成传输就行
大部分 RPC 框架都使用 TCP 协议,但其实 UDP 也可以,而 gRPC 干脆就用了 HTTP2
所以,要实现一个 RPC 框架,只需要把以下三点实现了就基本完成了:
- Call ID 映射:可以直接使用函数字符串,也可以使用整数 ID。映射表一般就是一个哈希表。
- 序列化反序列化:可以自己写,也可以使用 Protobuf 或者 FlatBuffers 之类的。
- 网络传输库:可以自己写 Socket,或者用 Asio,ZeroMQ,Netty 之类
RPC代码实现可参考知乎柳树
完整的 RPC 框架
RPC是一种内部服务框架,可以涉及服务注册、服务治理、服务发现、熔断机制、负载均衡等,其中“RPC 协议”就指明了程序如何进行网络传输和序列化
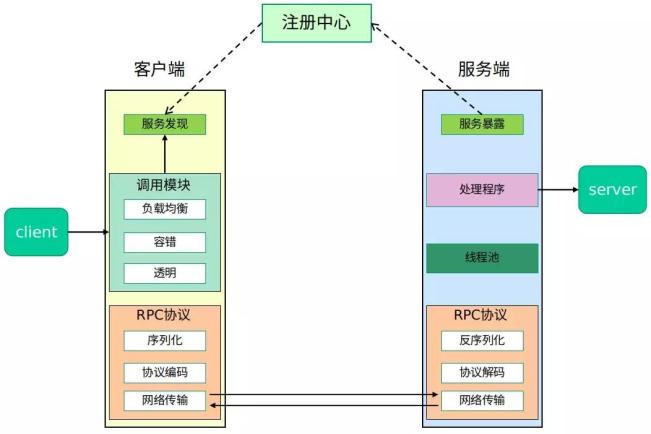
RPC协议模块是很重要的部分,这部分也是前面提到的 Service A 调用 Service B 时传输报文的过程

一个 RPC 的核心功能主要有 5 个部分组成,分别是:客户端、客户端 Stub、网络传输模块、服务端 Stub、服务端等
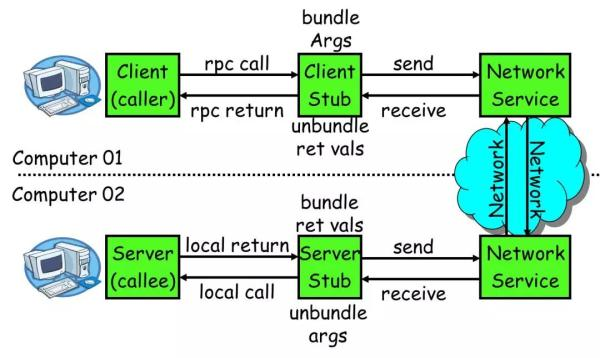
- 客户端( Client ):服务调用方
- 客户端存根( Client Stub ):存放服务端地址信息,将客户端的请求参数数据信息打包成网络消息,再通过网络传输发送给服务端
- 服务端存根( Server Stub ):接收客户端发送过来的请求消息并进行解包,然后再调用本地服务进行处理
- 服务端(Server):服务的真正提供者
- Network Service:底层传输,可以是 TCP 或 HTTP
在网络消息传输中可以基于 TCP、UDP、http 来实现,各自都有各自的特点:
TCP:
基于 TCP 实现的 RPC 调用,能够灵活对协议字段进行定制,减少网络开销高性能,实现更大的吞吐量和并发数,但要关注底层细节,在进行数据解析时加复杂一些
由服务的调用方与服务的提供方建立 Socket 连接,并由服务的调用方通过 Socket 将需要调用的接口名称、方法名称和参数序列化后传递给服务的提供方,服务的提供方反序列化后再利用反射调用相关的方法
但是在实例应用中则会进行一系列的封装,如 RMI 便是在 TCP 协议上传递可序列化的 Java 对象
TCP 连接可以是按需连接(需要调用的时候就先建立连接,调用束后就立马断掉),也可以是长连接(客户端和服务器建立起连接之后保持长期有,不管此时有无数据包的发送,可以配合心跳检测机制定期检测建立的连接否存活有效),多个远程过程调用共享同一个连接
HTTP:
该方法更像是访问网页一样,只是它的返回结果更加单一简单
基于 HTTP 实现的 RPC 可以使用 JSON 和 XML 格式的请求或响应数据,解工具很成熟,在其上进行二次开发会非常便捷和简单。但是 HTTP 是上层议,所占用的字节数会比使用 TCP 协议传输所占用的字节数更高
由服务的调用者向服务的提供者发送请求,这种请求的方式可能是 GET、POST、PUT、DELETE 等中的一种,服务的提供者可能会根据不同的请求方式做出不同的处理,或者某个方法只允许某种请求方式
而调用的具体方法则是根据 URL 进行方法调用,而方法所需要的参数可能是对服务调用方传输过去的 XML 数据或者 JSON 数据解析后的结果,***返回 JOSN 或者 XML 的数据结果
由于目前有很多开源的 Web 服务器,如 Tomcat,所以其实现起来更加容易,就像做 Web 项目一样
RPC Vs Restful
两者并不是一个维度的概念,总得来说RPC涉及的维度更广
可以从 url 风格上进行比较
1
2
3
4
5
/queryOrder?orderId=123 // RPC
Get请求
/order?orderId=123 // Restful
/order/123 // Restful
RPC是面向过程,Restful是面向资源,并且使用了Http动词。从这个维度上看,Restful风格的url在表述的精简性、可读性上都要更好
既然有 HTTP 请求,为什么还要用 RPC 调用
HTTP协议,以其中的Restful规范为代表,其优势很大。它可读性好,且可以得到防火墙的支持、跨语言的支持。但是HTTP也有其缺点,这是与其优点相对应的。首先是有用信息占比少,毕竟HTTP工作在第七层,包含了大量的HTTP头等信息。其次是效率低,还是因为第七层的缘故。还有,其可读性似乎没有必要,因为我们可以引入网关增加可读性。此外,使用HTTP协议调用远程方法比较复杂,要封装各种参数名和参数值
而RPC则与HTTP互补
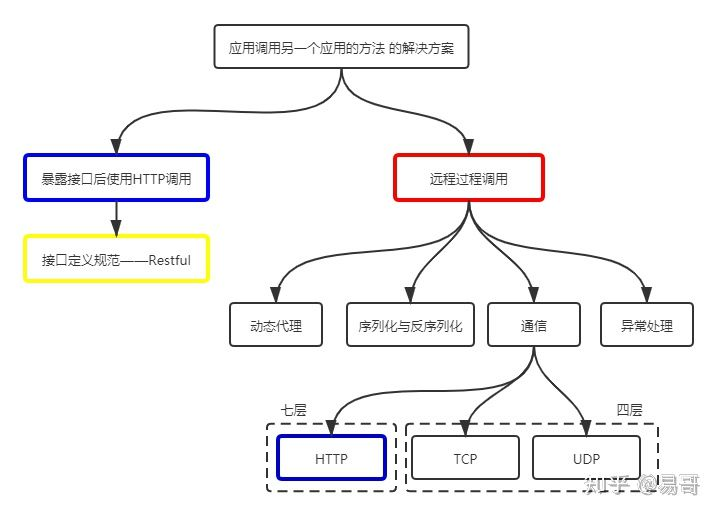
HTTP(图中蓝色框)出现了两次。其中一个是和RPC并列的,都是跨应用调用方法的解决方案;另一个则是被RPC包含的,是RPC通信过程的可选协议之一
标题的问题在于和 RPC 并列的比较
分布式系统中,因为每个服务的边界都很小,很有可能调用别的服务提供的方法。这就出现了 Service A 调用 Service B 中方法的需求,即远程过程调用
要想让 Service A 调用 Service B 中的方法,最先想到的就是通过HTTP请求实现。这是很常见的,例如 Service B 暴露 Restful 接口,然后让 Service A 调用它的接口。基于 Restful 的调用方式因为可读性好( Service B暴露出的是 Restful 接口,可读性当然好)而且 HTTP 请求可以通过各种防火墙,因此非常不错
然而,如前面所述,基于Restful的远程过程调用有着明显的缺点,主要是效率低、封装调用复杂。当存在大量的服务间调用时,这些缺点变得更为突出
Service A 调用 Service B 的过程是应用间的内部过程,牺牲可读性提升效率、易用性是可取的。基于这种思路,RPC 产生了
通常,RPC要求在调用方中放置被调用的方法的接口。调用方只要调用了这些接口,就相当于调用了被调用方的实际方法,十分易用。于是,调用方可以像调用内部接口一样调用远程的方法,而不用封装参数名和参数值等操作
要实现像调用内部接口一样调用远程的方法:
- 首先,调用方调用的是接口,必须得为接口构造一个假的实现。显然,要使用动态代理。这样,调用方的调用就被动态代理接收到了
-
第二,动态代理接收到调用后,应该想办法调用远程的实际实现。这包括下面几步:
- 识别具体要调用的远程方法的IP、端口
- 将调用方法的入参进行序列化
- 通过通信将请求发送到远程的方法中
-
远程的服务就接收到了调用方的请求。它应该:
- 反序列化各个调用参数
- 定位到实际要调用的方法,然后输入参数,执行方法
- 按照调用的路径返回调用的结果
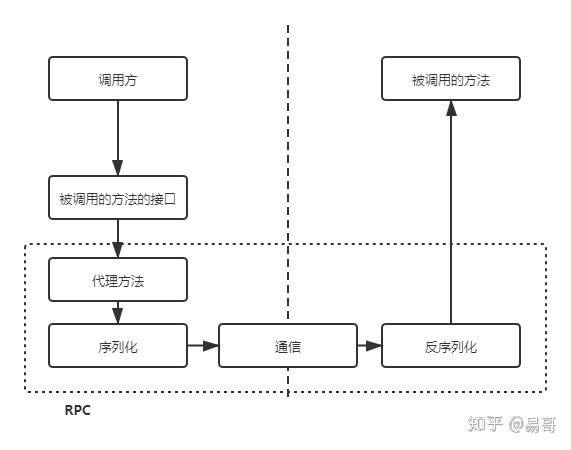
调用方调用内部的一个方法,但是被 RPC 框架偷梁换柱为远程的一个方法。之间的通信数据可读性不需要好,只需要 RPC 框架能读懂即可,因此效率可以更高。通常使用 UDP 或者 TCP 作为通讯协议,也可以使用 HTTP
简单RPC实现参考git 作者 Developer Yee
总结:
两者各有千秋。本质上,两者是可读性和效率之间的抉择,通用性和易用性之间的抉择。根据业务场景选择使用哪一种